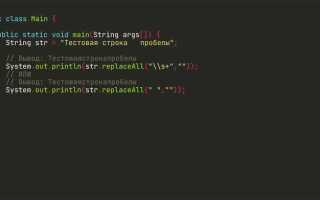
Работа со строками в Java часто требует точных манипуляций: извлечения, замены или удаления отдельных фрагментов текста. Удаление слова из строки – одна из базовых, но при этом потенциально ошибкоопасных операций, особенно при учёте регистра, границ слов и символов-разделителей.
Для удаления слова можно использовать метод replaceAll() класса String с регулярным выражением. Например, выражение "\\bслово\\b" позволяет удалить только точное совпадение слова, игнорируя его части внутри других слов. Это особенно важно при обработке пользовательского ввода или текстов с непредсказуемой структурой.
Если требуется чувствительность к регистру, следует явно указать это в шаблоне или использовать метод Pattern.compile() с нужным флагом. Кроме того, после удаления слова нередко остаются лишние пробелы – их можно устранить с помощью дополнительного вызова trim() или регулярного выражения вроде "\\s{2,}".
При необходимости массовой обработки строк (например, в коллекциях) стоит использовать Stream API и комбинировать операции фильтрации и трансформации. Такой подход повышает читаемость и производительность кода при работе с большими объёмами данных.
Как удалить одно конкретное слово из строки с учетом регистра
Для удаления слова из строки с учетом регистра используйте метод replace или регулярные выражения. Если важно сохранить регистр символов, не применяйте toLowerCase() или toUpperCase(), так как они изменят исходные данные.
Пример с использованием метода replace:
String input = "Java – мощный язык. java – не то же самое, что Java.";
String result = input.replace("Java", "");
System.out.println(result);Этот код удалит только те вхождения слова «Java», которые полностью совпадают по регистру. Слово «java» останется нетронутым.
Если нужно удалить слово, стоящее отдельно, и не затронуть подстроки, используйте регулярное выражение с границами слова:
String input = "Язык Java – это Java. Но java – это другое.";
String result = input.replaceAll("\\bJava\\b", "");
System.out.println(result);Регулярное выражение \\bJava\\b гарантирует, что будет удалено только отдельное слово «Java», не являющееся частью других слов. Регистр сохраняется, так как флаг CASE_INSENSITIVE не применяется.
Для удаления нескольких отдельных вхождений одного слова, оберните удаление в цикл или используйте метод replaceAll один раз, как показано выше – он удалит все совпадения по шаблону.
После удаления может остаться лишний пробел. Для очистки строки от лишних пробелов используйте:
result = result.replaceAll("\\s{2,}", " ").trim();Это удалит двойные пробелы и обрежет пробелы по краям строки.
Удаление всех вхождений слова без учета регистра
Для удаления всех вхождений слова из строки без учета регистра следует использовать регулярные выражения с флагом CASE_INSENSITIVE. Это позволяет находить совпадения независимо от регистра символов.
Пример реализации на Java:
import java.util.regex.Pattern;
public class TextCleaner {
public static String removeWordIgnoreCase(String input, String word) {
String regex = "\\b" + Pattern.quote(word) + "\\b";
return Pattern.compile(regex, Pattern.CASE_INSENSITIVE)
.matcher(input)
.replaceAll("");
}
public static void main(String[] args) {
String text = "Пример текста с Словом, словом и СЛОВОМ в разных регистрах.";
String result = removeWordIgnoreCase(text, "слово");
System.out.println(result.trim().replaceAll(" +", " "));
}
}
Рекомендации:
1. Используйте \\b для обозначения границ слова, чтобы не удалить части других слов.
2. Метод Pattern.quote() защищает от специальных символов в слове-аргументе.
3. После удаления возможны лишние пробелы – их нужно устранить с помощью replaceAll(» +», » «) и trim().
Такой подход обеспечивает точное удаление всех форм слова вне зависимости от регистра, без повреждения других частей текста.
Удаление слова только в начале или в конце строки
Для удаления слова в начале строки используется метод String.replaceFirst() с регулярным выражением. Важно учесть границу слова и возможные пробелы:
String input = "Удалить это слово в начале";
String result = input.replaceFirst("^Удалить\\s*", "");
Регулярное выражение ^Удалить\\s* гарантирует, что будет удалено только слово «Удалить», если оно стоит первым и может сопровождаться пробелами.
Для удаления слова в конце строки применяется replaceFirst() с другим выражением:
String input = "Это слово нужно удалить";
String result = input.replaceFirst("\\s*удалить$", "");
Здесь \\s*удалить$ удаляет слово «удалить» в конце строки вместе с возможными пробелами перед ним.
Рекомендации:
- Учитывайте регистр: метод по умолчанию чувствителен к регистру. Для игнорирования используйте
Pattern.compile(..., Pattern.CASE_INSENSITIVE). - Не используйте
replaceAll()без нужды – он работает по всей строке и приведёт к удалению слова вне начала/конца. - Если строка может содержать символы пунктуации после слова, учитывайте это в регулярном выражении, например:
\\bУдалить[\\p{Punct}\\s]*$.
Удаление строго в начале или в конце требует точного соответствия, иначе результат может быть непредсказуемым, особенно при наличии пробелов и спецсимволов.
Как удалить слово, если оно окружено пробелами или знаками препинания
Для удаления слова, окружённого пробелами или знаками препинания, следует использовать регулярные выражения, позволяющие точно идентифицировать границы слова в тексте. Ключевой момент – учёт возможных символов до и после слова, включая пробелы, запятые, точки, двоеточия и другие знаки.
Используйте метод replaceAll() с шаблоном, охватывающим все допустимые окружения. Пример: str.replaceAll("(?i)(?<=^|[\\s\\p$)", ""). Здесь (?i) делает поиск нечувствительным к регистру, (?<=^]) проверяет наличие пробела, знака пунктуации или начала строки перед словом, а (?=[\\s\\p{Punct}]|$) – после слова.
После замены возможны лишние пробелы. Для их удаления примените trim() и дополнительную нормализацию: str.replaceAll("\\s{2,}", " "). Это устранит двойные пробелы, оставшиеся после удаления.
Такой подход сохраняет структуру предложения и не затрагивает слова, содержащие целевое в качестве подстроки, например, «подслово» не будет удалено при поиске «слово».
Удаление слова с использованием регулярных выражений
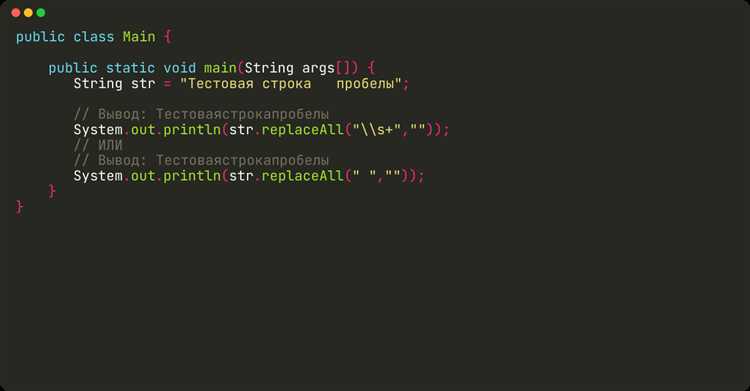
Регулярные выражения в Java позволяют точно находить и удалять слова из строки, учитывая границы слов и возможные вариации регистра. Это особенно полезно, когда необходимо исключить слово независимо от его позиции и соседних символов.
Для удаления слова используется метод String.replaceAll() с регулярным выражением, обеспечивающим корректное совпадение только целого слова:
String input = "Пример текста с удаляемым словом и другим словом.";
String output = input.replaceAll("\\bслово\\b", "");
\\b– метасимвол, обозначающий границу слова. Гарантирует, что будут удалены только полные совпадения, а не подстроки других слов.- Результат: слово удаляется без затрагивания других частей текста.
Если нужно удалить слово без учёта регистра, следует использовать модификатор (?i):
String output = input.replaceAll("(?i)\\bСлово\\b", "");
(?i)– включает режим нечувствительности к регистру прямо в шаблоне.
Чтобы удалить несколько разных слов одновременно, объедините их через вертикальную черту | и оберните в скобки:
String output = input.replaceAll("\\b(слово1|слово2|слово3)\\b", "");
- Скобки группируют альтернативы,
|задаёт варианты слов. - Каждое слово удаляется, если встречается как самостоятельная лексема.
После удаления могут остаться лишние пробелы. Их можно очистить дополнительной заменой:
output = output.replaceAll("\\s{2,}", " ").trim();
\\s{2,}– находит два и более пробела подряд.trim()– удаляет пробелы в начале и конце строки.
Разница между методами replace, replaceAll и replaceFirst
Методы replace, replaceAll и replaceFirst в Java предназначены для замены символов или подстрок в строках, но работают по-разному в зависимости от типа аргументов и поведения.
replace выполняет замену всех вхождений заданного символа или подстроки на новое значение. В отличие от других методов, он работает только с обычными строками или символами, без использования регулярных выражений. Это делает его простым и быстрым для замены фиксированных значений, но менее гибким для работы с более сложными паттернами.
replaceAll использует регулярные выражения для поиска и замены всех вхождений, соответствующих заданному паттерну. Этот метод может быть более мощным, но из-за работы с регулярными выражениями он часто медленнее, чем replace. Его следует использовать, если нужно заменить по шаблону, который не ограничивается простыми символами или строками.
replaceFirst схож с replaceAll, но выполняет замену только первого вхождения, которое соответствует регулярному выражению. Этот метод полезен, когда требуется заменить только одно вхождение, а не все возможные.
При выборе метода нужно учитывать тип заменяемых данных. Если требуется замена фиксированных символов или строк, предпочтительнее использовать replace, так как он более эффективен. Если необходима замена по регулярному выражению, replaceAll или replaceFirst подойдут, в зависимости от того, нужно ли заменять одно или все вхождения.
Обработка строки с множеством удаляемых слов
Когда требуется удалить несколько слов из строки, можно использовать регулярные выражения или последовательное применение метода replace(). Важно учитывать, что каждое удаляемое слово должно быть обработано эффективно, чтобы не возникло лишних операций и потерь производительности.
Для удаления нескольких слов из строки часто используется регулярное выражение. Например, можно составить паттерн, который будет учитывать все слова, подлежащие удалению, и заменить их на пустую строку.
Пример:
String input = "Этот текст содержит несколько слов, которые нужно удалить";
String[] wordsToRemove = {"текст", "несколько", "удалить"};
String regex = String.join("|", wordsToRemove);
String result = input.replaceAll("\\b(" + regex + ")\\b", "").replaceAll("\\s{2,}", " ").trim();
В данном примере слова "текст", "несколько" и "удалить" будут удалены из строки. Использование \\b в регулярном выражении гарантирует, что удаляются только полные слова, а не их части. После этого лишние пробелы между словами сжимаются с помощью \\s{2,}.
Если набор слов для удаления может изменяться динамически, это решение останется гибким и эффективным, поскольку паттерн строится из массива слов, что позволяет легко добавлять или удалять слова в процессе работы программы.
Для больших объемов данных и высоких требований к производительности можно дополнительно использовать StringBuilder и манипулировать строкой по частям, однако регулярные выражения для большинства задач по удалению слов будут достаточно быстрыми.