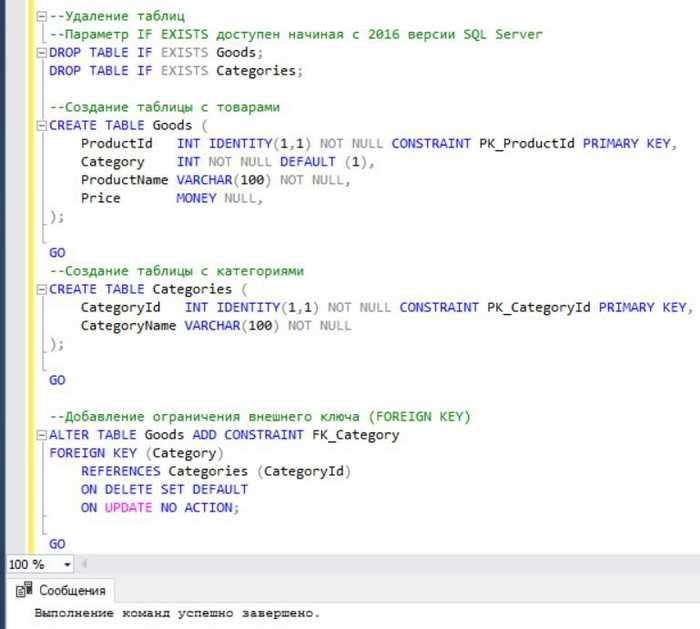
Добавление строки в таблицу – одна из базовых операций в SQL, но при этом требует чёткого понимания структуры таблицы, типов данных и ограничений. Команда INSERT INTO позволяет внести новую запись, указав конкретные столбцы и соответствующие значения. При работе с таблицей, содержащей обязательные поля без значения по умолчанию, их нужно указывать явно – иначе произойдёт ошибка выполнения.
Синтаксис команды следующий: INSERT INTO имя_таблицы (столбец1, столбец2, …) VALUES (значение1, значение2, …); Все значения должны строго соответствовать типам данных соответствующих столбцов. Например, попытка вставить текст в поле типа INTEGER вызовет исключение. Если какие-либо поля допускают NULL или имеют значения по умолчанию, их можно опустить в списке столбцов.
Важная рекомендация – всегда указывать список столбцов, даже если вы вставляете значения во все поля. Это повышает устойчивость к изменениям схемы таблицы. Также стоит избегать «магических значений» – вместо жёстко прописанных данных лучше использовать параметры, особенно в приложениях с пользовательским вводом.
Если таблица содержит автоинкрементное поле, обычно это первичный ключ, его не нужно указывать – СУБД присвоит значение автоматически. При работе с PostgreSQL или MySQL это поведение по умолчанию, но его можно переопределить вручную, если есть необходимость установить конкретный ID.
Подключение к базе данных с помощью SQL-клиента
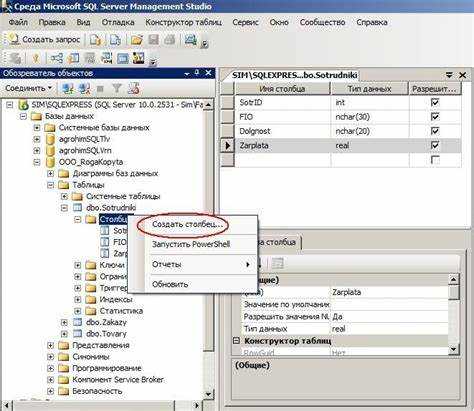
Для работы с базой данных через SQL-клиент необходимо установить подключение к серверу базы данных, используя соответствующие параметры: хост, порт, имя пользователя и пароль. В большинстве случаев SQL-клиенты предлагают удобные графические интерфейсы для настройки соединения, однако подключение можно также выполнить вручную через командную строку.
Прежде всего, нужно установить SQL-клиент, например, MySQL Workbench, DBeaver или pgAdmin для PostgreSQL. Эти инструменты поддерживают подключение к различным СУБД, что упрощает работу с базами данных. После установки откройте клиент и создайте новое подключение, указав тип базы данных (MySQL, PostgreSQL, SQLite и другие), а также параметры подключения.
Параметры подключения включают:
- Хост – это адрес сервера базы данных (например, 127.0.0.1 для локального подключения или доменное имя сервера).
- Порт – обычно для MySQL это порт 3306, для PostgreSQL – 5432. Уточните порт, если используется нестандартный.
- Имя пользователя – учетная запись, которая имеет права на выполнение SQL-запросов.
- Пароль – пароль для выбранного пользователя, обеспечивающий безопасность соединения.
- Имя базы данных – наименование базы данных, с которой планируется работать.
После ввода этих данных, подключение можно протестировать через клиентскую программу. Если подключение успешное, вы сможете начать выполнение запросов в контексте выбранной базы данных.
Для командной строки, например, для MySQL, подключение выполняется командой:
mysql -h [host] -u [username] -p
После этого вам будет предложено ввести пароль. В случае успешного ввода, вы получите доступ к консоли MySQL, где можно выполнять SQL-запросы.
Важно помнить о безопасности при подключении. Используйте защищённые каналы связи (например, SSH-туннели) при подключении к удалённым базам данных, особенно в производственной среде. Если возможно, ограничьте доступ к базе данных только с доверенных IP-адресов и настройте двухфакторную аутентификацию для пользователей.
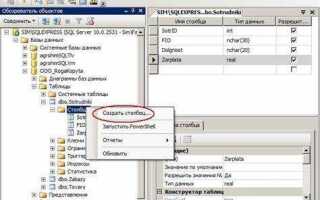
Определение структуры таблицы перед вставкой данных
Перед вставкой данных в таблицу SQL необходимо четко понимать её структуру. Это позволяет избежать ошибок, связанных с несовпадением типов данных или нарушением ограничений. Структура таблицы включает в себя не только типы данных для каждого столбца, но и возможные ограничения, такие как уникальность значений или обязательность заполнения.
1. Проверка схемы таблицы
Прежде чем добавить строку, полезно использовать команду DESCRIBE или SHOW COLUMNS, чтобы получить информацию о структуре таблицы. Эти команды позволяют увидеть имена столбцов, их типы данных, а также информацию об ограничениях, таких как NOT NULL или UNIQUE.
2. Типы данных
Каждый столбец в таблице имеет свой тип данных (например, VARCHAR, INT, DATE). Важно, чтобы данные, которые вы хотите вставить, соответствовали этим типам. Например, попытка вставить строковое значение в столбец типа INT вызовет ошибку. Также стоит учитывать размер поля для типов данных, таких как VARCHAR, чтобы избежать переполнения.
3. Ограничения на столбцы
Некоторые столбцы могут иметь ограничения, такие как NOT NULL (обязательность заполнения) или DEFAULT (значение по умолчанию). Если столбец имеет ограничение NOT NULL, при вставке данных обязательно нужно указать значение для этого столбца, иначе произойдёт ошибка. В случае ограничения DEFAULT можно опустить значение, и будет использовано значение по умолчанию.
4. Внешние ключи
Если таблица содержит внешние ключи (например, ссылается на другую таблицу), необходимо удостовериться, что вставляемое значение соответствует значению, уже существующему в связанной таблице. Нарушение целостности данных, такое как вставка несуществующего значения, вызовет ошибку.
5. Индексы и производительность
Вставка данных в таблицу, которая имеет индексы, может быть медленнее, чем в таблицу без индексов, особенно если индексы обновляются при каждой вставке. Если необходимо добавить большое количество данных, возможно, стоит временно отключить индексы и обновить их после вставки.
Четкое понимание структуры таблицы и её ограничений позволяет избежать ошибок и гарантировать корректность вставляемых данных.
Синтаксис INSERT INTO для одной строки
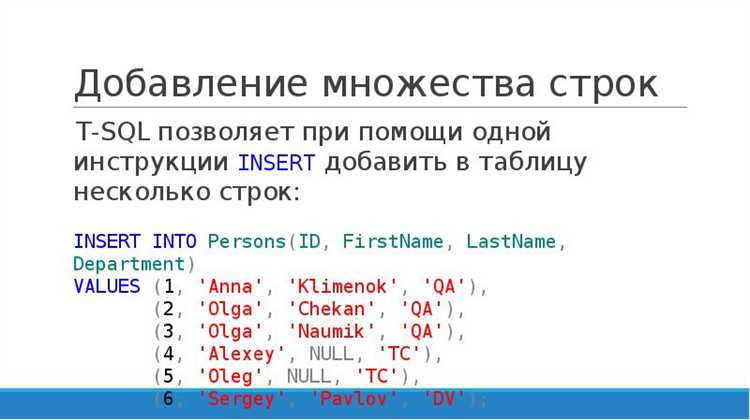
Для добавления одной строки в таблицу SQL используется команда INSERT INTO. Она требует указания названия таблицы, а также значений для всех колонок, которые необходимо заполнить. Если все колонки должны получить значения, можно воспользоваться следующим синтаксисом:
INSERT INTO имя_таблицы (колонка1, колонка2, колонка3, ...) VALUES (значение1, значение2, значение3, ...);
Важно, чтобы количество значений в части VALUES совпадало с количеством колонок, указанных в части INSERT INTO. Колонки перечисляются в том же порядке, в котором их значения будут переданы в VALUES.
Если значение для какой-либо колонки не требуется, можно использовать ключевое слово DEFAULT, если в таблице для этой колонки задано значение по умолчанию. Например:
INSERT INTO имя_таблицы (колонка1, колонка2) VALUES (значение1, DEFAULT);
Если колонки допускают NULL, можно явно передать NULL как значение:
INSERT INTO имя_таблицы (колонка1, колонка2) VALUES (значение1, NULL);
При работе с типами данных важно убедиться, что передаваемые значения соответствуют типам колонок таблицы, иначе запрос вернет ошибку. Например, строковые данные должны быть заключены в одинарные кавычки, а числовые значения – передаваться без кавычек.
Рекомендуется всегда явно указывать имена колонок при выполнении операции INSERT, даже если заполняются все колонки таблицы. Это повысит читаемость кода и уменьшит риск ошибок, особенно при добавлении новых колонок в таблицу в будущем.
Добавление строки с указанием всех столбцов
Чтобы добавить строку с указанием всех столбцов в таблицу SQL, необходимо точно перечислить каждый столбец в запросе. Это важный момент, потому что если таблица содержит столбцы с уникальными значениями или автоинкрементные поля, их нужно будет учесть при формировании запроса.
Пример SQL-запроса для добавления строки с указанием всех столбцов выглядит так:
INSERT INTO имя_таблицы (столбец1, столбец2, столбец3, ...) VALUES (значение1, значение2, значение3, ...);
В данном запросе необходимо указать имена всех столбцов, в которые будут вставляться данные. Порядок столбцов в списке должен соответствовать порядку значений в списке VALUES.
Если таблица содержит столбцы с автоинкрементом, например, для идентификатора, этот столбец не указывается в списке столбцов и значений. Например, если столбец id является автоинкрементным, запрос будет выглядеть так:
INSERT INTO имя_таблицы (столбец1, столбец2, столбец3) VALUES (значение1, значение2, значение3);
В случае с NULL значениями важно понимать, что SQL допускает вставку NULL в те столбцы, которые не имеют ограничения NOT NULL. Если нужно вставить значение по умолчанию, можно явно указать DEFAULT вместо конкретного значения:
INSERT INTO имя_таблицы (столбец1, столбец2, столбец3) VALUES (значение1, DEFAULT, значение3);
Если вы не уверены в наличии значений по умолчанию для столбцов, всегда уточняйте схему таблицы, чтобы избежать ошибок при вставке данных.
Добавление строки с указанием только нужных столбцов
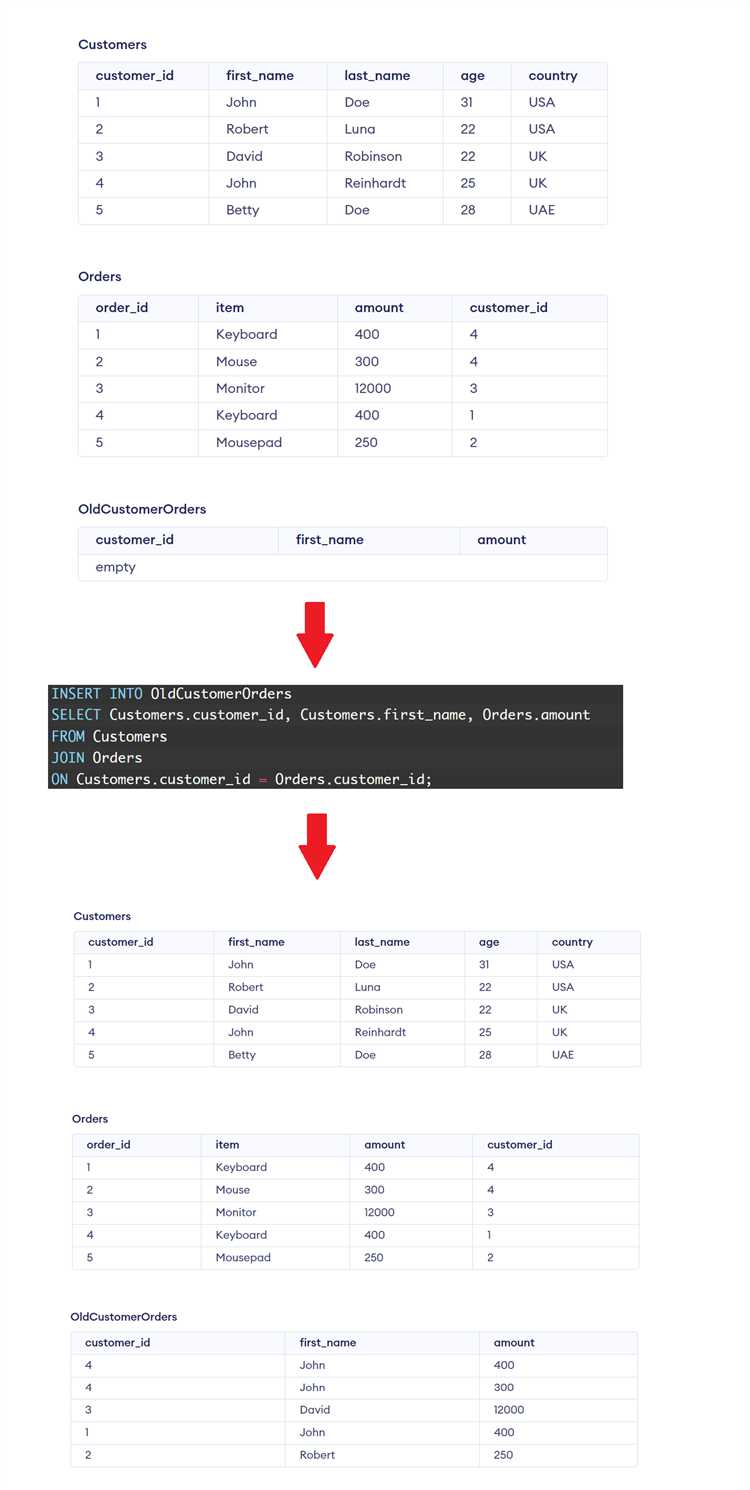
При добавлении данных в таблицу SQL часто возникает необходимость указать значения только для части столбцов. Это удобно, если некоторые поля имеют значения по умолчанию или не требуют обязательного заполнения. Такой подход позволяет упростить запросы и избежать лишних данных.
Для этого используется стандартный синтаксис оператора INSERT. Чтобы указать только необходимые столбцы, нужно перечислить их в части запроса после имени таблицы, а затем – соответствующие значения в VALUES.
Пример запроса, добавляющего данные только для некоторых столбцов:
INSERT INTO employees (first_name, last_name)
VALUES ('Иван', 'Иванов');
В данном случае значения добавляются только в столбцы first_name и last_name. Все остальные столбцы таблицы, такие как email, hire_date и другие, будут автоматически заполнены значениями по умолчанию или останутся NULL, если они допускают такую возможность.
Этот способ позволяет избежать ошибок и ненужного ввода данных, что упрощает код и повышает его читаемость.
Важно помнить, что если столбец не допускает NULL значений и не имеет значения по умолчанию, попытка выполнить запрос без указания значения для этого столбца вызовет ошибку. Поэтому перед выполнением запроса необходимо убедиться, что все обязательные поля указаны.
Вставка строки с использованием параметров в SQL-запросе
Когда вы хотите вставить данные в таблицу, используя параметры, структура запроса выглядит следующим образом:
INSERT INTO таблица (столбец1, столбец2, столбец3) VALUES (?, ?, ?);
Знак вопроса «?» является местозаполнителем для значений, которые будут подставлены в момент выполнения запроса. Это позволяет избежать ошибок, связанных с форматированием данных и делает запросы более безопасными.
Пример на языке программирования Python с использованием библиотеки SQLite:
import sqlite3
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# Пример данных для вставки
name = 'Иван'
age = 30
city = 'Москва'
# Выполнение параметризированного запроса
cursor.execute("INSERT INTO users (name, age, city) VALUES (?, ?, ?)", (name, age, city))
conn.commit()
conn.close()
Пример на языке программирования PHP с использованием MySQLi:
$mysqli = new mysqli("localhost", "user", "password", "database");
$name = "Иван";
$age = 30;
$city = "Москва";
// Подготовка запроса
$stmt = $mysqli->prepare("INSERT INTO users (name, age, city) VALUES (?, ?, ?)");
$stmt->bind_param("sis", $name, $age, $city); // "s" - строка, "i" - целое число
// Выполнение запроса
$stmt->execute();
$stmt->close();
$mysqli->close();
Важно:
- Использование параметров позволяет безопасно обрабатывать данные, предотвращая SQL-инъекции.
- Типы данных параметров должны точно соответствовать типам столбцов таблицы для предотвращения ошибок.
- Механизм параметризированных запросов оптимизирует работу с базой данных, так как запросы могут быть подготовлены и кэшированы сервером.
Для повышения безопасности важно всегда использовать параметры, а не вставлять значения напрямую в строку запроса. Это не только защищает вашу базу данных, но и помогает поддерживать код чистым и удобным для чтения.
Обработка ошибок при вставке дублирующих данных
При вставке данных в таблицу SQL важно учитывать возможность возникновения ошибок, связанных с дублированием записей. Наиболее часто это происходит, когда пытаемся вставить строку, которая нарушает уникальные ограничения (например, на первичный ключ или уникальный индекс). Для корректной обработки таких ситуаций существует несколько подходов, которые помогают избежать сбоев и минимизировать потери данных.
Одним из основных методов является использование оператора INSERT ... ON DUPLICATE KEY UPDATE в MySQL. Этот запрос позволяет не только вставить новые данные, но и обновить существующие, если возникает конфликт по уникальному ключу. Например, можно обновить поле, если вставляемая запись уже существует:
INSERT INTO users (id, name, email)
VALUES (1, 'John Doe', 'john.doe@example.com')
ON DUPLICATE KEY UPDATE name = VALUES(name), email = VALUES(email);Такой подход помогает поддерживать целостность данных без необходимости ручной проверки на дубли. Однако важно учитывать, что этот метод актуален только для баз данных, поддерживающих данный синтаксис, таких как MySQL и MariaDB.
В PostgreSQL аналогичную задачу можно решить с помощью оператора INSERT ... ON CONFLICT. Он позволяет указать столбцы, по которым происходит проверка на конфликт, и задавать поведение при его возникновении. В случае конфликта можно использовать DO NOTHING, чтобы просто пропустить вставку, либо DO UPDATE, чтобы обновить существующие данные:
INSERT INTO users (id, name, email)
VALUES (1, 'John Doe', 'john.doe@example.com')
ON CONFLICT (id)
DO UPDATE SET name = EXCLUDED.name, email = EXCLUDED.email;Если требуется избежать обработки ошибок на уровне самой базы данных, можно заранее выполнить проверку на существование записи. Для этого используют оператор SELECT для поиска возможных дубликатов. Если запись уже существует, можно пропустить вставку или выполнить обновление. Однако этот подход может быть менее эффективным, поскольку требует дополнительного запроса перед вставкой.
Важно помнить, что при работе с большими объемами данных подходы, не использующие встроенные возможности СУБД для обработки дубликатов, могут значительно снизить производительность из-за дополнительной нагрузки на сервер.
Для большинства случаев рекомендуется использовать механизмы, встроенные в СУБД, такие как ON DUPLICATE KEY UPDATE или ON CONFLICT, так как они позволяют обработать дубликаты с минимальными затратами ресурсов и обеспечивают надежность операций с данными.
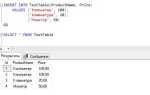
Проверка вставленной строки через SELECT-запрос
После того как вы добавили новую строку в таблицу SQL, важно убедиться, что операция прошла успешно. Для этого используйте SELECT-запрос, который позволит вам проверить наличие данных в таблице.
Один из самых простых способов – это выполнить запрос с условием, которое соответствует только что вставленной строке. Это может быть уникальный идентификатор или другое поле, по которому можно однозначно найти данные.
- Пример запроса для проверки по ID:
SELECT * FROM название_таблицы WHERE id = 123;
Если строка была успешно добавлена, запрос вернет эту запись. В противном случае результат будет пустым.
В случае вставки нескольких строк, вы можете использовать более общий запрос, который возвращает последние добавленные записи:
- Пример запроса для последних добавленных строк:
SELECT * FROM название_таблицы ORDER BY дата_добавления DESC LIMIT 5;
Этот запрос покажет пять последних записей, что позволит вам быстро проверить добавление новых данных.
Если добавление данных происходило с помощью транзакции, не забудьте подтвердить изменения командой COMMIT перед выполнением SELECT-запроса. В противном случае изменения могут быть отменены при откате транзакции.
Также полезно проверять не только данные, но и количество строк, которые были добавлены:
- Пример запроса для подсчета строк:
SELECT COUNT(*) FROM название_таблицы WHERE условие;
Это поможет убедиться, что добавлена именно нужная запись или несколько записей.
Вопрос-ответ:
Какие данные можно добавлять в таблицу SQL?
В таблицу SQL можно добавить любые данные, которые соответствуют типам данных, определённым для столбцов таблицы. Это могут быть текстовые строки, числа, даты, булевы значения и даже бинарные данные (например, изображения). Важно соблюдать соответствие между типами данных столбцов и значениями, которые вы хотите вставить. Например, если столбец определён как `INT`, то в него нельзя добавить строку текста, только целое число.