Знание SQL – это не просто дополнительный навык, а базовая необходимость для любого аналитика данных. По данным опроса Stack Overflow за 2023 год, SQL входит в пятёрку самых востребованных языков программирования среди специалистов по данным. Причина проста: подавляющее большинство бизнес-данных хранится в реляционных базах, таких как PostgreSQL, MySQL и Microsoft SQL Server.
SQL позволяет аналитикам напрямую обращаться к данным без необходимости дожидаться выгрузки от IT-отдела или BI-команды. Это даёт значительное преимущество в скорости анализа и принятия решений. Владение SQL ускоряет выполнение рутинных задач: агрегация, фильтрация, объединение таблиц и построение витрин данных становятся частью ежедневного рабочего процесса.
Практический эффект от владения SQL выражается в умении задавать правильные вопросы к данным и моментально получать на них ответы. Например, анализ оттока клиентов, сегментация по поведению пользователей или построение воронки продаж – всё это реализуется за считанные минуты при помощи SQL-запросов. Без этого навыка любой инструмент визуализации превращается в чёрный ящик с ограниченным контролем над выборкой.
Рекомендуется не просто уметь писать базовые SELECT-запросы, а уверенно использовать оконные функции, подзапросы, CTE и индексацию. Это не только расширяет диапазон аналитических задач, но и позволяет оптимизировать работу с большими объёмами данных, что критично при работе с миллионами строк в продакшене.
Как SQL помогает извлекать нужные данные из больших таблиц

Фильтрация с помощью WHERE позволяет мгновенно исключать ненужные строки. Например, запрос SELECT * FROM продажи WHERE год = 2024 AND регион = ‘Сибирь’ возвращает только актуальные для анализа данные, минимизируя объем обрабатываемой информации.
Индексация ускоряет выборку: если по колонке, участвующей в фильтрации, создан индекс, поиск выполняется в разы быстрее. Аналитик должен знать, по каким столбцам целесообразно запрашивать индексы у администратора базы.
Проекция нужных столбцов с помощью SELECT позволяет работать только с релевантными данными. Запрос SELECT клиент_id, сумма_покупки FROM продажи экономит ресурсы по сравнению с выборкой всех колонок через SELECT *.
Агрегирование и группировка с использованием GROUP BY и HAVING позволяют сводить большие массивы данных к компактным отчетам. Например, GROUP BY категория дает возможность получить суммарные показатели по каждой товарной группе без постобработки в BI-системах.
Подзапросы и CTE (общие табличные выражения) помогают структурировать логику выборки. Например, сначала фильтруются активные клиенты, затем на основе их идентификаторов извлекаются покупки – это упрощает чтение и повторное использование запросов.
LIMIT и OFFSET позволяют контролировать объем выборки. При анализе трендов или построении визуализаций можно ограничить данные последними 1000 записями без ущерба для результата.
Операторы JOIN дают возможность извлекать связные данные из нескольких таблиц. Например, объединение продажи с таблицей клиенты через INNER JOIN позволяет быстро получить демографию покупок без копирования данных в сторонние системы.
Зачем аналитикам использовать JOIN для объединения данных из разных источников

JOIN позволяет аналитикам интегрировать разрозненные таблицы в единую структуру, обеспечивая полное представление о процессах. Например, в электронной коммерции таблица заказов без соединения с таблицей клиентов не позволяет анализировать поведенческие паттерны конкретных сегментов пользователей. Использование INNER JOIN помогает фокусироваться только на пересечениях данных, минимизируя шум от неполных записей.
LEFT JOIN критичен при анализе воронок – он сохраняет все события пользователей, даже если некоторые шаги не были выполнены, что важно для оценки потерь на каждом этапе. RIGHT JOIN и FULL OUTER JOIN применяются реже, но полезны при необходимости сравнения данных из двух источников с возможными пропусками по обеим сторонам.
Разработка отчетов по эффективности маркетинга требует соединения данных о расходах (из одной системы) и данных о заказах (из другой). Без JOIN аналитик не сможет связать инвестиции с результатами. Пример: таблица с рекламными кампаниями содержит ID кампании, таблица заказов – только идентификатор источника трафика. JOIN по этим ключам позволяет рассчитать ROI.
JOIN также незаменим при нормализованной структуре хранилищ, где каждый аспект бизнес-процесса представлен отдельной таблицей. Это снижает дублирование, но требует точных соединений для извлечения целостной информации. Ошибки в условиях JOIN приводят к некорректной агрегации и искажению метрик, поэтому важно использовать явные условия соединения, избегая кросс-присоединений без фильтрации.
Для оптимальной производительности следует индексировать поля, участвующие в JOIN. При работе с большими объемами данных желательно предварительно фильтровать таблицы по ключевым параметрам, снижая объем пересекаемых записей. Это сокращает время выполнения запроса и снижает нагрузку на сервер.
Использование агрегатных функций для расчёта метрик в отчетах

Аналитики данных применяют агрегатные функции SQL для извлечения ключевых показателей из больших массивов информации. Эти функции позволяют выполнять обобщённые расчёты напрямую в запросах, минимизируя постобработку данных на других этапах аналитики.
Функция SUM() используется для подсчёта общего объёма продаж, выручки или расходов. Например, при анализе ежемесячных продаж достаточно сгруппировать данные по дате и применить SUM(sales_amount) для получения точного значения без промежуточных вычислений.
AVG() позволяет определить средние значения: средний чек, среднюю продолжительность сессии пользователя, среднюю стоимость заказа. Это особенно полезно в e-commerce и поведенческой аналитике, где важна оценка динамики изменения средних показателей.
Функции MAX() и MIN() используются для выявления экстремальных значений, таких как наибольшая сумма транзакции или минимальное время отклика сервера. Это критично для мониторинга SLA и оценки эффективности кампаний.
COUNT() часто применяется для расчёта количества уникальных клиентов, заказов или посещений. Вместе с DISTINCT она позволяет исключить дубликаты, например: COUNT(DISTINCT user_id) покажет точное количество пользователей, совершивших действие.
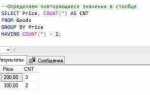
Эти функции становятся особенно эффективными при использовании с GROUP BY, HAVING и оконными функциями. Например, для расчёта средней выручки по регионам с фильтрацией только прибыльных направлений можно использовать:
SELECT region, AVG(revenue) AS avg_revenue
FROM sales
GROUP BY region
HAVING AVG(revenue) > 100000Для аналитика важно не просто применять агрегатные функции, а точно понимать контекст и цели метрик, чтобы избежать искажений при интерпретации данных.
Как SQL упрощает проверку гипотез и поиск закономерностей

SQL позволяет аналитикам быстро формулировать и тестировать гипотезы на больших массивах данных без необходимости выгружать их в сторонние инструменты. Например, чтобы проверить предположение о влиянии времени суток на конверсию, достаточно одного запроса с группировкой по часу и вычислением среднего значения по ключевому метрике.
С помощью оконных функций можно отследить поведение пользователей в динамике: выявить отток, рассчитать когорты, сравнить среднее время между действиями. Это критично для анализа пользовательских привычек и оценки эффективности изменений в продукте.
Функции агрегирования и фильтрации позволяют выделить аномалии и выбросы, не прибегая к внешней обработке. Например, WHERE и HAVING дают возможность исключать нерепрезентативные сегменты, а агрегаты AVG, MEDIAN, PERCENTILE_DISC – формировать нормализованные сравнения.
CTE (WITH-запросы) позволяют строить многослойные цепочки логики, где каждая последующая проверка основана на предыдущих результатах. Это особенно полезно при построении многошаговых фильтров или временных окон в экспериментальных данных.
Фильтрация и сегментация данных с помощью условий WHERE и CASE
Условие WHERE – это основной инструмент для фильтрации данных. С его помощью можно задавать конкретные критерии для строк, которые должны быть включены в результат запроса. К примеру, для анализа продаж определённого продукта или категории товаров, можно использовать такой запрос:
SELECT * FROM sales WHERE product_id = 101;Это позволит получить только те строки, где product_id равен 101. Однако возможности WHERE не ограничиваются простыми равенствами. Вы можете комбинировать несколько условий с помощью логических операторов AND, OR, а также использовать операторы сравнения, такие как BETWEEN, IN, LIKE и другие.
Пример с использованием нескольких условий:
SELECT * FROM sales WHERE product_id = 101 AND sale_date BETWEEN '2024-01-01' AND '2024-03-31';Это запрос отфильтрует данные по конкретному товару и только за первый квартал 2024 года.
Для более сложной сегментации данных, особенно если нужно разделить строки на категории в зависимости от их значений, используется конструкция CASE. Это условие позволяет добавить дополнительную логику в запрос, например, создавать новые столбцы, которые классифицируют строки в зависимости от значений других полей. Пример использования CASE для сегментации пользователей по возрасту:
SELECT name, birthdate,
CASE
WHEN age < 18 THEN 'Underage'
WHEN age BETWEEN 18 AND 35 THEN 'Young Adult'
WHEN age BETWEEN 36 AND 55 THEN 'Adult'
ELSE 'Senior'
END AS age_group
FROM users;Этот запрос создаёт новый столбец age_group, который разделяет пользователей на четыре возрастные группы. CASE позволяет гибко работать с диапазонами и создавать логику, которая недоступна при использовании стандартных операторов фильтрации.
Для фильтрации и сегментации данных также можно комбинировать WHERE и CASE. Например, можно отфильтровать только те строки, которые принадлежат определённой группе:
SELECT * FROM users
WHERE
CASE
WHEN age < 18 THEN 'Underage'
WHEN age BETWEEN 18 AND 35 THEN 'Young Adult'
ELSE 'Other'
END = 'Young Adult';Здесь условие CASE используется для фильтрации данных пользователей, которые относятся к группе "Young Adult".
Чтобы улучшить производительность запросов, важно избегать излишнего использования CASE в больших таблицах, особенно если это приводит к сложным вычислениям на лету. Оптимальные запросы должны минимизировать вычислительную нагрузку, выполняя фильтрацию на более ранних этапах, например, в подзапросах или с помощью индексов.
Наконец, всегда проверяйте, что ваши запросы корректно обрабатывают NULL-значения. В SQL для этого можно использовать условие IS NULL или IS NOT NULL, чтобы предотвратить исключения в анализируемых данных.
Автоматизация регулярных отчётов через представления и подзапросы
Автоматизация создания отчётов в SQL существенно ускоряет рабочие процессы аналитиков данных. Вместо того чтобы каждый раз вручную формировать сложные запросы, можно использовать представления (views) и подзапросы, что позволяет значительно повысить эффективность работы с данными.
Представления – это предопределённые SQL-запросы, которые могут быть использованы для создания логики отчётов. Они представляют собой виртуальные таблицы, которые не хранят данные, а лишь предоставляют доступ к данным через заранее определённые запросы. Это позволяет аналитикам фокусироваться на анализе данных, а не на их обработке каждый раз заново.
- Преимущества представлений:
- Облегчают доступ к часто используемым данным.
- Сокращают дублирование запросов, улучшая читаемость и поддержку кода.
- Упрощают доступ к сложным данным для менее опытных пользователей SQL.
- Пример: Если часто требуется получать сводные данные о продажах по регионам, можно создать представление, которое будет агрегировать эти данные, что позволит запрашивать уже подготовленные результаты без необходимости каждый раз строить сложные агрегации.
Подзапросы, в свою очередь, позволяют интегрировать сложные вычисления прямо в основной запрос, без необходимости предварительного создания представлений. Это полезно, когда отчёты требуют работы с динамическими данными, которые меняются из запроса в запрос.
- Преимущества подзапросов:
- Удобство использования в едином запросе, где не нужно создавать дополнительные объекты в базе данных.
- Повышение гибкости запросов за счёт возможности инкапсуляции логики внутри основного запроса.
- Пример: Для расчёта среднего значения продаж по регионам можно использовать подзапрос в секции SELECT, который сразу же будет возвращать необходимые данные, не создавая дополнительных объектов в базе данных.
Автоматизация через представления и подзапросы также позволяет улучшить производительность. Например, представление, создающее агрегированные данные, может быть быстрее, чем выполнение сложных вычислений для каждого отчёта, так как данные уже подготовлены. Подзапросы же позволяют избежать излишней избыточности при повторяющихся запросах, что также уменьшает нагрузку на сервер базы данных.
Таким образом, для аналитиков данных использование представлений и подзапросов является эффективным инструментом, который не только автоматизирует процесс формирования регулярных отчётов, но и улучшает производительность запросов, упрощает поддержку и делает работу с данными более гибкой и динамичной.
Вопрос-ответ:
Почему аналитикам данных важно знать SQL?
SQL является основным инструментом для работы с базами данных. Аналитики данных часто сталкиваются с необходимостью извлечь, обработать и анализировать данные, хранящиеся в реляционных базах данных. Знание SQL помогает ускорить этот процесс, позволив аналитикам строить запросы для извлечения информации, создавать агрегированные данные и выполнять различные фильтрации. Без SQL работа с большими объемами данных может быть значительно сложнее и занимать больше времени.
Какие преимущества дает знание SQL для работы с большими данными?
Когда работаешь с большими объемами данных, важно уметь эффективно извлекать нужную информацию. SQL позволяет создавать сложные запросы, которые могут фильтровать, группировать и агрегировать данные прямо в базе. Это снижает необходимость в дополнительной обработке данных в других инструментах, что экономит время и ресурсы. Например, с помощью SQL можно быстро извлечь подмножество данных для анализа, без необходимости загружать весь объем в аналитическое ПО.
Можно ли работать с данными без SQL, используя другие инструменты?
Да, есть другие инструменты, такие как Excel, Python или R, которые могут работать с данными и выполнять анализ без знания SQL. Однако эти инструменты часто требуют дополнительных шагов для обработки данных, таких как загрузка данных в память или использование API. SQL, напротив, позволяет работать напрямую с базой данных, не требуя лишней обработки, и может быть значительно быстрее при работе с большими объемами данных.
Какие конкретно запросы можно строить с помощью SQL, которые полезны для аналитика?
SQL позволяет строить различные типы запросов, которые очень полезны для аналитиков. Например, с помощью SELECT-запросов можно извлекать нужные данные, с помощью WHERE – фильтровать данные по определенным критериям, а с помощью GROUP BY – группировать данные по категориям для последующего анализа. Также с помощью JOIN-запросов можно объединять несколько таблиц и получать более полное представление о данных. В свою очередь, агрегатные функции, такие как SUM, AVG, COUNT, позволяют быстро вычислять суммы, средние значения и количество записей в определенной группе.
Какие навыки в SQL могут быть полезны для аналитиков данных, помимо базовых запросов?
Помимо базовых операций, таких как SELECT и фильтрация данных, полезными навыками для аналитиков являются умение работать с подзапросами, использование оконных функций для анализа данных в контексте других строк таблицы, а также создание и использование индексов для ускорения запросов. Также важно понимать, как работать с транзакциями и как оптимизировать запросы, чтобы работать с большими данными эффективно и быстро. Эти более сложные методы значительно расширяют возможности аналитика и позволяют ему делать более точные и быстрые выводы из данных.
Почему аналитикам данных нужно знать SQL?
SQL (Structured Query Language) — это язык, который используется для работы с базами данных. Для аналитиков данных знание SQL важно, потому что оно позволяет эффективно извлекать, фильтровать и агрегировать данные, что критически важно для анализа. Большинство данных в организациях хранятся именно в реляционных базах данных, и без умения работать с SQL аналитики теряют возможность быстро и точно извлекать нужную информацию. Например, с помощью SQL можно быстро найти все записи, которые соответствуют определённым критериям, объединить данные из разных таблиц и провести расчёты. Это значительно ускоряет процесс аналитики и помогает принимать обоснованные решения.