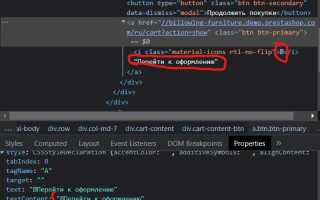
Извлечение текста из тегов Java может быть полезным при разработке различных приложений, например, для парсинга HTML-кода или анализа данных. Существует несколько подходов для этого, и каждый из них имеет свои особенности. Рассмотрим несколько эффективных способов извлечения текста с использованием популярных библиотек и инструментов Java.
Использование библиотеки JSoup – один из самых популярных методов для парсинга HTML в Java. JSoup предоставляет удобный API для работы с документами HTML, позволяя легко извлекать текст из тегов. Для извлечения текста достаточно использовать метод text(), который извлекает текст внутри тега, игнорируя HTML-разметку. Например:
String text = doc.select("p").text();
Этот код вернёт строку «Пример текста». Такой подход позволяет быстро и эффективно извлекать текст из любых элементов HTML-документа.
Использование регулярных выражений – альтернативный способ извлечения текста. Хотя этот метод не так удобен и может быть более подвержен ошибкам при сложных структурах, он всё же применим для простых случаев. Регулярные выражения позволяют искать текст внутри HTML-тегов, но важно помнить о возможных ошибках при разборе вложенных тегов.
Библиотека HTMLCleaner тоже предоставляет средства для извлечения текста из тегов, особенно в тех случаях, когда HTML-код имеет проблемы с валидностью. Эта библиотека использует XML-парсинг для исправления ошибок в структуре и помогает получать чистый текст из HTML-документов.
Выбор метода зависит от сложности задачи и структуры данных. Для большинства случаев использование JSoup является наилучшим вариантом, так как это решение достаточно гибкое и хорошо документированное.
Как извлечь текст из тегов Java

Для извлечения текста из HTML-тегов в Java наиболее часто используется библиотека Jsoup. Она предоставляет удобный API для парсинга HTML-документов и извлечения данных, включая текстовое содержимое внутри тегов.
Пример использования Jsoup для извлечения текста из тега HTML:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class ExtractText {
public static void main(String[] args) {
String html = "<html><body><p>Пример текста</p></body></html>";
Document doc = Jsoup.parse(html);
Element pTag = doc.select("p").first(); // Извлекаем первый тег <p>
String text = pTag.text(); // Получаем текст
}
}
1. Подключение Jsoup:
Для начала нужно добавить Jsoup в проект. В случае использования Maven, добавьте следующую зависимость в файл pom.xml:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
2. Парсинг документа:
Метод Jsoup.parse() позволяет загружать и анализировать HTML-код, создавая объект Document. Это позволяет работать с DOM-деревом документа и извлекать данные из любых элементов. Чтобы получить текст внутри конкретного тега, используйте метод text() на выбранном элементе.
3. Использование CSS-селекторов:
Jsoup поддерживает CSS-селекторы для выбора элементов. Например, можно выбрать все теги <p> с помощью doc.select("p"), или конкретный тег, например doc.select("p#myParagraph") для поиска по ID.
4. Преимущества использования Jsoup:
Jsoup автоматически исправляет ошибки в HTML-разметке, что делает его удобным для работы с неидеальными или плохо сформированными документами. Также он поддерживает извлечение текста без HTML-тегов, что важно при обработке контента с веб-страниц.
5. Альтернативы:
Для простых задач также можно использовать регулярные выражения, но такой подход менее эффективен и подвержен ошибкам при сложной разметке. Jsoup является лучшим выбором для работы с веб-контентом в Java.
Использование библиотеки Jsoup для парсинга HTML
Для начала работы с Jsoup необходимо добавить зависимость в проект. Это можно сделать, подключив библиотеку через Maven или Gradle. В Maven добавляется следующий код в файл pom.xml:
org.jsoup jsoup 1.15.3
После добавления зависимости можно начать использовать библиотеку. Для парсинга HTML-кода достаточно передать строку или URL в метод Jsoup.parse(), который создаст DOM-объект. Например:
Для извлечения текста из определенных тегов используется метод text(). Этот метод извлекает весь текст, включая вложенные элементы, из выбранного тега. Например, чтобы получить текст из тега <p>:
String text = doc.select("p").text();
Jsoup поддерживает мощный CSS-селектор для выбора элементов. Для фильтрации элементов можно использовать методы select() и get(), которые позволяют работать с элементами по классу, id или другим атрибутам. Например, чтобы извлечь текст из тега <p class="intro">:
String introText = doc.select("p.intro").text();
Кроме того, Jsoup позволяет работать с аттрибутами тегов. Для этого используется метод attr(). Если необходимо извлечь значение атрибута, например, ссылку из тега <a href="...">, можно сделать это так:
String link = doc.select("a").attr("href");
Парсинг HTML с помощью Jsoup также позволяет легко изменять структуру документа. Например, для замены текста в определенном элементе можно использовать метод text() в сочетании с методами изменения содержимого:
doc.select("p.intro").text("New text content");
Для сложных операций с HTML, таких как извлечение данных с динамических страниц или работа с документами, загружаемыми через JavaScript, Jsoup не подходит. В таких случаях лучше использовать библиотеки, такие как Selenium, которые могут работать с браузером. Однако для статических и простых HTML-документов Jsoup остается отличным выбором благодаря своей простоте и высокой производительности.
Как выбрать нужный элемент с помощью CSS-селекторов
Для выбора элементов на веб-странице с помощью CSS-селекторов важно понимать, как правильно использовать различные типы селекторов для точного извлечения нужных данных.
- Селекторы по тегу – самые простые. Они выбирают все элементы с указанным тегом. Например,
pвыберет все абзацы на странице. - Селекторы по классу позволяют выбрать все элементы с конкретным классом. Для этого используется точка перед именем класса. Например,
.exampleвыберет все элементы с классом «example». - Селекторы по идентификатору (ID) выбирают уникальные элементы на странице. Идентификатор указывается через решетку. Например,
#headerвыберет элемент с id=»header». - Комбинированные селекторы позволяют уточнять выборку. Например,
div.exampleвыберет все элементы с классом «example» внутриdiv. Это помогает исключить ненужные элементы. - Селекторы атрибутов позволяют выбирать элементы по значениям атрибутов. Например,
[href="https://example.com"]выберет все ссылки с указанным значением атрибута href.
Для более точной работы с элементами можно использовать псевдоклассы и псевдоэлементы. Например, :first-child выбирает первый дочерний элемент, а ::after позволяет добавлять контент после элемента.
:nth-child(n)– выбор элементов по порядковому номеру. Например,li:nth-child(2)выберет второй элемент списка.:last-child– выбирает последний элемент в контейнере.:not(selector)– исключает элементы, соответствующие указанному селектору.
Использование правильных селекторов помогает точно выбрать нужные элементы и ускоряет процесс работы с данными на странице. Подбирайте селекторы в зависимости от структуры документа, избегая чрезмерных вложенностей и избыточных правил.
Извлечение текста из тегов с атрибутами
Рассмотрим основные шаги извлечения текста с учётом атрибутов:
- Использование CSS-селекторов: При помощи JSoup можно найти элементы, которые соответствуют определённым атрибутам. Пример использования CSS-селектора для поиска элементов с атрибутом class:
Elements elements = doc.select("[class=myClass]");- Поиск по конкретным атрибутам: Например, если необходимо извлечь текст из тегов, имеющих атрибут data-id, можно использовать следующий код:
Elements elements = doc.select("[data-id]");После нахождения элементов, их текст извлекается следующим образом:
for (Element element : elements) {
String text = element.text();
System.out.println(text);
}Пример извлечения текста из тегов с несколькими атрибутами:
Elements elements = doc.select("[class=myClass][data-id=123]");Также можно использовать фильтрацию на основе значений атрибутов:
Elements elements = doc.select("[href^=http]");Этот селектор выберет все ссылки, атрибут href которых начинается с «http».
Важно отметить, что при извлечении текста из элементов с атрибутами стоит быть внимательным к пустым или отсутствующим атрибутам, чтобы избежать ошибок в процессе парсинга.
- Рекомендации:
- Используйте конкретные селекторы для поиска по атрибутам, чтобы ускорить процесс извлечения.
- Если элементы содержат вложенные теги, используйте метод
element.text(), чтобы получить текст без HTML-разметки. - Для извлечения атрибутов используйте метод
element.attr("название_атрибута").
Этот подход позволяет гибко извлекать текст в зависимости от заданных атрибутов и специфики структуры документа.
Работа с вложенными тегами: как получить текст из всех уровней

Когда HTML-документ имеет сложную структуру с несколькими уровнями вложенных элементов, например, списки, параграфы или дивы внутри других дивов, важно правильно настроить парсер для обработки всех этих элементов. В Jsoup для этого используется метод select(), который позволяет выбирать элементы по CSS-селекторам. Также можно использовать метод text(), который извлекает весь текст из выбранных элементов, включая текст из всех вложенных тегов.
Пример: чтобы получить весь текст из всех уровней вложенности внутри определённого тега, можно использовать следующий код:
Document doc = Jsoup.connect("https://example.com").get();
String text = doc.select("div.container").text(); // Извлекает весь текст внутри тега с классом container
System.out.println(text);
Важным моментом является то, что метод text() не только извлекает текст, но и автоматически обрабатывает вложенные элементы. Это означает, что если внутри div.container находятся параграфы, списки или другие блоки, то их текст будет включён в результат.
Если необходимо извлечь текст из элементов на разных уровнях вложенности и обработать его по-разному, можно комбинировать методы выбора элементов с фильтрацией. Например, если нужно получить текст только из первого уровня вложенности, а затем отдельно обработать текст из более глубоких уровней, можно использовать метод children(), который возвращает дочерние элементы текущего элемента:
Element div = doc.select("div.container").first();
for (Element child : div.children()) {
}
Для более сложных структур, где вложенные теги могут быть перемешаны, полезно использовать комбинированные селекторы и фильтрацию с помощью методов select() и text(). Также можно использовать регулярные выражения для дополнительной фильтрации текста, если нужно извлечь только те строки, которые соответствуют определённому паттерну.
Таким образом, работа с вложенными тегами в Java требует гибкости в подходах. Чёткое понимание структуры HTML-документа и использование возможностей библиотеки Jsoup для обхода всех уровней вложенности позволяет эффективно извлекать текст из любых уровней вложенных элементов.
Обработка ошибок при парсинге HTML в Java
При парсинге HTML в Java важную роль играет правильная обработка ошибок, поскольку структура HTML может быть неполной или поврежденной. Для этого чаще всего используются библиотеки, такие как Jsoup, которые предоставляют удобные средства для работы с ошибками и нестандартными структурами HTML.
Первое, на что стоит обратить внимание – это некорректный или неполный HTML. Jsoup, например, автоматически исправляет многие ошибки в структуре документа, что позволяет избежать исключений. Однако, если HTML очень сильно поврежден, это может привести к неверному парсингу данных. В таких случаях рекомендуется использовать дополнительные проверки на валидность документа перед его обработкой.
Важно предусмотреть обработку ситуаций, когда HTML-документ не удается загрузить или прочитать. Это может быть связано с отсутствием интернета, недоступностью источника или некорректным URL. Для этих случаев следует использовать исключения, такие как IOException или MalformedURLException, которые помогут корректно обработать ошибку и не прервать выполнение программы.
Ошибки парсинга могут возникать из-за неверных данных, передаваемых в парсер. Например, если HTML документ пуст или содержит только текст, а не полноценную структуру с тегами, это вызовет исключение. Для таких случаев важно предусмотреть проверку на наличие данных перед началом парсинга и обработку случаев с пустыми или некорректными данными с помощью условий и логики программы.
Кроме того, при извлечении данных из тегов важно учитывать возможность отсутствия нужных элементов в структуре HTML. Это может произойти, если веб-страница обновилась или структура изменена. В таких случаях рекомендуется использовать методы для безопасного поиска элементов, такие как select() или getElementsByTag(), которые возвращают пустой список, если элемент не найден, вместо того, чтобы выбрасывать исключение.
При работе с динамическим контентом (например, при парсинге страниц с JavaScript) может возникнуть необходимость использовать дополнительные инструменты, такие как Selenium, для загрузки страницы с последующей обработкой ее HTML. Ошибки в таких случаях могут быть связаны с таймингом загрузки элементов или их отсутствием в DOM. Для предотвращения этих проблем рекомендуется использовать явные ожидания (например, WebDriverWait в Selenium), чтобы убедиться в наличии всех нужных элементов перед их извлечением.
В случае обработки ошибок в парсинге HTML важно также учитывать возможность столкновения с элементами, которые могут быть изменены или удалены на сервере. Для этого стоит реализовать стратегию обработки изменений структуры HTML, включая логирование и обработку нестандартных случаев, чтобы программа могла адаптироваться к изменениям на целевых страницах.
Как извлечь текст из таблиц и списков с помощью Jsoup
Для начала необходимо загрузить HTML-документ с помощью Jsoup:
Document doc = Jsoup.connect("URL_страницы").get();
Затем, чтобы извлечь текст из таблицы, можно использовать селекторы CSS. Например, для получения всех строк таблицы:
Elements rows = doc.select("table tr");
Каждый элемент tr представляет строку таблицы. Для получения текста всех ячеек в строке можно пройтись по ячейкам <td>:
for (Element row : rows) {
Elements cols = row.select("td");
for (Element col : cols) {
System.out.println(col.text());
}
}
Этот код перебирает каждую строку таблицы, а затем в каждой строке извлекает текст из всех ячеек. Важно помнить, что текст будет извлечен без HTML-разметки, только видимый текст.
Для работы со списками ситуация аналогична. Чтобы получить все элементы списка, нужно использовать следующий код:
Elements listItems = doc.select("ul li");
Если список упорядоченный, используйте тег <ol> вместо <ul>. Текст каждого элемента списка можно извлечь так:
for (Element li : listItems) {
System.out.println(li.text());
}
Этот код извлекает текст всех элементов списка, не включая HTML-структуру. Для более точного извлечения информации можно использовать фильтрацию по классу или id:
Elements rows = doc.select("table#myTable tr");
Таким образом, с помощью Jsoup можно легко извлекать текст из таблиц и списков, что полезно при парсинге различных структурированных данных с веб-страниц.
Пример кода для извлечения текста из HTML-файла

Для извлечения текста из HTML-документа можно использовать библиотеку Jsoup. Это простое и эффективное решение для парсинга HTML и работы с его содержимым. Ниже представлен пример кода, который позволяет извлечь текст из HTML-файла.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class ExtractTextExample {
public static void main(String[] args) {
try {
// Загрузка HTML-файла
File inputFile = new File("example.html");
Document document = Jsoup.parse(inputFile, "UTF-8");
// Извлечение текста из тега body
String text = document.body().text();
System.out.println("Текст из body: " + text);
// Извлечение текста из конкретного тега
Element header = document.select("h1").first();
if (header != null) {
System.out.println("Текст из h1: " + header.text());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
В этом примере используется метод Jsoup.parse() для загрузки HTML-файла. После этого можно извлечь текст из различных частей документа. Метод body().text() возвращает весь текст, который находится внутри тега body.
Если необходимо извлечь текст из определённого элемента, например, из тега h1, используется метод select(), который позволяет выбрать элемент по CSS-селектору. Важно помнить, что метод first() возвращает только первый найденный элемент.
Этот подход применим для извлечения текста как из локальных HTML-файлов, так и с веб-страниц, что позволяет эффективно обрабатывать различные типы данных.
Вопрос-ответ:
Почему извлечение текста с помощью Java может быть сложным?
Извлечение текста из HTML в Java может быть сложным из-за множества факторов, таких как необходимость учитывать различные структуры документов, динамическое изменение контента (например, через JavaScript), проблемы с кодировкой символов, а также наличие вложенных или скомплексированных тегов. Поэтому важно выбрать правильный инструмент для конкретной задачи. Для простых задач подойдёт Jsoup, а для более сложных операций, например, с JavaScript-генерируемыми данными, стоит использовать HtmlUnit или Selenium.
Можно ли извлечь текст из HTML-документа без использования внешних библиотек?
Да, можно извлечь текст из HTML-документа, не используя внешние библиотеки, но такой подход потребует большего количества кода. Например, вы можете использовать стандартные средства работы с XML и регулярные выражения для парсинга HTML, однако этот метод может быть менее эффективным и надёжным, особенно при наличии сложных или динамических HTML-структур. Лучше всего всё же использовать такие библиотеки, как Jsoup, которые уже оптимизированы для работы с HTML.
 (пока оценок нет)
(пока оценок нет)
 Загрузка...
Поделиться с друзьями:
Твитнуть
Поделиться
Поделиться
Отправить
Класснуть
Загрузка...
Поделиться с друзьями:
Твитнуть
Поделиться
Поделиться
Отправить
Класснуть