SQL (Structured Query Language) представляет собой стандартный язык для работы с реляционными базами данных. Он используется для создания, модификации и извлечения данных, а также для управления структурой базы данных. Несмотря на развитие альтернативных технологий хранения данных, SQL продолжает оставаться основным инструментом в профессиональной сфере разработки и администрирования баз данных.
Одной из ключевых особенностей SQL является его способность эффективно обрабатывать большие объемы данных. Операции, такие как SELECT, INSERT, UPDATE и DELETE, позволяют быстро и гибко взаимодействовать с таблицами. Например, использование индексов и оптимизация запросов могут значительно повысить производительность даже при работе с миллионами записей. Важно, чтобы разработчик умел правильно проектировать запросы и использовать функции SQL для минимизации времени отклика.
Важным аспектом при работе с SQL является нормализация базы данных, которая помогает избежать избыточности данных и улучшить их целостность. Применение нормальных форм (например, первая и вторая нормальная форма) гарантирует, что данные будут правильно структурированы и легко обновляемы, что снижает вероятность возникновения ошибок в процессе работы.
Кроме того, SQL активно используется для выполнения сложных аналитических запросов. Функции агрегации, такие как COUNT, AVG, SUM, позволяют получать сводные данные, необходимые для принятия обоснованных бизнес-решений. Применение операций объединения таблиц (JOIN) помогает анализировать данные из разных источников, что значительно расширяет возможности запросов.
Как построить запросы SELECT для извлечения данных из таблиц
Запрос SELECT используется для извлечения данных из одной или нескольких таблиц базы данных. Он позволяет фильтровать, сортировать и агрегировать информацию, что важно для получения нужных данных в оптимальном виде.
Основные компоненты запроса SELECT:
- SELECT – указывает, какие столбцы необходимо выбрать.
- FROM – указывает таблицу, из которой извлекаются данные.
- WHERE – задает условия фильтрации данных.
- ORDER BY – используется для сортировки данных.
- LIMIT – ограничивает количество возвращаемых строк.
Пример базового запроса:
SELECT имя, возраст FROM сотрудники;
Для более сложных запросов можно использовать условия, сортировку и ограничения:
SELECT имя, должность, зарплата FROM сотрудники WHERE возраст > 30 ORDER BY зарплата DESC LIMIT 10;
Рассмотрим более подробно каждую часть запроса.
Выбор столбцов
После команды SELECT указываются столбцы, которые нужно извлечь. Если требуется выбрать все столбцы, используется звездочка (*):
SELECT * FROM сотрудники;
Фильтрация данных
Условие WHERE позволяет ограничить выборку. Оно может включать операторы сравнения (>, <, =, !=) и логические операторы (AND, OR):
SELECT имя, зарплата FROM сотрудники WHERE возраст >= 25 AND должность = 'Менеджер';
Сортировка результатов
С помощью ORDER BY можно отсортировать результаты по одному или нескольким столбцам. По умолчанию сортировка идет по возрастанию. Для сортировки по убыванию используется DESC:
SELECT имя, зарплата FROM сотрудники ORDER BY зарплата DESC;
Ограничение количества результатов
SELECT имя, должность FROM сотрудники LIMIT 5;
Использование агрегатных функций
Для анализа данных часто используются агрегатные функции, такие как COUNT, SUM, AVG, MAX и MIN. Они позволяют подсчитывать количество записей, находить среднее значение, максимум или минимум:
SELECT COUNT(*) FROM сотрудники WHERE возраст > 30;
Группировка данных

Функция GROUP BY используется для группировки данных по одному или нескольким столбцам. Это полезно при применении агрегатных функций:
SELECT должность, AVG(зарплата) FROM сотрудники GROUP BY должность;
Объединение таблиц
Для работы с данными из нескольких таблиц используется операция JOIN. Она позволяет объединить таблицы по общим столбцам. В SQL существует несколько типов JOIN: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN. Например:
SELECT сотрудники.имя, отделы.название FROM сотрудники INNER JOIN отделы ON сотрудники.отдел_id = отделы.id;
Используя эти техники, можно строить запросы SELECT, которые эффективно извлекают нужные данные из базы данных в зависимости от требований.
Использование JOIN для объединения данных из нескольких таблиц
Оператор JOIN в SQL позволяет объединять данные из двух и более таблиц, используя связи между ними. Он основан на принципе сопоставления значений в определённых столбцах. Для этого используется ключевое слово JOIN, которое применяется в различных вариантах в зависимости от условий объединения.
Наиболее часто встречаемые типы JOIN:
- INNER JOIN – возвращает только те строки, которые имеют совпадения в обеих таблицах.
- LEFT JOIN (или LEFT OUTER JOIN) – включает все строки из левой таблицы и те, что имеют совпадения в правой таблице. Если совпадений нет, значения в столбцах правой таблицы будут NULL.
- RIGHT JOIN (или RIGHT OUTER JOIN) – аналогично LEFT JOIN, но с приоритетом для правой таблицы.
- FULL JOIN (или FULL OUTER JOIN) – включает все строки из обеих таблиц, заполняя NULL там, где нет совпадений.
Пример использования INNER JOIN: предположим, что есть две таблицы: «employees» (сотрудники) и «departments» (отделы). Если необходимо получить список сотрудников вместе с названиями их отделов, запрос будет выглядеть так:
SELECT employees.name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id;
Этот запрос вернёт только те строки, где у сотрудника есть соответствующий отдел, и исключит тех сотрудников, у которых нет отдела.
SELECT employees.name, departments.department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id;
В этом случае будут включены все сотрудники, а для тех, кто не имеет назначенного отдела, в колонке department_name будет стоять NULL.
RIGHT JOIN работает по аналогии, но результат будет включать все строки из правой таблицы. Это может быть полезно, например, при поиске всех отделов с указанием сотрудников, если таковые имеются. Для полного объединения данных из обеих таблиц используется FULL JOIN, где учитываются все строки из обеих таблиц, заполняя пропущенные значения NULL.
Важно помнить, что использование JOIN может негативно сказаться на производительности, особенно при объединении больших таблиц. В таких случаях рекомендуется оптимизировать запросы, используя индексы на столбцах, участвующих в объединении, а также фильтрацию данных с помощью WHERE до применения JOIN, чтобы минимизировать объём обрабатываемых данных.
Оптимизация SQL-запросов с помощью индексов
Индексы в SQL позволяют существенно ускорить выполнение запросов за счет минимизации времени поиска нужных данных. Они обеспечивают быстрый доступ к строкам таблицы, что особенно важно при работе с большими объемами информации. Однако правильная настройка индексов требует учета специфики данных и типов запросов.
Типы индексов
Основные типы индексов включают B-tree, Hash, Full-text и Spatial индексы. Для большинства запросов, которые используют операторы сравнения (=, BETWEEN, LIKE), оптимальным выбором является индекс типа B-tree. Для точного поиска по уникальным ключам эффективны Hash-индексы. Full-text индексы применяются для поиска по текстовым данным, а Spatial индексы – для географических запросов.
Когда использовать индексы
Индексы необходимы, когда запросы часто выполняются с условиями фильтрации (WHERE), сортировки (ORDER BY) или соединениями (JOIN). Они особенно эффективны при обращении к большим таблицам, где поиск без индекса может занять значительное время.
Выбор колонок для индексирования
Колонки, которые часто участвуют в условиях поиска, сортировки или соединения, должны быть проиндексированы. Однако индексирование каждой колонки не всегда оправдано, так как это может негативно сказаться на производительности при вставке, обновлении или удалении данных. Рекомендуется индексировать только те поля, которые используются в запросах более 10% времени.
Многостолбцовые индексы
Когда запросы используют несколько колонок в фильтре, эффективным решением будет создание многостолбцового индекса. Однако важно учитывать порядок колонок в индексе: первым должно идти поле, которое чаще всего используется для поиска или сортировки. Неправильный порядок может снизить эффективность индекса.
Обновление индексов
Индексы требуют обновления при изменении данных в таблице. Это увеличивает время выполнения операций вставки, обновления и удаления, поэтому индексы следует применять осмотрительно. Для таблиц с редкими изменениями данных и частыми запросами индексы значительно ускорят работу. Однако для таблиц с интенсивными изменениями следует тщательно анализировать, какие индексы действительно необходимы.
Удаление неиспользуемых индексов
Наличие избыточных индексов может замедлить производительность базы данных. Регулярное использование инструментов анализа, таких как EXPLAIN в MySQL или EXPLAIN ANALYZE в PostgreSQL, помогает выявить неэффективные индексы, которые не используются в запросах и только увеличивают нагрузку на систему.
Проблемы с индексацией
Одной из проблем при использовании индексов является их неправильное использование в сложных запросах, например, в запросах с подзапросами или объединениями, где индекс может не быть применен. В таких случаях стоит проанализировать запросы и, при необходимости, оптимизировать их структуру или изменить схему индексации.
В целом, индексы являются мощным инструментом для ускорения работы с базами данных, но для их эффективного использования необходимо учитывать как типы данных, так и особенности запросов. Правильный выбор и настройка индексов могут значительно повысить производительность SQL-запросов в больших системах.
Как работать с подзапросами в SQL
Подзапросы в SQL позволяют выполнять вложенные запросы внутри основного запроса. Это мощный инструмент для решения сложных задач, когда нужно получить данные, которые могут зависеть от других данных в той же или другой таблице. Основное преимущество подзапросов – возможность избежать временных таблиц или дополнительных операций с данными вне SQL-запроса.
Подзапросы могут быть использованы в различных частях SQL-запроса: в SELECT, WHERE, FROM и других. Важно понимать, как правильно выбирать тип подзапроса в зависимости от задачи.
Подзапросы бывают двух типов: коррелируемые и некоррелируемые. Некоррелируемый подзапрос не зависит от внешнего запроса, он выполняется один раз и возвращает результат, который используется в основном запросе. Коррелируемый подзапрос же зависит от данных внешнего запроса, и для каждой строки основного запроса выполняется свой подзапрос.
Пример некоррелируемого подзапроса:
SELECT name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
Этот запрос вернет всех сотрудников с зарплатой выше средней. Подзапрос в скобках выполняется один раз и используется для сравнения.
Пример коррелируемого подзапроса:
SELECT e.name FROM employees e WHERE e.salary > (SELECT AVG(salary) FROM employees WHERE department_id = e.department_id);
Здесь подзапрос зависит от значения department_id внешнего запроса, то есть для каждого сотрудника вычисляется средняя зарплата по его отделу.
Использование подзапросов в WHERE – это часто встречаемая практика. Подзапрос может быть использован для фильтрации данных, например, для нахождения всех записей, связанных с максимальными или минимальными значениями:
SELECT product_name FROM products WHERE price = (SELECT MAX(price) FROM products);
Этот запрос вернет название самого дорогого продукта в базе.
Подзапросы также могут быть использованы в операторе IN, что позволяет работать с множественными значениями:
SELECT employee_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location = 'New York');
Этот запрос найдет всех сотрудников, работающих в отделах, расположенных в Нью-Йорке.
Использование подзапросов в операторе FROM позволяет создавать временные таблицы прямо в запросе:
SELECT department_id, AVG(salary) AS avg_salary FROM (SELECT department_id, salary FROM employees WHERE salary > 50000) AS high_paid_employees GROUP BY department_id;
Этот запрос сначала выбирает сотрудников с зарплатой выше 50 000, затем вычисляет среднюю зарплату по каждому отделу среди этих сотрудников.
При работе с подзапросами следует учитывать несколько важных аспектов. Во-первых, производительность может снижаться при использовании коррелируемых подзапросов, так как они выполняются для каждой строки внешнего запроса. Во-вторых, подзапросы в SQL лучше использовать, когда не удается решить задачу с помощью простых объединений или соединений таблиц.
Наконец, важно помнить, что не все системы управления базами данных одинаково эффективно оптимизируют подзапросы. В некоторых случаях может быть полезно переписать подзапрос как соединение (JOIN), что улучшит производительность.
Использование агрегатных функций для анализа данных

Агрегатные функции в SQL применяются для вычисления итоговых значений по набору данных. Они позволяют эффективно обрабатывать большие объемы информации и извлекать из них ключевые показатели. В SQL выделяют несколько популярных агрегатных функций, каждая из которых выполняет специфическую роль в анализе данных.
Основные агрегатные функции:
- COUNT() – возвращает количество строк в выбранном наборе данных, включая или исключая значения NULL.
- SUM() – суммирует значения числовых столбцов, игнорируя NULL.
- AVG() – вычисляет среднее значение для числовых данных, игнорируя NULL.
- MIN() – находит минимальное значение в наборе данных.
- MAX() – находит максимальное значение в наборе данных.
Эти функции используются для обработки данных в различных контекстах, например, для подсчета количества записей, вычисления средней зарплаты по отделам или нахождения минимальных и максимальных значений в ассортименте товаров.
При работе с агрегатными функциями важно учитывать использование GROUP BY, чтобы разделить данные на группы для последующего анализа. Например, чтобы узнать средний доход по регионам, можно использовать следующую конструкцию:
SELECT region, AVG(income) FROM employees GROUP BY region;
В этом запросе данные о сотрудниках будут сгруппированы по регионам, а для каждой группы будет вычислено среднее значение дохода.
Агрегатные функции полезны при составлении отчетов, выявлении трендов и аномалий в данных. Однако следует помнить, что они могут влиять на производительность при работе с большими объемами данных. Чтобы оптимизировать запросы, важно применять индексы и корректно фильтровать данные до выполнения агрегирования с помощью WHERE или HAVING.
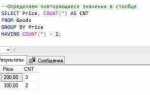
HAVING используется для фильтрации данных после применения агрегатных функций, в отличие от WHERE, который фильтрует данные до выполнения агрегирования. Например, для получения регионов с количеством сотрудников больше 10:
SELECT region, COUNT(*) FROM employees GROUP BY region HAVING COUNT(*) > 10;
Агрегатные функции в сочетании с правильной фильтрацией и группировкой данных позволяют строить точные и информативные отчеты, что делает SQL мощным инструментом для анализа больших наборов данных.
Как выполнять обновление данных в базе через запросы UPDATE
Для обновления данных в базе данных используется команда SQL UPDATE. Этот запрос позволяет изменить значения в одном или нескольких столбцах таблицы. Применение UPDATE требует внимательности, так как без должной фильтрации данных можно случайно изменить всю таблицу. Команда имеет следующий синтаксис:
UPDATE имя_таблицы
SET столбец1 = значение1, столбец2 = значение2, ...
[WHERE условие];Основной элемент запроса – это конструкция SET, которая задает новые значения для столбцов. Опция WHERE является необязательной, но она помогает ограничить область изменения данных. Без условия WHERE все строки таблицы будут обновлены.
Пример обновления данных:
UPDATE сотрудники
SET зарплата = 50000
WHERE должность = 'Менеджер';Этот запрос изменяет зарплату всех менеджеров на 50 000. Если условие WHERE отсутствует, то все записи в таблице будут обновлены, что может привести к нежелательным последствиям.
Можно использовать операторы в запросах UPDATE, чтобы вычислить новые значения для столбцов. Например:
UPDATE товары
SET цена = цена * 1.1
WHERE категория = 'Электроника';Этот запрос увеличивает цену на 10% для всех товаров категории «Электроника». Такие операции удобны, когда нужно изменить данные по определенным правилам, например, с учетом инфляции или сезонных акций.
В случае обновления данных, основанных на значениях других строк, можно использовать подзапросы. Пример:
UPDATE сотрудники
SET зарплата = (SELECT AVG(зарплата) FROM сотрудники WHERE отдел = 'IT')
WHERE отдел = 'IT';В этом запросе зарплата всех сотрудников отдела «IT» обновляется на среднее значение зарплат в этом же отделе. Такие запросы удобны для вычислений, которые зависят от других данных в базе.
При работе с UPDATE важно следить за производительностью запроса. Если таблица содержит большое количество строк, операции обновления могут занять продолжительное время. Для оптимизации можно использовать индексы на часто изменяемые столбцы, а также выполнять обновления частями, если это возможно.
Еще одной полезной практикой является использование транзакций, которые позволяют откатить изменения в случае ошибок. Например:
BEGIN TRANSACTION;
UPDATE товары
SET цена = цена * 1.05
WHERE категория = 'Одежда';
-- Если что-то пошло не так, можно выполнить откат:
-- ROLLBACK;
COMMIT;Такой подход обеспечивает безопасность данных и позволяет избежать потерь информации, если запрос выполняется некорректно.
Управление целостностью данных с помощью ограничений в SQL
Целостность данных в реляционных базах данных (РБД) обеспечивается через использование ограничений (constraints). Эти механизмы позволяют строго контролировать, какие данные могут быть внесены в таблицы, предотвращая ошибки и нарушения бизнес-логики. В SQL существуют различные типы ограничений, каждый из которых решает специфическую задачу в обеспечении целостности данных.
PRIMARY KEY – одно из основных ограничений, которое гарантирует уникальность значений в столбце или комбинации столбцов. Оно предотвращает ввод дублирующихся значений в поле, которое должно быть уникальным, например, в столбце идентификатора записи. PRIMARY KEY автоматически создает индекс, что также повышает производительность запросов.
FOREIGN KEY обеспечивает ссылочную целостность, устанавливая связь между двумя таблицами. Он гарантирует, что значения в столбце дочерней таблицы будут существовать в родительской таблице. При удалении или обновлении данных в родительской таблице можно задать действия с дочерними записями, например, ON DELETE CASCADE или ON UPDATE RESTRICT, чтобы обеспечить корректность всех ссылок в базе.
UNIQUE ограничение схоже с PRIMARY KEY, но оно позволяет оставлять в таблице строки, где поле может содержать NULL. Это ограничение часто используется, когда необходимо обеспечить уникальность, но без жестких требований к обязательности заполнения поля.
CHECK ограничение позволяет задать условия для значений в столбцах. Оно проверяет, соответствуют ли данные заданному условию (например, возраст должен быть больше 18 лет). Это ограничение помогает предотвратить ввод неверных или неподобающих значений, таких как отрицательные числа в столбце «количество» или неверные даты в поле «дата рождения».
NOT NULL обязательность поля – это ограничение, которое гарантирует, что в столбец не могут быть внесены пустые значения. Оно применяется, когда для конкретных данных невозможно принять отсутствие значения как валидный случай.
DEFAULT позволяет задать значение по умолчанию для столбца, если при вставке данных оно не было указано. Это ограничение помогает поддерживать стандартные значения и избегать ошибок, связанных с незаполненными полями.
Использование этих ограничений на практике важно для поддержания целостности данных в базе. Например, ограничение FOREIGN KEY помогает избежать появления «сиротских» записей, а CHECK позволяет контролировать ввод значений, соответствующих заранее заданным бизнес-правилам. Важно правильно выбирать и комбинировать ограничения, чтобы минимизировать вероятность ошибок при работе с данными и повысить их точность и актуальность.
Автоматизация задач с использованием SQL-скриптов

SQL-скрипты позволяют эффективно автоматизировать рутинные задачи в базах данных, что значительно снижает время на выполнение операций и минимизирует человеческий фактор. Такие скрипты могут применяться для регулярного обновления данных, создания резервных копий, анализа информации и выполнения сложных запросов по расписанию.
Основные области применения SQL-скриптов включают регулярные очистки данных, массовое обновление записей, создание отчетов и выполнение сложных выборок. Для этого скрипты можно интегрировать с системами автоматизации задач, такими как cron в Linux или Task Scheduler в Windows.
Пример автоматизации: создание резервной копии базы данных с использованием SQL. Запрос можно настроить на выполнение каждый день в определённое время. В зависимости от типа СУБД, команда для создания резервной копии может выглядеть по-разному. В MySQL это будет команда:
mysqldump -u username -p database_name > backup.sql
SQL-скрипты также могут использоваться для автоматического выполнения отчетности. Например, можно настроить выполнение скрипта, который собирает данные о продажах за неделю и отправляет их по электронной почте. Важно учитывать, что такие скрипты требуют регулярного мониторинга и тестирования, чтобы избежать ошибок при автоматическом выполнении.
Для задач с большой нагрузкой на базу данных, например, для массовых обновлений или вычислений, можно использовать транзакции для обеспечения атомарности операций. Это позволяет избежать частичной записи данных, что важно для поддержания консистентности базы данных в случае сбоев.
Автоматизация через SQL-скрипты требует тщательной настройки прав доступа, чтобы минимизировать риски несанкционированных изменений. Скрипты должны быть доступны только пользователям с необходимыми правами, а операции должны фиксироваться в логах для дальнейшего анализа.
Одним из примеров эффективной автоматизации является использование SQL-скриптов в сочетании с ETL-процессами для трансформации и загрузки данных. Такие скрипты могут ежедневно обновлять данные в отчетных системах, улучшая их актуальность и снижая нагрузку на администраторов баз данных.
Для повышения гибкости скриптов можно использовать переменные и параметры, что позволяет запускать один и тот же скрипт с разными исходными данными. Это существенно увеличивает повторное использование кода и уменьшает время на написание новых решений для схожих задач.
Вопрос-ответ:
Что такое SQL и как он используется для работы с базами данных?
SQL (Structured Query Language) — это язык запросов, который используется для управления данными в реляционных базах данных. Он позволяет выполнять различные операции с базами данных, такие как создание, обновление, удаление и извлечение информации. С помощью SQL можно создавать таблицы, добавлять в них записи, изменять данные и выполнять сложные запросы для получения нужной информации из множества таблиц. SQL является основой для работы с большинством систем управления базами данных, таких как MySQL, PostgreSQL, Oracle и других.