Как использовать команду INSERT для добавления данных

Команда INSERT применяется для добавления новой строки в указанную таблицу базы данных. Стандартный синтаксис включает имя таблицы и перечень столбцов, значения которых задаются в том же порядке.
INSERT INTO имя_таблицы (столбец1, столбец2, ...) VALUES (значение1, значение2, ...);Если перечислены не все столбцы, остальные должны иметь значения по умолчанию или допускать NULL. Пример:
INSERT INTO сотрудники (имя, должность) VALUES ('Ирина Смирнова', 'аналитик');Для добавления сразу нескольких строк используется следующий синтаксис:
INSERT INTO заказы (номер, клиент, сумма) VALUES
(101, 'ООО Север', 15200),
(102, 'ЗАО ЮгТорг', 9840);При работе с числовыми значениями не используйте кавычки. Строковые значения заключайте в одинарные кавычки. Для даты используйте формат 'YYYY-MM-DD'. Пример:
INSERT INTO события (название, дата) VALUES ('Презентация', '2025-05-01');В случае, если значения задаются для всех столбцов и их порядок соответствует порядку в таблице, список столбцов можно опустить:
INSERT INTO товары VALUES (11, 'Ноутбук', 69900);Для проверки добавленных данных используйте SELECT:
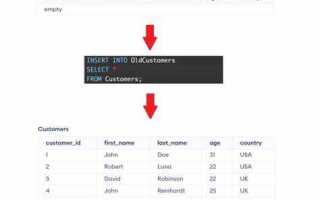
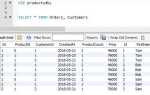
SELECT * FROM товары WHERE id = 11;Чтобы предотвратить дублирование записей, перед вставкой можно использовать конструкцию с подзапросом и условием NOT EXISTS:
INSERT INTO клиенты (email, имя)
SELECT 'test@example.com', 'Андрей'
WHERE NOT EXISTS (
SELECT 1 FROM клиенты WHERE email = 'test@example.com'
);Команда INSERT не возвращает результат, если только не используется дополнение RETURNING (доступно в PostgreSQL и других СУБД):
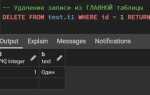
INSERT INTO сотрудники (имя) VALUES ('Лариса') RETURNING id;Заполнение полей таблицы: обязательные и необязательные значения
Перед добавлением новой записи необходимо определить, какие поля таблицы требуют обязательного заполнения. В SQL это регулируется ограничением NOT NULL. Если поле объявлено с этим ограничением, оно не может оставаться пустым при вставке данных. Попытка вставить NULL приведёт к ошибке выполнения запроса.
Пример: если столбец email в таблице users задан как VARCHAR(255) NOT NULL, то каждая новая запись обязана содержать корректный адрес электронной почты. Пропуск значения вызовет ошибку ERROR: null value in column "email" violates not-null constraint.
Необязательные поля допускают NULL или могут иметь значение по умолчанию, заданное с помощью DEFAULT. Если значение не указано явно, будет использовано это значение. Например, поле is_active BOOLEAN DEFAULT TRUE автоматически примет TRUE, если его не указать при вставке.
При использовании оператора INSERT желательно явно указывать имена столбцов, чтобы избежать несоответствия порядков значений и структуры таблицы. Это особенно критично, если добавляются только обязательные поля. Пример корректного запроса:
INSERT INTO users (username, email) VALUES ('ivan_petrov', 'ivan@example.com');
Для необязательных полей рекомендуется использовать NULL только в случае, если отсутствие значения имеет логический смысл. Злоупотребление NULL усложняет агрегации и фильтрацию данных. Если значение по умолчанию может точно отражать отсутствие данных (например, 0 или пустая строка), стоит использовать его вместо NULL.
Важно проводить валидацию на уровне приложения до выполнения SQL-запроса. Это позволяет исключить отправку неполных или некорректных данных и снизить нагрузку на СУБД.
Работа с типами данных при вставке записи
При добавлении записи в SQL-таблицу важно строго соблюдать соответствие типов данных столбцов и вставляемых значений. Несоответствие может привести к ошибке выполнения или потере данных из-за неявного преобразования.
Числовые типы: для INT, BIGINT, DECIMAL и других чисел важно избегать кавычек. Например, INSERT INTO products (price) VALUES (199.99); безопаснее, чем VALUES ('199.99'), так как второй вариант зависит от правил приведения типов СУБД.
Строки: значения для VARCHAR и TEXT обязательно заключать в одинарные кавычки. Спецсимволы – экранировать. Пример: 'O''Reilly' вместо 'O'Reilly'.
Даты и время: формат должен строго соответствовать ожидаемому типу, например DATE – ‘YYYY-MM-DD’, DATETIME – ‘YYYY-MM-DD HH:MM:SS’. Использование некорректного формата не вызывает ошибку в некоторых СУБД, но приводит к обнулению значения или установке дефолтной даты.
Булевы значения: в PostgreSQL можно использовать TRUE/FALSE, в MySQL допустимы 1/0, но предпочтительно явно использовать TRUE/FALSE для читаемости и переносимости.
NULL: не используйте кавычки вокруг NULL. INSERT INTO users (nickname) VALUES (NULL); корректен. VALUES ('NULL') добавит строку, а не пустое значение.
При использовании подготовленных выражений или ORM, проверяйте, как осуществляется маппинг типов данных. Ошибки в преобразовании часто незаметны при тестировании, но приводят к критическим сбоям при работе с реальными данными.
Добавление нескольких записей за один запрос
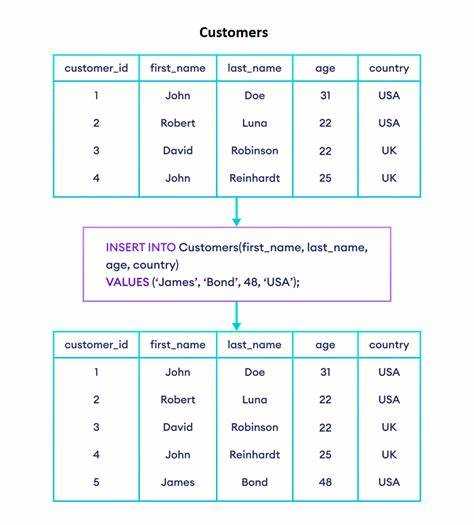
Чтобы вставить несколько строк в таблицу за один SQL-запрос, используйте конструкцию INSERT INTO с перечислением значений через запятую. Это снижает нагрузку на сервер и ускоряет выполнение операций записи.
INSERT INTO employees (name, position, salary)
VALUES
('Иванов И.И.', 'Менеджер', 60000),
('Петров П.П.', 'Аналитик', 70000),
('Сидоров С.С.', 'Разработчик', 80000);
При таком подходе сервер обрабатывает одну инструкцию вместо нескольких, что особенно важно при работе с большим объёмом данных.
- Обеспечьте совпадение количества и порядка столбцов и значений в каждом наборе.
- Все строки должны удовлетворять ограничениям таблицы (NOT NULL, UNIQUE, CHECK и т.д.).
- Если используется автоинкрементный ключ, его можно опустить в списке столбцов.
При ошибке в одной из строк весь запрос может быть отклонён. Чтобы избежать потери всех данных из-за одной некорректной строки, используйте:
INSERT IGNORE INTO ...или обработку ошибок на уровне приложения. Для повышения читаемости и управления вставкой больших объёмов данных:
- Группируйте вставку не более чем по 1000 строк за раз (для MySQL, зависит от конфигурации).
- Используйте подготовленные выражения и пакетную вставку при работе через API (например, в Python – executemany()).
Массовая вставка особенно эффективна при инициализации базы, миграциях и импорте данных из внешних источников.
Обработка ошибок при вставке данных в SQL
Ошибки при вставке данных могут нарушить логику приложения и привести к потере информации. Эффективная обработка исключений повышает стабильность и предсказуемость работы с базой данных.
- Нарушение ограничений уникальности (UNIQUE, PRIMARY KEY). Перед вставкой проверяй существование записи по ключевым полям. Используй конструкцию
INSERT ... ON CONFLICT DO NOTHINGв PostgreSQL илиINSERT IGNOREв MySQL, чтобы избежать дублирования. - Несоответствие типов данных. Приводить значения к нужным типам нужно на уровне приложения. Например, перед вставкой даты проверь формат:
YYYY-MM-DD. Для числовых полей фильтруй нечисловой ввод. - Нарушение ограничений NOT NULL. Явно указывай значения всех обязательных полей. Используй проверки на уровне приложения, чтобы не вставлять
NULLв критичные колонки. - Ошибки внешних ключей (FOREIGN KEY). Убедись, что связанные записи существуют. Выполняй запрос
SELECT 1 FROM related_table WHERE id = ?до вставки данных, ссылающихся на внешний ключ. - Тайм-ауты и блокировки. Вставка может заблокироваться при конкуренции за ресурсы. Используй транзакции с коротким временем выполнения, а в PostgreSQL – уровень изоляции
READ COMMITTED.
- Всегда оборачивай вставку в конструкцию обработки исключений (например,
try/catchв Python,BEGIN ... EXCEPTION ... ENDв PL/pgSQL). - Логируй текст ошибки, SQL-запрос и переданные значения. Это упрощает диагностику.
- Оценивай повторяемость ошибки: если ошибка связана с внешними условиями (например, потеря связи с БД), предусмотрите повторную попытку вставки.
Игнорирование ошибок вставки приводит к частичным обновлениям и повреждённым данным. Обработка исключений – не опциональная, а обязательная часть любой системы работы с SQL.
Вставка данных с использованием подзапросов
Подзапросы позволяют вставлять данные в таблицу, извлекая значения из другой таблицы или выполнения вычислений, не требующих создания промежуточных временных таблиц. В SQL подзапросы могут быть использованы в операциях INSERT, что позволяет создавать более гибкие запросы и избегать многократных обращений к базе данных.
Простейший пример вставки данных с подзапросом включает использование данных из одной таблицы для добавления записей в другую. Например, для копирования всех записей из таблицы employees в таблицу archived_employees, можно использовать следующий запрос:
INSERT INTO archived_employees (id, name, department)
SELECT id, name, department
FROM employees
WHERE status = 'inactive';Здесь подзапрос внутри оператора SELECT выбирает только тех сотрудников, чье состояние равно «inactive», и вставляет их в таблицу архивированных сотрудников. Такой подход позволяет динамически извлекать данные и избегать статичной предустановки значений.
Подзапросы могут быть использованы и для вставки агрегированных данных. Например, если необходимо подсчитать средний доход по каждому отделу и вставить эти данные в таблицу department_salaries, можно использовать запрос:
INSERT INTO department_salaries (department, average_salary)
SELECT department, AVG(salary)
FROM employees
GROUP BY department;В данном случае, подзапрос вычисляет среднюю зарплату для каждого отдела, и эти данные вставляются в таблицу department_salaries. Это особенно полезно, когда необходимо агрегировать данные без предварительных вычислений вручную.
Использование подзапросов в операциях INSERT позволяет не только упростить код, но и улучшить производительность, так как позволяет выполнить один запрос вместо нескольких, уменьшая количество операций записи в базу данных.
Вставка данных с подзапросами может включать использование нескольких подзапросов. Например, для добавления нового сотрудника в таблицу можно использовать значения, которые извлекаются сразу из нескольких таблиц, как в следующем примере:
INSERT INTO employees (id, name, department, salary)
SELECT e.id, e.name, e.department, s.salary
FROM new_employees e
JOIN salary_updates s ON e.id = s.employee_id
WHERE s.update_date = (SELECT MAX(update_date) FROM salary_updates WHERE employee_id = e.id);Здесь используется подзапрос для получения последней записи обновлений зарплаты для каждого нового сотрудника. Такой подход позволяет автоматизировать процесс вставки с учетом текущих данных, избегая необходимости предварительно обрабатывать их.
При использовании подзапросов важно учитывать производительность базы данных, особенно если запросы выполняются на больших объемах данных. В некоторых случаях может быть более эффективно использовать временные таблицы или выполнять обработку данных вне SQL, а затем вставлять уже готовые данные.
Автоматическая генерация значений с помощью автоинкремента
Для создания автоинкрементируемого столбца в MySQL и других популярных СУБД достаточно указать соответствующие параметры при создании таблицы. Например, в MySQL это выглядит так:
CREATE TABLE users ( id INT AUTO_INCREMENT, name VARCHAR(100), PRIMARY KEY (id) );
В данном примере столбец «id» будет автоматически увеличиваться на единицу с каждой новой записью, начиная с 1. Стандартный шаг увеличения составляет 1, но его можно изменить в зависимости от требований. Для этого используется команда ALTER TABLE для изменения текущего значения автоинкремента:
ALTER TABLE users AUTO_INCREMENT = 1000;
В результате следующий добавляемый идентификатор будет равен 1000. Это полезно, когда нужно начать отсчет с определенного числа, например, при импортировании данных из другой системы.
Важно учитывать, что автоинкремент не гарантирует, что значения будут без пропусков. Если запись удалена, следующее значение будет больше, чем оставшееся после удаления, что делает механизм непригодным для получения непрерывной последовательности чисел. Это следует учитывать при проектировании приложений, где важно не только уникальное значение, но и последовательность чисел.
Для увеличения гибкости механизма автоинкремента также можно использовать типы данных с большим диапазоном, такие как BIGINT, если предполагается большое количество записей. Важно следить за тем, чтобы значение автоинкремента не достигло максимума для выбранного типа данных, что может привести к ошибкам при добавлении новых записей.
Вопрос-ответ:
Что произойдет, если в запросе INSERT INTO указаны неправильные имена столбцов?
Если в запросе указаны неправильные имена столбцов, SQL-сервер вернет ошибку, информируя о том, что такие столбцы не существуют в таблице. Для предотвращения ошибок необходимо внимательно проверять названия столбцов, а также их порядок, если они указаны в запросе. Также важно убедиться, что типы данных в запросе соответствуют типам данных столбцов в таблице.