В Python существуют различные способы разделить строку на части, однако один из наиболее распространенных случаев – это разделение по фиксированному количеству символов. Задача может возникнуть в разных сценариях: при обработке текстовых данных, парсинге или передаче данных по сети. Разделение строки по количеству символов позволяет удобно и эффективно работать с большими объемами текста или данными, в которых важно соблюдать фиксированные размеры блоков.
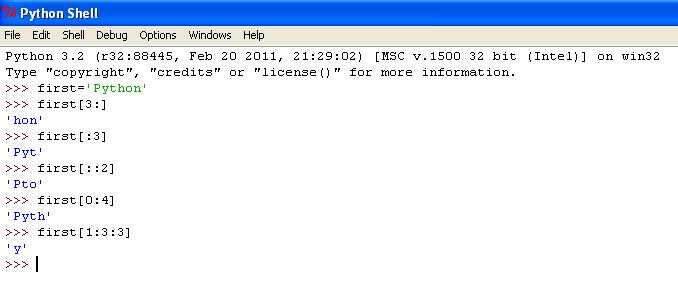
Один из самых простых и быстрых методов разделения строки на части – использование срезов. В Python это достигается с помощью индексации. С помощью оператора среза можно разделить строку на подстроки, каждая из которых будет иметь заданную длину. Такой подход идеально подходит для строк фиксированной длины, но в случае с переменной длиной строки потребуется дополнительная обработка.
Рекомендация: Если вам нужно разделить строку на части одинаковой длины, то используйте цикл с шагом, равным длине части. Это обеспечит легкость и читаемость кода. Для работы с остаточными символами (если длина строки не кратна размеру частей) можно использовать дополнительные проверки или методы, такие как textwrap.wrap().
Важно: при разбиении строк с разным количеством символов в каждой части рекомендуется учитывать возможные изменения в длине исходной строки. Некоторые методы могут не учитывать остаточные символы, что может привести к потере данных. В таких случаях рекомендуется использовать библиотеки для работы с текстом, такие как textwrap, которые автоматически обрабатывают разбиение с учётом этих особенностей.
Как разделить строку на части по количеству символов в Python
Если необходимо разбить строку на равные части, можно воспользоваться следующим подходом:
def split_string_by_length(s, length):
return [s[i:i+length] for i in range(0, len(s), length)]
В данном примере функция split_string_by_length принимает строку и длину каждой части. С помощью срезов она делит строку на подстроки указанной длины, начиная с каждого индекса, кратного length.
Для примера с текстом «Приветмир» и длиной частей 3, результат будет следующим:
split_string_by_length("Приветмир", 3)
Этот способ удобен и работает для любых строк. Если строка не делится на части без остатка, последняя часть будет короче остальных. Для обработки таких случаев можно добавить дополнительную логику, например, заполняя недостающие символы пробелами или другими символами.
Вместо явного цикла можно использовать модуль textwrap, который предоставляет удобную функцию wrap для разделения строки на строки фиксированной длины.
import textwrap
textwrap.wrap("Приветмир", 3)
Этот метод аналогичен предыдущему, но код становится компактнее и читабельнее.
В зависимости от задачи, можно использовать различные подходы, каждый из которых имеет свои преимущества. Важно выбирать метод, который наиболее подходит для конкретной ситуации.
Разбиение строки на фиксированные части с помощью срезов

Для разбиения строки на фиксированные части в Python можно использовать срезы. Срезы позволяют извлечь подстроки из исходной строки, указав начальный и конечный индексы. Чтобы разбить строку на равные части, можно использовать цикл с шагом, соответствующим размеру этих частей.
Пример базового разбиения строки на части по 3 символа:
s = "abcdefghi" part_size = 3 parts = [s[i:i+part_size] for i in range(0, len(s), part_size)] print(parts)
Этот код разбивает строку «abcdefghi» на части длиной по 3 символа. Результат: [‘abc’, ‘def’, ‘ghi’]. При этом, если длина строки не кратна размеру части, последняя часть может быть короче.
Чтобы избежать пустых частей или некорректных данных, важно учитывать длину строки и размер части. Например, если строка состоит из 8 символов, а размер части 3, последняя подстрока будет содержать только 2 символа. Для контроля можно добавить проверку, чтобы исключить короткие остаточные части или обрабатывать их по-своему.
Еще один способ – использование генератора для динамичного создания подстрок. Это позволяет не хранить все части в памяти сразу, что полезно при работе с большими строками:
def split_string(s, part_size): for i in range(0, len(s), part_size): yield s[i:i+part_size] s = "abcdefghijklmno" parts = list(split_string(s, 4)) print(parts)
В данном примере функция split_string возвращает части строки по 4 символа, и результат будет следующим: [‘abcd’, ‘efgh’, ‘ijkl’, ‘mnop’]. Этот метод эффективен при работе с большими данными, так как позволяет обрабатывать данные по мере необходимости, не создавая большие временные структуры.
Разбиение срезами идеально подходит для работы с фиксированными размерами блоков, что позволяет легко манипулировать строками в различных задачах, таких как анализ данных, обработка текстов и другие операции, требующие разделения на части.
Использование функции `textwrap.wrap` для разделения строки
Основное применение `wrap` заключается в разбиении строки на блоки определенной длины. Например, если нужно разделить текст так, чтобы каждая строка не превышала определенной длины (например, 50 символов), функция автоматически вставит переносы, обеспечивая нужный формат.
Пример использования:
import textwrap
text = "Этот пример демонстрирует использование функции wrap для разбиения строки."
wrapped_text = textwrap.wrap(text, width=20)
print(wrapped_text)
Результат выполнения кода:
['Этот пример демонстрирует', 'использование функции wrap', 'для разбиения строки.']
Каждый элемент в списке, возвращаемом функцией `wrap`, является строкой, которая не превышает указанной длины. Важно отметить, что разбиение происходит по пробелам, если они присутствуют в нужных местах, без разрыва слов. Это гарантирует, что фразы будут читабельными и логичными.
Помимо обычного использования, функция позволяет дополнительно настроить поведение с помощью параметров:
expand_tabs: если установлено вTrue, табуляции будут заменяться на пробелы;replace_whitespace: позволяет заменить все пробельные символы на одиночные пробелы;drop_whitespace: игнорирует пробелы в начале и конце строки;initial_indentиsubsequent_indent: позволяют добавить отступы перед первой и последующими строками, что полезно при форматировании текста с абзацами.
Пример с отступами:
text = "Это пример текста с отступами перед строками."
wrapped_text = textwrap.wrap(text, width=20, initial_indent="* ", subsequent_indent=" ")
for line in wrapped_text:
print(line)
Результат:
* Это пример текста
с отступами перед
строками.
Функция `textwrap.wrap` предоставляет мощный инструмент для удобного форматирования строк, позволяя адаптировать их под различные ограничения по длине и улучшать читаемость текста.
Разбиение строки на части при помощи регулярных выражений
Регулярные выражения в Python могут эффективно разделить строку на части, соответствующие заданным паттернам. Встроенный модуль re предоставляет функции для поиска и извлечения данных из строк с помощью шаблонов.
Для разбиения строки на части можно использовать функцию re.findall(), которая возвращает все неперекрывающиеся совпадения с заданным регулярным выражением. Например, если нужно разделить строку на части по 3 символа, можно использовать регулярное выражение ‘.{3}’, которое будет искать группы из трех любых символов.
Пример:
import re
string = "abcdefghi"
result = re.findall(r'.{3}', string)
print(result) # ['abc', 'def', 'ghi']
В этом примере строка «abcdefghi» разбивается на три части: «abc», «def» и «ghi».
Регулярные выражения позволяют гибко настраивать разбиение. Например, для разделения строки по 4 символа можно использовать выражение ‘.{4}’, а для игнорирования пробелов или других символов – более сложные шаблоны с условиями.
Когда требуется делить строку с учетом определенного шаблона, например, разбить строку на части, состоящие из букв и цифр, можно использовать регулярное выражение с группами, например \w+ для поиска непрерывных буквенно-цифровых последовательностей.
Пример разбиения на слова и числа:
import re string = "abc123 def456 ghi789" result = re.findall(r'\w+', string) print(result) # ['abc123', 'def456', 'ghi789']
Регулярные выражения также позволяют использовать опции для более сложных разделений, например, при необходимости учесть только те части строки, которые не содержат пробелов или других символов. Для этого можно комбинировать паттерны с условиями, такими как \S+ (все, кроме пробела).
Использование регулярных выражений для разделения строк – мощный инструмент, особенно если требуется более сложная логика, чем просто разбиение по фиксированному числу символов. Этот метод позволяет настроить поиск под любые нужды, исключая избыточные символы или разделяя по условиям, не описанным в стандартных методах работы со строками.
Как обработать строку разной длины при разбиении

Когда необходимо разделить строку на части одинаковой длины, могут возникать ситуации, когда длина строки не кратна размеру части. В таких случаях важно учитывать несколько факторов, чтобы обработать строку корректно.
Если длина строки не делится нацело на количество символов в части, остается «хвост» – последние символы, которые не помещаются в полную часть. Чтобы эффективно обработать такие случаи, можно использовать различные подходы:
1. Добавление символов для выравнивания. Один из вариантов – дополнить строку необходимым количеством символов (например, пробелами или другими символами) до желаемой длины. Это обеспечит равномерное разделение строки. Используя метод ljust(), можно дополнить строку до нужной длины. Например:
text = "Python" length = 4 text_padded = text.ljust(((len(text) + length - 1) // length) * length) print(text_padded) # "Python "
2. Игнорирование остаточных символов. Если последние символы строки не важны, их можно просто игнорировать. Для этого можно округлить длину строки до ближайшего меньшего числа, которое кратно размеру части. Например, при разбиении строки длиной 11 на части по 4 символа, можно использовать 8 символов, отбросив остаток:
text = "Python rocks" length = 4 text_truncated = text[:(len(text) // length) * length] print(text_truncated) # "Python ro"
3. Обработка «хвоста» отдельно. Можно оставить остаток в виде отдельной части, если это необходимо для дальнейшей работы с ним. Например, если строка делится на части по 3 символа, а остаток составляет 2 символа, этот остаток можно обработать отдельно:
text = "Python" length = 3 parts = [text[i:i+length] for i in range(0, len(text), length)] print(parts) # ['Pyt', 'hon']
В случае с разделением строки разной длины важно учитывать не только саму логику разбиения, но и специфику задачи, что поможет выбрать наиболее подходящий метод обработки остатка или дополнения строки.
Разбиение строки на несколько частей с сохранением пробелов
При разбиении строки на части с сохранением пробелов важно учесть, что пробелы не должны теряться или изменять свое местоположение относительно текста. Для этого в Python можно использовать различные методы, начиная с базовых функций и заканчивая более сложными подходами. Рассмотрим несколько вариантов, как можно эффективно решать эту задачу.
Для начала, одна из самых простых и эффективных техник – это использование регулярных выражений. Регулярные выражения позволяют разделить строку так, чтобы пробелы оставались внутри каждой части или между ними, если этого требует задача.
Пример с использованием регулярных выражений:
import re
def split_with_spaces(text, length):
return re.findall(f'.{{1,{length}}}(?:\\s|$)', text)
Этот код разделяет строку на подстроки, учитывая пробелы между словами. Параметр `length` указывает максимальную длину каждой части строки. Таким образом, пробелы будут сохраняться и не будут «поглощаться» при разбиении строки.
Другой подход заключается в использовании метода split() для предварительного разделения строки по пробелам, а затем объединения элементов с учётом желаемой длины:
def split_by_length(text, length):
words = text.split(' ')
result = []
part = ''
for word in words:
if len(part + ' ' + word) <= length:
part += ' ' + word if part else word
else:
result.append(part)
part = word
if part:
result.append(part)
return result
Этот способ позволяет сохранить пробелы между словами, объединяя их в части, длина которых не превышает заданное значение.
Для более точного контроля за позиционированием пробелов можно использовать комбинацию методов re.sub и re.split. Например, можно заменить пробелы на маркеры, а затем при разбиении восстанавливать их в нужных местах.
Важно помнить, что в случае разбиения строки с сохранением пробелов могут возникнуть некоторые проблемы с производительностью, особенно если строка большая. В таких случаях полезно использовать более оптимизированные подходы с учётом особенностей конкретной задачи.
Основные рекомендации:
- Используйте регулярные выражения для гибкости и точности.
- Разделение по пробелам и манипуляция с полученными частями позволяет избежать потери данных.
- Для больших строк оптимизируйте решение, избегая ненужных преобразований.
Оптимизация разбиения строки при работе с большими данными

При работе с большими объемами данных важно минимизировать время обработки и использовать ресурсы системы с максимальной эффективностью. В контексте разбиения строк это особенно актуально, так как стандартные методы могут оказаться медленными или неоптимальными для масштабных задач.
Один из основных способов улучшить производительность – использование генераторов. В отличие от обычных функций, они позволяют избегать создания больших промежуточных объектов в памяти, что критично при работе с большими строками. Например, вместо создания списка всех подстрок, можно использовать генератор, который будет возвращать подстроки по одному за раз. Это особенно полезно, когда необходимо обработать данные на лету, не загружая их целиком в память.
Другим эффективным методом является использование библиотеки NumPy, которая оптимизирована для работы с массивами данных. Если строка содержит лишь символы одного типа (например, только цифры или только буквы), можно преобразовать строку в массив NumPy и быстро разделить его на части. Это позволит использовать высокопроизводительные операции над большими массивами данных, значительно ускоряя процесс разбиения.
Для разбиения строк по фиксированному количеству символов также можно применить регулярные выражения. Однако важно помнить, что для очень больших строк стандартные регулярные выражения могут быть менее производительными, чем специализированные подходы. Использование функций из библиотеки re может быть эффективным, если правильно настроить регулярное выражение, минимизируя количество ненужных операций.
Оптимизация разбиения строки также включает использование многозадачности и асинхронных вычислений. Если задача требует разделения и обработки нескольких больших строк, разделение работы на несколько потоков или процессов может значительно ускорить выполнение. Использование многозадачности позволяет уменьшить время ожидания и ускорить обработку данных, распределяя вычисления по ядрам процессора.
Наконец, для уменьшения накладных расходов на разбиение строки важно избегать ненужных преобразований данных. Например, если строка заранее разделена на части, а затем нужно лишь собрать ее обратно, лучше использовать метод join, который быстрее, чем последовательное добавление элементов в строку.
Как объединить части строки после разбиения
После того как строка была разделена на части, часто возникает необходимость объединить эти части обратно. В Python это можно сделать несколькими способами, в зависимости от требований задачи. Рассмотрим наиболее эффективные методы.
Самый популярный и простой способ объединения частей строки – использовать метод join(). Этот метод принимает список или другой итерируемый объект и соединяет его элементы с указанным разделителем.
- Пример использования
join():
chunks = ['Hello', 'world', 'Python']
result = ' '.join(chunks)
print(result) # Выведет: Hello world PythonВ данном примере части строки соединяются с пробелом между ними. Вы можете использовать любой символ в качестве разделителя, например, запятую или дефис.
- Пример с дефисом в качестве разделителя:
result = '-'.join(chunks)
print(result) # Выведет: Hello-world-PythonЕсли нужно объединить строки без какого-либо разделителя, просто передайте пустую строку в качестве аргумента:
result = ''.join(chunks)
print(result) # Выведет: HelloworldPythonЕще один способ объединения частей строки – использовать цикл. Однако метод join() является более предпочтительным с точки зрения производительности, так как он оптимизирован для работы с большими объемами данных.
- Пример с использованием цикла:
result = ''
for chunk in chunks:
result += chunk
print(result) # Выведет: HelloworldPythonЭтот способ менее эффективен, так как при каждом добавлении нового элемента создается новая строка, что занимает больше времени и памяти по сравнению с join().
В случае, если части строки содержат дополнительные пробелы или спецсимволы, перед объединением можно применить метод strip() для их удаления.
- Пример использования
strip():
chunks = [' Hello ', ' world ', ' Python ']
result = ' '.join(chunk.strip() for chunk in chunks)
print(result) # Выведет: Hello world PythonЭтот подход полезен, если необходимо очистить строки перед объединением.
Примеры использования разбиения строки для обработки текстовых данных

При обработке текстовых данных часто возникает задача разделить строку на более мелкие части, чтобы извлечь информацию или преобразовать текст в удобный формат. В Python можно использовать различные методы для разбиения строки по количеству символов, что полезно в различных сценариях.
1. Разбиение текста на фиксированные блоки
Если нужно разделить строку на блоки фиксированной длины, можно использовать срезы. Например, для строки с текстом, где каждый блок должен содержать 10 символов:
text = "Данный текст нужно разбить на блоки"
block_size = 10
chunks = [text[i:i+block_size] for i in range(0, len(text), block_size)]
В этом примере список chunks будет содержать текст, разбитый на части по 10 символов. Такой метод подходит для обработки данных в фиксированном формате, например, для работы с большими текстами или логами.
2. Извлечение информации из текста
Если требуется извлечь данные из строки, где информация имеет определенную структуру, разделенную фиксированным количеством символов, можно использовать разбиение. Например, для строки, содержащей коды и параметры:
code = "123456789012345678901234"
parameters = [code[i:i+6] for i in range(0, len(code), 6)]
В результате, каждый элемент списка parameters будет содержать подстроку длиной 6 символов. Этот метод часто используется для обработки кодов или серийных номеров.
3. Обработка строк с динамичной длиной
Если строки имеют переменную длину, но нужно разбить их на части с минимальной длиной, можно комбинировать методы с условиями. Например, для строки, где длина блоков может варьироваться в зависимости от содержимого:
text = "Разбиение строки по разному"
min_length = 5
chunks = []
while len(text) > min_length:
chunks.append(text[:min_length])
text = text[min_length:]
chunks.append(text) # добавление остаточной части
Этот подход полезен, когда необходимо учитывать минимальный размер блока, но также важно обработать остаток строки.
4. Парсинг данных с разделителями
Иногда текст необходимо разделить по определенному разделителю, например, пробелу или запятой. Для таких случаев подойдут методы, которые поддерживают регулярные выражения или стандартное разделение строки. Например:
text = "имя_параметр1,имя_параметр2,имя_параметр3"
parameters = text.split(',')
В данном случае, parameters будет содержать список, разделенный по запятой. Этот метод подходит для работы с текстом, где данные структурированы разделителями.
5. Разбиение на основе условий
Когда необходимо делить строку по условиям, можно использовать регулярные выражения. Например, разбиение строки на слова, где слово – это последовательность букв или цифр:
import re
text = "Это пример строки 1234 с цифрами и словами"
words = re.findall(r'\w+', text)
Используя регулярное выражение \w+, можно выделить все слова и числа, что полезно при извлечении информации из текстовых документов.