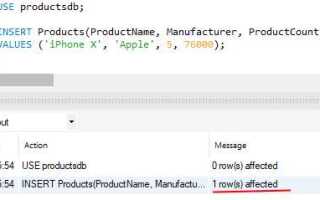
Добавление нового столбца в существующую таблицу SQL – это операция, напрямую влияющая на структуру базы данных и поведение приложений, которые с ней взаимодействуют. Перед изменением схемы таблицы необходимо убедиться в отсутствии конфликтов с текущими данными и запросами. Особенно это критично для production-сред и таблиц с высокой нагрузкой.
Для изменения структуры таблицы используется команда ALTER TABLE. Синтаксис зависит от СУБД, но общий подход выглядит так: ALTER TABLE имя_таблицы ADD имя_столбца тип_данных [дополнительные_параметры]. Например, в PostgreSQL можно добавить поле с типом timestamp with time zone и значением по умолчанию: ALTER TABLE users ADD last_login TIMESTAMPTZ DEFAULT now().
Важно учитывать, что добавление столбца с NOT NULL без значения по умолчанию приведёт к ошибке, если в таблице уже есть данные. В таких случаях сначала добавляют столбец без ограничений, обновляют значения через UPDATE, а затем применяют ограничение ALTER TABLE … ALTER COLUMN … SET NOT NULL. Это минимизирует риски блокировки и потери производительности.
Если таблица содержит миллионы строк, изменение структуры может вызвать длительные блокировки. В MySQL InnoDB, начиная с версии 5.6, операция добавления столбца выполняется без блокировки таблицы в большинстве случаев, если не указаны дополнительные ограничения. Однако перед применением изменений на крупной таблице желательно провести их сначала на копии, а затем – через pt-online-schema-change или аналогичный инструмент для безостановочного развёртывания.
Выбор типа данных для нового поля
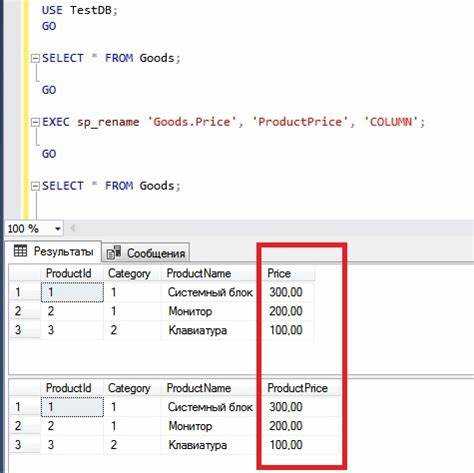
Перед добавлением нового поля в таблицу необходимо определить, какие значения оно будет хранить, как часто изменяться и участвовать ли в индексах или фильтрации. От типа данных напрямую зависит производительность, объем занимаемой памяти и корректность хранения информации.
- Целочисленные типы: Используйте
INT,SMALLINT,TINYINTв зависимости от ожидаемого диапазона значений. Например,TINYINT(1 байт) подходит для хранения чисел от 0 до 255, что эффективно по памяти при хранении флагов или порядковых номеров. - Числа с плавающей точкой:
FLOATиDOUBLEприменяются для научных расчетов, но не подходят для финансовых данных из-за потерь точности. Для валют используйтеDECIMAL(p, s), гдеp– общее количество цифр,s– количество знаков после запятой. - Строки:
VARCHAR(n)– оптимальный выбор при переменной длине текста. Устанавливайтеnс запасом, но не чрезмерным – это влияет на планировщик запросов. Для фиксированной длины используйтеCHAR(n), например, для хранения кода региона. - Дата и время:
DATE,TIME,DATETIMEподбираются строго по требованиям. Если достаточно хранить только дату – не используйтеDATETIME, чтобы не увеличивать размер строки. - Булевы значения: В MySQL применяют
TINYINT(1), в PostgreSQL –BOOLEAN. Учитывайте особенности движка при выборе. - Уникальные идентификаторы: Для глобальных идентификаторов применяйте
UUID. В PostgreSQL используйте встроенный типUUID, в MySQL – храните какCHAR(36)или бинарно –BINARY(16). - JSON и структуры: Если поле должно хранить вложенные данные, в PostgreSQL используйте
JSONB– он индексируется и быстрее при выборках. В MySQL –JSON, но избегайте сложных структур, если поле будет часто фильтроваться.
После выбора типа данных проверьте требования к совместимости с существующими индексами, внешними ключами и триггерами. При необходимости обеспечьте конвертацию значений по умолчанию или настройте миграционные скрипты.
Добавление поля с помощью команды ALTER TABLE
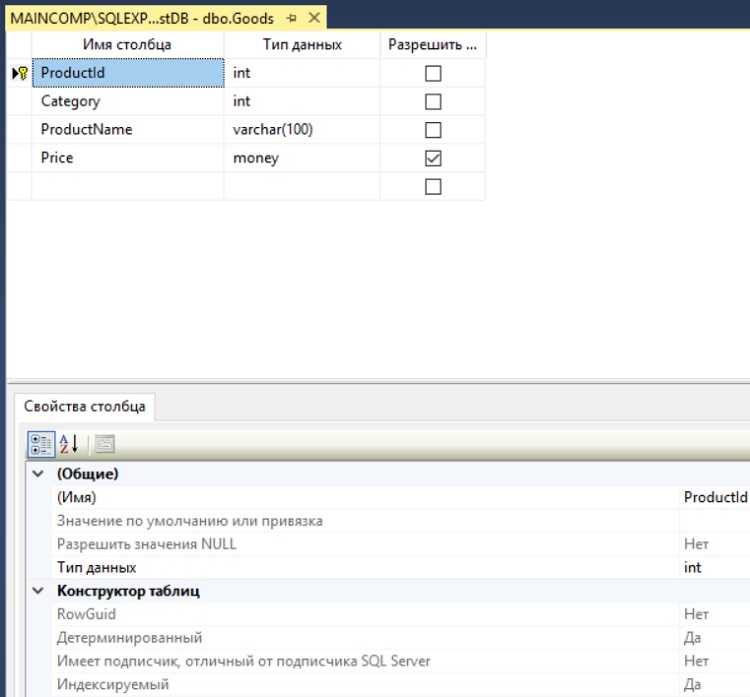
Команда ALTER TABLE позволяет изменить структуру существующей таблицы, включая добавление нового столбца. Ниже представлены конкретные шаги и рекомендации по использованию этой команды.
- Синтаксис:
ALTER TABLE имя_таблицы ADD имя_столбца тип_данных [ограничения]; - Пример:
ALTER TABLE employees ADD hire_date DATE NOT NULL DEFAULT CURRENT_DATE; - Тип данных должен быть выбран с учетом содержания столбца. Например, для даты –
DATE, для текста –VARCHARс указанием длины. - Ограничения, такие как
NOT NULLилиDEFAULT, указываются сразу при добавлении, чтобы не выполнять отдельные команды позже. - Если требуется добавить несколько столбцов, используйте множественные вызовы
ADDв одной команде:ALTER TABLE orders ADD order_status VARCHAR(20), ADD shipped BOOLEAN DEFAULT FALSE; - Для больших таблиц желательно выполнять добавление в периоды минимальной нагрузки, так как операция может блокировать запись.
- При использовании СУБД с проверкой схем (например, PostgreSQL), необходимо указывать значение по умолчанию для
NOT NULLстолбцов, иначе произойдет ошибка. - Перед применением изменений к продуктивной базе создавайте резервную копию и тестируйте на копии.
Назначение значения по умолчанию для нового поля
При добавлении нового поля в таблицу с уже существующими данными важно заранее определить значение по умолчанию. Это гарантирует согласованность данных и избавляет от необходимости явно указывать значение при вставке новых записей.
Чтобы установить значение по умолчанию, используйте оператор ALTER TABLE с ключевым словом DEFAULT. Например, добавление текстового поля с предустановленным значением выглядит так:
ALTER TABLE сотрудники ADD статус VARCHAR(20) DEFAULT 'активен';
Для числовых типов данных можно задать нулевое или иное начальное значение:
ALTER TABLE заказы ADD количество INT DEFAULT 1;
Если поле должно содержать дату и время, часто используют текущий момент:
ALTER TABLE действия ADD создано TIMESTAMP DEFAULT CURRENT_TIMESTAMP;
Значение по умолчанию особенно критично, если в таблице уже есть записи. Без него попытка добавить NOT NULL-столбец без дефолта вызовет ошибку, если не задать значение для каждой строки вручную. Чтобы избежать этого, всегда определяйте DEFAULT при добавлении обязательных полей.
После добавления можно проверить заданное значение с помощью запроса к INFORMATION_SCHEMA.COLUMNS или команды SHOW COLUMNS:
SHOW COLUMNS FROM сотрудники WHERE Field = 'статус';
Добавление поля с ограничением NOT NULL
Когда требуется добавить новое поле в таблицу SQL и обеспечить, чтобы в нем всегда было значение, используется ограничение NOT NULL. Это гарантирует, что запись в поле не может быть пустой или содержать значение NULL. Такой подход полезен, когда информация критически важна для работы приложения или базы данных.
Для добавления нового столбца с ограничением NOT NULL используется команда ALTER TABLE, которая позволяет изменять структуру существующих таблиц. При добавлении столбца с этим ограничением важно учитывать, что если таблица уже содержит данные, необходимо указать значение для нового поля для каждой существующей строки, иначе операция не будет выполнена.
Пример SQL-запроса для добавления столбца с ограничением NOT NULL и указанием дефолтного значения:
ALTER TABLE имя_таблицы
ADD COLUMN новое_поле тип_данных NOT NULL DEFAULT значение;В этом запросе:
имя_таблицы– название таблицы, к которой добавляется новый столбец;новое_поле– имя нового столбца;тип_данных– тип данных для нового столбца (например,INT,VARCHAR,DATEи т.д.);значение– значение по умолчанию, которое будет установлено для уже существующих строк.
Если значение по умолчанию не указано, то в зависимости от настроек базы данных запрос может завершиться ошибкой при наличии строк с пустыми значениями. В этом случае можно использовать оператор UPDATE для установки значений перед применением ограничения NOT NULL.
Пример установки дефолтного значения для нового столбца:
ALTER TABLE заказчики
ADD COLUMN email VARCHAR(255) NOT NULL DEFAULT 'example@example.com';После выполнения этого запроса столбец email будет добавлен в таблицу заказчики, и все существующие записи получат значение по умолчанию 'example@example.com'.
Важно: если в таблице уже есть строки, для которых новое поле может быть пустым, выполнение запроса без дефолтного значения вызовет ошибку. Чтобы избежать этого, либо установите значение по умолчанию, либо сначала обновите данные в таблице, а затем применяйте ограничение NOT NULL.
Влияние нового поля на существующие запросы
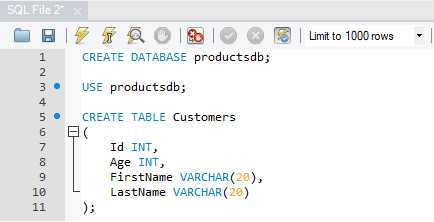
Добавление нового поля в таблицу SQL может оказать значительное влияние на выполнение существующих запросов. Прежде чем вносить изменения в структуру базы данных, важно учесть несколько факторов, которые могут повлиять на производительность и логику запросов.
1. Изменение структуры данных. Если новое поле добавляется в таблицу и не используется в запросах, оно может не повлиять напрямую на результат выполнения запросов. Однако в случае, когда запросы используют конкретные поля, добавление нового может потребовать изменений в запросах, чтобы избежать ошибок при попытке обращения к отсутствующему столбцу.
2. Неоптимизированные запросы. Старые запросы могут начать работать медленнее, если новое поле включается в SELECT или WHERE-условия без предварительной индексации. Например, если запросы теперь начинают учитывать дополнительное поле для фильтрации, поиск может стать более ресурсоемким, особенно если добавленное поле содержит большие объемы данных или NULL-значения.
3. Индексация нового поля. Без должной индексации добавленное поле может существенно замедлить выполнение запросов, если оно часто используется для фильтрации или сортировки данных. Рекомендуется проанализировать, как новое поле будет участвовать в запросах, и при необходимости создать индекс, чтобы улучшить производительность.
4. Изменения в агрегации данных. Если новые запросы начинают учитывать новое поле при вычислении агрегатных функций (например, COUNT, AVG), это может изменить логику отчетности. Простой добавлением поля в SELECT может изменить распределение данных или результат агрегации, если поле имеет значительное количество уникальных значений.
5. Риск нарушения совместимости. Если добавленное поле подразумевает обязательное значение (например, не допускает NULL), это может привести к ошибкам в существующих запросах, если они не учитывают новое обязательное условие. В случае работы с приложениями, которые напрямую взаимодействуют с базой данных, необходимо тщательно протестировать совместимость запросов с новыми ограничениями.
6. Использование старых индексов. Некоторые старые индексы могут больше не быть оптимальными после добавления нового поля. Это может привести к излишним операциям чтения или записи, если индекс на поле уже не отражает актуальную структуру запроса. Рекомендуется регулярно пересматривать стратегии индексации для сохранения производительности.
7. Обновление запросов в зависимости от контекста. Запросы, использующие старую структуру данных, могут требовать изменений в логике обработки, если новое поле вводит важные данные для бизнес-логики. Например, если поле указывает на тип или категорию данных, запросы могут потребовать дополнения фильтров, добавления JOIN-ов или новых условий сортировки.
8. Ретроспективное использование данных. В некоторых случаях добавление поля может потребовать пересмотра предыдущих запросов, которые не учитывали новое поле. Это особенно актуально для запросов, которые используют временные данные или отчеты, где новое поле может изменить результат анализа.
В целом, добавление нового поля в таблицу требует тщательной проверки всех запросов, которые могут быть затронуты. Важно оценить влияние на производительность, корректность данных и логику обработки, чтобы избежать ошибок и потери производительности в дальнейшем.
Проверка успешности добавления нового поля
После выполнения команды для добавления нового поля в таблицу SQL важно убедиться, что операция прошла успешно. Существует несколько методов для проверки корректности изменения структуры таблицы.
Первый и наиболее простой способ – это выполнить команду DESCRIBE или SHOW COLUMNS в MySQL. Эти команды отображают структуру таблицы, включая названия всех столбцов, их типы данных и другие параметры. Например, запрос:
DESCRIBE имя_таблицы;выведет информацию обо всех столбцах в таблице, и среди них должно быть видно только что добавленное поле. Это позволит убедиться, что оно существует с правильным типом данных и в нужной позиции.
В случае использования PostgreSQL аналогичный запрос выглядит так:
\d+ имя_таблицыТакже можно использовать запрос SELECT для проверки добавленного поля, например:
SELECT имя_столбца FROM имя_таблицы LIMIT 1;Этот запрос позволит убедиться, что поле не только добавлено в структуру таблицы, но и успешно доступно для выборки данных.
Другим методом является использование системных таблиц. В MySQL это можно сделать через запрос к INFORMATION_SCHEMA.COLUMNS, который содержит информацию о всех столбцах всех таблиц базы данных:
SELECT COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'имя_таблицы';В PostgreSQL аналогичная информация доступна в представлении pg_catalog.pg_attribute.
Кроме того, стоит проверять выполнение команды на наличие ошибок. Если база данных возвращает сообщение об ошибке, значит операция не прошла успешно, и нужно проверить синтаксис запроса или доступные права пользователя.
Для автоматизации проверки можно использовать скрипты или интегрированные средства управления базами данных (например, pgAdmin или MySQL Workbench), которые позволяют просматривать структуру таблиц и отслеживать изменения в реальном времени.