SQL запросы можно писать и запускать в нескольких средах, каждая из которых предлагает свои особенности и преимущества. Наиболее распространённые инструменты для работы с SQL – это специализированные СУБД, текстовые редакторы с поддержкой SQL, а также интегрированные среды разработки (IDE). Рассмотрим основные варианты, которые помогут вам выбрать подходящий инструмент в зависимости от ваших нужд.
1. СУБД с встроенными интерфейсами
Большинство СУБД предоставляют собственные клиентские приложения для работы с запросами. Например, MySQL Workbench для MySQL, pgAdmin для PostgreSQL и SQL Server Management Studio (SSMS) для MS SQL Server. Эти программы не только позволяют писать SQL запросы, но и обеспечивают удобную визуализацию данных, создание и управление базами, а также отладку запросов. Эти инструменты идеально подходят для пользователей, которые работают непосредственно с сервером базы данных и нуждаются в полном контроле над её структурой и содержимым.
2. Текстовые редакторы и IDE
Для пользователей, которые предпочитают более гибкие и легковесные решения, хорошим выбором могут стать текстовые редакторы, такие как VS Code или Sublime Text, с установленными плагинами для работы с SQL. Эти редакторы обеспечивают подсветку синтаксиса, автодополнение и даже базовые возможности для работы с базами данных через расширения. Преимущество таких редакторов – это лёгкость в настройке и возможность использовать их в рамках более широких проектов, например, при разработке серверных приложений или веб-сайтов.
3. Веб-интерфейсы и облачные решения
Если ваша база данных размещена в облаке, можно использовать веб-интерфейсы, такие как phpMyAdmin для MySQL или Cloud Console от Google Cloud для работы с базами данных через браузер. Эти инструменты позволяют быстро создавать, изменять и выполнять SQL запросы без необходимости устанавливать дополнительное ПО. Они удобны для тех, кто работает с базами данных на удалённых серверах и не хочет тратить время на настройку локальной среды разработки.
4. Командная строка
Для опытных пользователей, предпочитающих минимализм и скорость, удобным вариантом является использование командной строки. Все основные СУБД предоставляют утилиты для работы с SQL через консоль. Например, mysql для MySQL, psql для PostgreSQL и sqlcmd для SQL Server. Эти инструменты позволяют выполнять запросы непосредственно в терминале, что ускоряет процессы разработки и тестирования.
В конечном счёте, выбор инструмента зависит от ваших предпочтений, целей и уровня навыков. Каждая среда предоставляет различные возможности для работы с SQL, и важно выбрать ту, которая будет максимально эффективна для ваших задач.
Выбор инструмента для написания SQL запросов
Для написания SQL запросов важно выбрать подходящий инструмент, который обеспечит комфорт и эффективность работы с базой данных. На данный момент существует несколько популярных вариантов, каждый из которых подходит для различных целей и условий работы.
Одним из наиболее удобных инструментов является SQL-редактор, который идет в комплекте с большинством СУБД (систем управления базами данных). Например, MySQL Workbench для MySQL, pgAdmin для PostgreSQL и SQL Server Management Studio для Microsoft SQL Server. Эти программы предоставляют графический интерфейс для создания и выполнения запросов, а также позволяют работать с базой данных без необходимости запоминать командную строку. Они поддерживают автодополнение, что ускоряет написание запросов и минимизирует ошибки.
Если вы предпочитаете работу с текстовыми редакторами или IDE (интегрированными средами разработки), можно использовать такие популярные решения, как Visual Studio Code или Sublime Text. Эти редакторы поддерживают плагины для работы с SQL, что дает возможность подключаться к базе данных и выполнять запросы прямо в редакторе. Visual Studio Code, например, имеет расширение для работы с SQL, которое позволяет подключаться к различным СУБД, выполнять запросы и просматривать результаты без выхода из программы.
Для работы в командной строке лучше всего подходит инструмент, встроенный в саму СУБД, например, MySQL Command Line Client или psql для PostgreSQL. Эти инструменты полезны для администраторов и разработчиков, которым важно быстро выполнять запросы через терминал. Они не имеют графического интерфейса, но обеспечивают максимальную гибкость и скорость работы с базой данных, а также позволяют скриптовать задачи.
Если требуется работать с несколькими СУБД одновременно, стоит обратить внимание на универсальные SQL-клиенты, такие как DBeaver или HeidiSQL. Эти инструменты поддерживают работу с множеством различных СУБД и предлагают удобный интерфейс для написания запросов, администрирования и анализа данных. DBeaver, например, работает с более чем 80 различными СУБД, что делает его подходящим для многозадачной работы.
Наконец, для быстрого выполнения запросов в облачных СУБД (например, Google BigQuery или Amazon Redshift) существуют специализированные веб-интерфейсы и клиентские приложения, такие как BigQuery Console и AWS Query Editor. Эти решения обеспечивают удобство работы без необходимости устанавливать дополнительное ПО на локальный компьютер.
Выбор инструмента зависит от ваших предпочтений, типа СУБД и уровня работы с базами данных. Для новичков часто удобнее использовать графические инструменты с визуальным интерфейсом, а более опытные пользователи могут оценить гибкость и скорость работы с текстовыми редакторами и командной строкой.
Как подключиться к базе данных для выполнения SQL запросов
Для начала работы с базой данных необходимо установить соединение с ней. В зависимости от типа базы данных и используемой технологии, процесс подключения может отличаться. Рассмотрим основные шаги для подключения к популярным системам управления базами данных (СУБД).
Прежде чем подключиться, нужно убедиться, что у вас есть:
- Адрес сервера базы данных (IP-адрес или доменное имя).
- Порт для подключения (чаще всего 3306 для MySQL, 5432 для PostgreSQL).
- Логин и пароль для доступа.
- Имя базы данных для работы.
Рассмотрим подключения для различных СУБД:
MySQL
Для подключения к MySQL можно использовать различные библиотеки и инструменты. Один из популярных вариантов – это библиотека MySQL Connector для Python.
- Установите библиотеку:
pip install mysql-connector-python. - Пример подключения:
import mysql.connector
connection = mysql.connector.connect(
host="localhost",
user="root",
password="yourpassword",
database="yourdatabase"
)
cursor = connection.cursor()
cursor.execute("SELECT * FROM your_table")
Этот код создает соединение с базой данных MySQL и выполняет запрос. После выполнения запроса не забудьте закрыть соединение с базой данных:
connection.close()
PostgreSQL
Для работы с PostgreSQL удобным инструментом является библиотека psycopg2.
- Установите библиотеку:
pip install psycopg2. - Пример подключения:
import psycopg2
connection = psycopg2.connect(
host="localhost",
database="yourdatabase",
user="youruser",
password="yourpassword"
)
cursor = connection.cursor()
cursor.execute("SELECT * FROM your_table")
После выполнения запроса также следует закрыть соединение:
connection.close()
SQLite

SQLite – это встраиваемая СУБД, которая не требует отдельного сервера. Для работы с ней достаточно библиотеки sqlite3, которая встроена в стандартную библиотеку Python.
- Пример подключения:
import sqlite3
connection = sqlite3.connect('yourdatabase.db')
cursor = connection.cursor()
cursor.execute("SELECT * FROM your_table")
После завершения работы с базой данных, соединение необходимо закрыть:
connection.close()
Секреты безопасного подключения

- Не используйте стандартные учетные данные (например, «root» или «admin»). Настройте уникальные имена пользователей и пароли.
- Используйте защищенные каналы связи, такие как SSL, для подключения к базе данных, особенно при удаленном доступе.
- Не храните пароли в открытом виде в коде. Используйте переменные окружения или безопасные хранилища для конфиденциальных данных.
Следуя этим рекомендациям, вы сможете безопасно подключаться к базам данных и эффективно выполнять SQL-запросы.
Создание простых запросов SELECT для извлечения данных
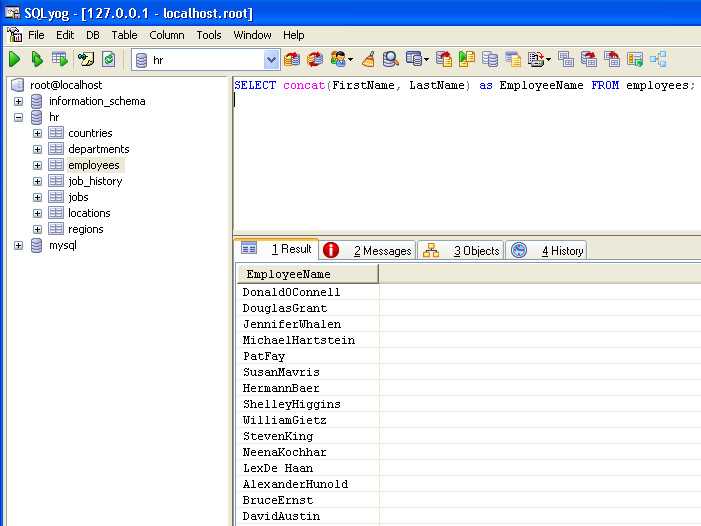
Запросы SELECT используются для извлечения данных из таблиц базы данных. Для начала важно понимать базовую структуру запроса SELECT, который включает ключевое слово SELECT, за которым следуют указания о том, какие именно данные нужно получить.
Простой запрос SELECT может выглядеть так: SELECT column_name FROM table_name;. Этот запрос извлекает данные из указанной колонки таблицы. Например, чтобы получить все значения в колонке name из таблицы employees, запрос будет таким:
SELECT name FROM employees;Можно извлекать несколько колонок, разделяя их запятыми. Например, запрос для получения колонок name и salary из таблицы employees будет следующим:
SELECT name, salary FROM employees;Для того чтобы извлечь все данные из таблицы, используется звёздочка *:
SELECT * FROM employees;Запрос SELECT позволяет фильтровать данные с помощью оператора WHERE. Этот оператор задаёт условие, по которому будут извлекаться только те строки, которые его удовлетворяют. Например, чтобы получить имена сотрудников с зарплатой больше 50000, запрос будет таким:
SELECT name FROM employees WHERE salary > 50000;Для сортировки данных используется оператор ORDER BY. Он позволяет упорядочить результаты по одному или нескольким столбцам. Например, чтобы отсортировать сотрудников по имени в алфавитном порядке, запрос будет выглядеть так:
SELECT name FROM employees ORDER BY name;Если нужно отсортировать по убыванию, добавляется ключевое слово DESC:
SELECT name, salary FROM employees ORDER BY salary DESC;Простой запрос SELECT – это основа работы с данными в SQL. Он позволяет извлекать необходимые данные, фильтровать их и упорядочивать в зависимости от потребностей. С помощью этих базовых команд можно строить запросы для различных задач, от простых до более сложных.
Фильтрация данных с помощью WHERE и операторы сравнения
Оператор WHERE используется для ограничения результатов SQL-запроса по определённым условиям. Он применяется после оператора SELECT и позволяет фильтровать строки, которые удовлетворяют заданным критериям. Основное преимущество WHERE в том, что он даёт возможность уточнить, какие именно данные из базы данных будут возвращены в результате запроса.
Для фильтрации данных часто применяются операторы сравнения, которые позволяют проверить соответствие значений различных типов данных. К основным операторам сравнения относятся:
- = – равенство. Сравнивает два значения на идентичность. Например,
SELECT * FROM employees WHERE salary = 50000;вернёт сотрудников с зарплатой ровно 50000. - <> или != – неравенство. Ожидает значения, которые не равны заданному. Например,
SELECT * FROM products WHERE price != 100;вернёт все товары, цена которых не равна 100. - > – больше. Используется для поиска значений, которые больше заданного. Пример:
SELECT * FROM orders WHERE order_date > '2025-01-01';вернёт все заказы, сделанные после 1 января 2025 года. - < – меньше. Находит значения, которые меньше указанного. Например,
SELECT * FROM employees WHERE age < 30;вернёт сотрудников младше 30 лет. - >= – больше или равно. Применяется для нахождения значений, которые больше или равны заданному. Пример:
SELECT * FROM events WHERE event_date >= '2025-01-01';вернёт события начиная с 1 января 2025 года. - <= – меньше или равно. Находит значения, которые меньше или равны определённому. Например,
SELECT * FROM sales WHERE amount <= 1000;вернёт все продажи, сумма которых не превышает 1000.
Для более сложных фильтров можно комбинировать операторы сравнения с логическими операторами AND, OR и NOT. Например, запрос SELECT * FROM customers WHERE age > 25 AND city = 'Moscow'; вернёт всех клиентов старше 25 лет, проживающих в Москве. Это позволяет более гибко подходить к выборке данных, создавая более точные фильтры.
Использование оператора BETWEEN позволяет указывать диапазоны значений. Например, SELECT * FROM orders WHERE order_amount BETWEEN 100 AND 500; вернёт заказы с суммой от 100 до 500 включительно. Это особенно удобно, когда нужно отфильтровать данные в пределах определённого диапазона.
Для строковых данных часто используется оператор LIKE, который позволяет искать совпадения с шаблоном. Пример: SELECT * FROM customers WHERE name LIKE 'J%'; вернёт всех клиентов, чьи имена начинаются с буквы «J». Оператор LIKE поддерживает два специальных символа: % (совпадение с любым количеством символов) и _ (совпадение с одним символом).
В некоторых случаях могут использоваться операторы IS NULL и IS NOT NULL, которые проверяют на наличие или отсутствие значения в поле. Например, SELECT * FROM products WHERE expiration_date IS NULL; вернёт все товары, для которых не указана дата истечения срока годности.
Для оптимизации запросов и повышения их эффективности важно понимать особенности работы с фильтрацией данных. Например, при использовании оператора LIKE с ведущими символами, такими как ‘%’, индексы на столбцах могут не использоваться эффективно. В таких случаях рекомендуется пересматривать структуру запроса или базы данных для улучшения производительности.
Использование JOIN для объединения данных из нескольких таблиц
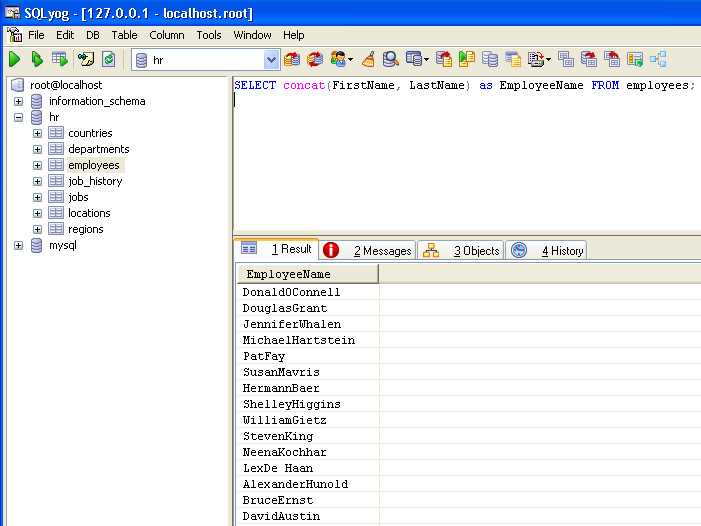
В SQL оператор JOIN позволяет объединять данные из разных таблиц на основе определённого условия. Он используется для получения информации, которая распределена по различным таблицам, но логически связана. Основной принцип работы JOIN заключается в объединении строк двух и более таблиц, где каждая строка одной таблицы соответствует строкам другой таблицы по определённому ключу.
Существует несколько типов JOIN, каждый из которых имеет свои особенности и применяемость в зависимости от того, какие данные необходимо получить:
INNER JOIN — объединяет строки, которые имеют соответствующие значения в обеих таблицах. Этот тип используется, когда важно, чтобы в результирующем наборе данных присутствовали только те строки, для которых найдены совпадения в обеих таблицах.
LEFT JOIN (или LEFT OUTER JOIN) — возвращает все строки из левой таблицы, а также соответствующие строки из правой таблицы. Если для строки из левой таблицы не найдено соответствий в правой, то в результирующем наборе данных будут присутствовать значения NULL в столбцах правой таблицы.
RIGHT JOIN (или RIGHT OUTER JOIN) — аналогичен LEFT JOIN, но возвращает все строки из правой таблицы и соответствующие строки из левой. Когда строки из правой таблицы не имеют соответствий в левой, значения левой таблицы будут NULL.
FULL JOIN (или FULL OUTER JOIN) — объединяет все строки из обеих таблиц. Если для строки одной таблицы нет соответствующей строки в другой, то в результирующем наборе данных будут присутствовать NULL-значения для столбцов не имеющих соответствий.
CROSS JOIN — создаёт декартово произведение двух таблиц, то есть все возможные комбинации строк из обеих таблиц. Этот тип соединения используется реже, так как может привести к большому количеству строк в результате.
При работе с JOIN важно помнить, что использование индексов на столбцах, которые участвуют в соединении, значительно повышает производительность запросов. Также стоит учитывать порядок объединений, так как в случае сложных запросов с множественными соединениями последовательность выполнения может повлиять на скорость.
Для улучшения читаемости и оптимизации запросов рекомендуется явно указывать таблицы, с которыми работает запрос, а также использовать псевдонимы для таблиц. Это помогает избежать путаницы в столбцах и ускоряет анализ запросов.
Пример использования INNER JOIN:
SELECT employees.name, departments.name FROM employees INNER JOIN departments ON employees.department_id = departments.id;
Здесь мы объединяем таблицы employees и departments, получая имена сотрудников и соответствующие им департаменты, при этом будут отображены только те строки, где есть совпадение по ключу department_id.
Знание того, какой тип JOIN использовать в зависимости от требований задачи, позволяет эффективно работать с базами данных и получать нужные данные без избыточных вычислений.
Как обновлять и удалять данные с помощью SQL
Для обновления данных в базе используется команда UPDATE. Она позволяет изменять значения в одном или нескольких столбцах таблицы. Структура запроса следующая:
UPDATE имя_таблицы
SET столбец1 = значение1, столбец2 = значение2
WHERE условие;Важно всегда использовать WHERE, чтобы избежать изменения всех записей в таблице. Без этого условия будут обновлены все строки.
Пример:
UPDATE сотрудники
SET зарплата = 50000
WHERE должность = 'менеджер';В этом примере обновляется зарплата всех сотрудников, чья должность – «менеджер». Если бы WHERE отсутствовало, обновились бы все строки таблицы.
Для удаления данных используется команда DELETE. Она удаляет строки, соответствующие определённому условию. Структура запроса:
DELETE FROM имя_таблицы
WHERE условие;Как и в случае с UPDATE, использование WHERE критично, чтобы избежать удаления всех данных из таблицы.
Пример:
DELETE FROM сотрудники
WHERE должность = 'стажёр';Этот запрос удаляет все записи, где должность сотрудника – «стажёр». Без WHERE запрос удалит все строки из таблицы.
Если нужно удалить все данные из таблицы, но оставить саму таблицу, можно использовать запрос без WHERE:
DELETE FROM сотрудники;Однако для массовых обновлений или удалений, особенно в больших таблицах, стоит учитывать производительность. Например, при массовых обновлениях иногда лучше использовать транзакции, чтобы предотвратить частичное выполнение запросов в случае ошибок.
Оптимизация SQL запросов для работы с большими объемами данных
Работа с большими объемами данных требует особого подхода в написании SQL запросов. Чем больше данных, тем больше вероятность возникновения проблем с производительностью. Для эффективной работы с большими базами данных необходимо использовать методы оптимизации запросов.
Первым шагом является использование индексов. Индексы значительно ускоряют поиск по базе данных, особенно при выполнении запросов с условиями WHERE и JOIN. Важно выбирать правильные поля для индексирования. Индексы на часто используемые столбцы, такие как внешние ключи, уникальные идентификаторы и поля с высоким коэффициентом выбора, могут существенно повысить скорость выполнения запросов.
Для работы с большими данными следует избегать использования * (всех столбцов) в SELECT-запросах. Выбирайте только те столбцы, которые действительно необходимы для выполнения задачи. Это не только улучшает производительность, но и снижает нагрузку на сеть и объем передаваемых данных.
Также стоит обратить внимание на использование правильных типов данных. Использование подходящих типов данных для хранения информации помогает снизить нагрузку на систему. Например, использование типа INT вместо VARCHAR для числовых значений сокращает размер хранимых данных и ускоряет их обработку.
Еще одной важной практикой является оптимизация JOIN-запросов. При использовании нескольких таблиц в одном запросе необходимо учитывать порядок соединений. При соединении таблиц лучше сначала связывать меньшие таблицы или таблицы с индексами, чтобы минимизировать количество строк, которые нужно обработать. Кроме того, стоит избегать использования JOIN с подзапросами, так как это может существенно замедлить выполнение запроса.
Для обработки больших объемов данных эффективно использовать пагинацию. Вместо того, чтобы запрашивать все строки сразу, можно использовать лимитированные запросы с ограничением на количество строк, например, с помощью оператора LIMIT. Это особенно полезно при отображении данных на веб-страницах или в отчетах, когда нужно обработать только часть данных за один раз.
Еще одной важной техникой является использование анализа выполнения запросов с помощью EXPLAIN. Этот инструмент позволяет увидеть план выполнения запроса и выявить узкие места. Он показывает, какие индексы использует запрос, как осуществляется сортировка, и какие операции занимают больше времени.
В некоторых случаях может быть полезным использование материализованных представлений. Материализованные представления позволяют сохранить результаты сложных запросов на диск, а затем обращаться к ним как к обычным таблицам. Это сокращает время выполнения повторяющихся запросов, особенно в случаях с большими объемами данных.
Наконец, следует учитывать параллельную обработку запросов. Если база данных поддерживает параллельное выполнение запросов, это позволяет ускорить обработку больших объемов данных, распределяя нагрузку между несколькими ядрами процессора.
Оптимизация SQL запросов – это не разовый процесс, а постоянная практика, требующая учета множества факторов: правильного использования индексов, типов данных, структуры таблиц и грамотного анализа производительности. Соблюдая эти принципы, можно значительно ускорить работу с большими объемами данных и улучшить общую эффективность системы.
Вопрос-ответ:
Что такое SQL запрос и для чего он используется при работе с базами данных?
SQL (Structured Query Language) — это язык, который используется для взаимодействия с базами данных. С помощью SQL запросов можно извлекать, обновлять, добавлять и удалять данные в базе. Примеры запросов включают выборку данных из таблиц, создание новых таблиц и изменение структуры базы данных. Эти запросы необходимы для работы с любыми реляционными базами данных, такими как MySQL, PostgreSQL, Microsoft SQL Server и другие.
Где можно писать SQL запросы для работы с базами данных?
SQL запросы можно писать в различных средах разработки и инструментах для работы с базами данных. Например, можно использовать графические интерфейсы, такие как MySQL Workbench, pgAdmin для PostgreSQL, или SQL Server Management Studio для Microsoft SQL Server. Также SQL запросы можно писать в командной строке с помощью клиентских утилит, например, `mysql` или `psql`. В случае разработки веб-приложений или серверных приложений, запросы можно интегрировать в код с помощью библиотек для работы с базами данных, например, через Python, Java или PHP.
Как выбрать подходящий инструмент для написания SQL запросов?
Выбор инструмента зависит от нескольких факторов, таких как тип используемой базы данных, предпочтения пользователя и цель работы. Например, для работы с MySQL подойдут инструменты вроде MySQL Workbench или DBeaver. Для PostgreSQL хорошим выбором будет pgAdmin или DBeaver. Если вам нужно интегрировать SQL запросы в программное обеспечение, можно использовать библиотеки для работы с базами данных в Python, Java, Node.js и других языках. Важно выбирать инструмент, который поддерживает вашу базу данных и удобен для использования в ваших проектах.
Как начать работать с SQL запросами для баз данных?
Для начала работы с SQL запросами необходимо выбрать подходящий инструмент для взаимодействия с базой данных. Это может быть как графическая оболочка для работы с базами, например, MySQL Workbench, pgAdmin, так и текстовый редактор с подключением к серверу базы данных. Далее, нужно понять основы языка SQL: основные команды для выборки данных, такие как SELECT, операторы фильтрации, группировки, сортировки, а также работу с несколькими таблицами через JOIN. Пример простого запроса: SELECT * FROM users WHERE age > 30;