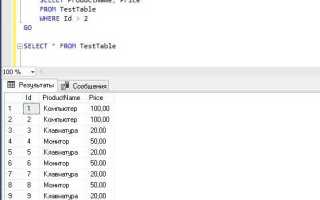
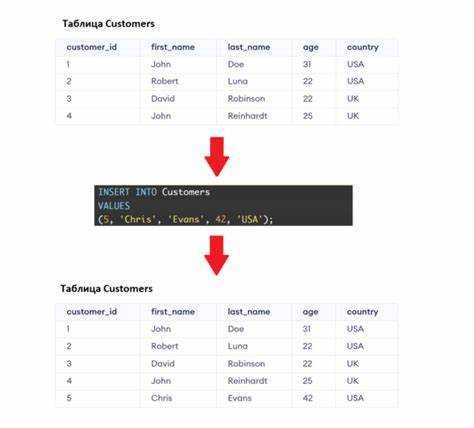
Работа с базами данных требует чёткого понимания синтаксиса SQL и структуры таблиц. Добавление новой строки – базовая, но критически важная операция, при неправильном выполнении которой возможны логические ошибки, нарушения ограничений целостности или снижение производительности. Основной инструмент – оператор INSERT, однако его применение требует учета множества факторов: от наличия уникальных ключей до автогенерируемых значений и ограничений NOT NULL.
При вставке данных в таблицу с автоинкрементным первичным ключом, важно не указывать этот столбец вручную, чтобы избежать конфликтов. Например, в PostgreSQL или MySQL корректный синтаксис будет выглядеть как INSERT INTO users (name, email) VALUES (‘Иван’, ‘ivan@example.com’); – при этом столбец id, определённый как SERIAL или AUTO_INCREMENT, заполнится автоматически.
Если таблица использует внешние ключи, необходимо убедиться, что добавляемое значение уже существует в родительской таблице. Иначе команда завершится ошибкой нарушения ограничений связности. Это особенно актуально при миграции данных или пакетной вставке, когда порядок операций критичен.
Для массового добавления строк предпочтительно использовать множественные значения в одном операторе INSERT: INSERT INTO products (name, price) VALUES (‘Товар1’, 100), (‘Товар2’, 150);. Такой подход снижает нагрузку на сервер по сравнению с выполнением множества одиночных запросов и сокращает общее время вставки.
Подготовка структуры таблицы для вставки данных

Перед добавлением данных в таблицу необходимо правильно подготовить её структуру. На этом этапе важно определить типы данных для каждого столбца, а также учесть возможные ограничения для обеспечения целостности данных.
Первое, на что стоит обратить внимание – это выбор подходящих типов данных для каждого столбца. Например, если столбец будет хранить текстовую информацию, следует использовать типы данных, такие как VARCHAR или TEXT, в зависимости от предполагаемого объёма данных. Для хранения числовых значений лучше подойдут типы INT или DECIMAL. Для дат и времени – типы DATE и DATETIME.
Необходимо также учитывать ограничения на данные. Часто для обеспечения целостности информации добавляются такие ограничения, как NOT NULL, чтобы исключить пустые значения, и UNIQUE, если значения в столбце должны быть уникальными. Важно правильно спланировать использование индексов, чтобы ускорить поиск по таблице.
Кроме того, для связей между таблицами стоит использовать внешние ключи. Это обеспечит согласованность данных, предотвращая их удаление или изменение, если на них ссылаются другие таблицы. Внешний ключ всегда должен указывать на существующие значения в другой таблице, что требует соблюдения правильных отношений.
Если требуется автоматическое обновление или удаление данных при изменении или удалении записей в связанных таблицах, следует использовать каскадные операции – ON UPDATE CASCADE и ON DELETE CASCADE.
После этого стоит настроить индексы для столбцов, которые будут часто использоваться в поисковых запросах. Это повысит производительность при добавлении новых строк и при извлечении данных.
Завершающим этапом является проверка структуры таблицы с учётом всех добавленных ограничений и индексов, чтобы убедиться в отсутствии конфликтов и несоответствий типам данных.
Формат команды INSERT INTO с указанием всех столбцов
Команда INSERT INTO используется для добавления новых строк в таблицу базы данных. При использовании формата с указанием всех столбцов важно соблюдать точный порядок и количество столбцов, чтобы избежать ошибок при вставке данных.
Когда необходимо вставить данные в таблицу, можно явно указать все столбцы, в которые будут записаны значения. Это позволяет минимизировать шанс ошибки, так как каждый столбец будет соответствовать своему значению.
Структура команды выглядит следующим образом:
INSERT INTO имя_таблицы (столбец1, столбец2, столбец3, ...)
VALUES (значение1, значение2, значение3, ...);В этом формате важно соблюдать следующие моменты:
- Порядок столбцов и значений. Порядок значений в списке
VALUESдолжен точно соответствовать порядку столбцов в списке послеINSERT INTO имя_таблицы. Нарушение этого порядка приведет к ошибке. - Количество значений. Количество значений в списке
VALUESдолжно быть равно количеству столбцов, указанных послеINSERT INTO. - Типы данных. Для каждого столбца необходимо указать значение соответствующего типа данных. Например, если столбец ожидает числовое значение, то текстовое значение приведет к ошибке.
- Явное указание столбцов. Когда вы явно указываете все столбцы, вам не нужно беспокоиться о порядке их добавления в таблицу. Это особенно полезно, если структура таблицы изменяется, так как не нужно будет модифицировать саму команду, если количество столбцов в таблице увеличится или уменьшится.
Пример:
INSERT INTO employees (id, first_name, last_name, hire_date)
VALUES (101, 'Иван', 'Иванов', '2025-04-24');В данном примере строка данных (101, ‘Иван’, ‘Иванов’, ‘2025-04-24’) добавляется в таблицу employees, и каждое значение соответствует одному из столбцов, указанным в списке.
Этот формат особенно полезен в случае, когда структура таблицы может измениться или если требуется вставить данные в таблицу с большим количеством столбцов. Указание всех столбцов минимизирует вероятность ошибок и делает команду более читаемой.
Добавление строки без указания всех столбцов таблицы
В SQL можно вставить строку в таблицу, указав значения только для некоторых столбцов, оставив другие столбцы с их значениями по умолчанию или с NULL. Это удобный способ, когда не требуется заполнять всю информацию или когда некоторые поля могут быть автоматически обработаны.
Для выполнения такой операции используется стандартный синтаксис команды INSERT, где в списке столбцов можно пропустить некоторые из них. Пример запроса:
INSERT INTO имя_таблицы (столбец_1, столбец_2) VALUES (значение_1, значение_2);
В данном случае столбцы, не указанные в запросе, примут значения по умолчанию или NULL, если они допускают такие значения. Если для столбца задано значение по умолчанию, оно будет автоматически подставлено при отсутствии явного значения в запросе.
Важно помнить, что использование данного подхода имеет ограничения. Столбцы, которые не допускают NULL и не имеют значения по умолчанию, должны быть обязательно указаны при вставке строки. Если вы забудете указать такие столбцы, SQL вернет ошибку.
Также стоит учитывать, что многие базы данных поддерживают автоматическое заполнение некоторых полей. Например, столбец с автоинкрементом (например, идентификатор записи) можно не указывать в запросе, так как его значение будет сгенерировано автоматически.
Рекомендуется использовать этот подход с осторожностью, особенно в случае сложных таблиц с большим количеством обязательных столбцов или если структура таблицы часто меняется. В таких случаях может быть проще явно указывать все столбцы, чтобы избежать ошибок при изменении схемы базы данных.
Вставка нескольких строк за одну команду
Для эффективного добавления нескольких строк в таблицу SQL можно использовать конструкцию INSERT INTO … VALUES, которая позволяет вставить несколько записей за один запрос. Это не только ускоряет выполнение операций, но и уменьшает нагрузку на базу данных, минимизируя количество транзакций.
Синтаксис команды выглядит следующим образом:
INSERT INTO имя_таблицы (колонка1, колонка2, ...)
VALUES (значение1_1, значение1_2, ...),
(значение2_1, значение2_2, ...),
(значение3_1, значение3_2, ...);Каждое значение в скобках представляет собой одну строку данных, а каждое подмножество значений в скобках соответствует одному набору колонок для вставки. Важно помнить, что количество значений в каждой строке должно соответствовать количеству колонок в таблице, если они не имеют значений по умолчанию или не допускают NULL.
Пример:
INSERT INTO сотрудники (id, имя, должность, зарплата)
VALUES (1, 'Иванов И.И.', 'Менеджер', 50000),
(2, 'Петрова М.С.', 'Разработчик', 60000),
(3, 'Сидоров В.А.', 'Аналитик', 55000);Этот запрос добавляет сразу три записи в таблицу сотрудники. В отличие от нескольких отдельных команд INSERT, один запрос на несколько строк обрабатывается быстрее и с меньшими затратами ресурсов.
Рекомендуется использовать вставку нескольких строк в одном запросе, когда количество данных значительное, но не настолько велико, чтобы потребовать загрузки через специализированные инструменты или механизмы импорта данных.
Важно: Некоторые базы данных могут ограничивать максимальное количество строк в одном запросе, и в этом случае вставка слишком большого числа строк за один раз может привести к ошибке. Например, в MySQL это ограничение по умолчанию составляет 1000 строк. При необходимости вставки больших объемов данных следует использовать механизмы пакетной обработки или инструменты импорта.
Для улучшения производительности рекомендуется использовать транзакции, чтобы гарантировать атомарность операции и избежать неполных вставок в случае ошибки. Например:
START TRANSACTION;
INSERT INTO сотрудники (id, имя, должность, зарплата)
VALUES (1, 'Иванов И.И.', 'Менеджер', 50000),
(2, 'Петрова М.С.', 'Разработчик', 60000);
COMMIT;Таким образом, если операция вставки не удастся, изменения можно откатить без ущерба для целостности данных.
Использование значения по умолчанию и NULL при вставке
При добавлении новой строки в таблицу SQL важно учитывать два механизма: значения по умолчанию и NULL. Оба они могут влиять на поведение записи, если данные для определённых полей не были указаны явно.
Для начала, стоит понять различие между этими двумя подходами:
- Значение по умолчанию – это заранее заданное значение, которое будет использоваться для столбца, если при вставке данных для этого столбца не указано никакое значение.
- NULL – это отсутствие значения. Если поле допускает NULL, то при вставке данных без значения для этого поля, база данных сохраняет NULL, что может быть интерпретировано как «неизвестное» или «не определённое» значение.
Если столбец имеет значение по умолчанию, его можно опустить при вставке данных, и база автоматически подставит это значение. Это удобно, если часто используется одно и то же значение для большинства записей, например, дата создания или статус записи. Однако стоит учитывать следующее:
- Тип данных столбца. Для некоторых типов данных, например, для числовых полей, значение по умолчанию может быть 0, а для строковых – пустая строка или специфическая метка, например, «не указано».
- Использование DEFAULT. В SQL для явного указания значения по умолчанию при вставке используется ключевое слово DEFAULT. Пример:
INSERT INTO employees (name, hire_date)
VALUES ('Иванов', DEFAULT);
Если в таблице указано значение по умолчанию для поля hire_date, то при вставке записи с использованием DEFAULT будет использовано это значение.
NULL, в свою очередь, часто используется, когда значения для столбца ещё нет или они не применимы. Например, поле «дата окончания контракта» может быть NULL, если контракт ещё не завершён. Чтобы вставить NULL в столбец, достаточно просто опустить его из списка значений или использовать явное указание NULL:
INSERT INTO employees (name, contract_end_date)
VALUES ('Иванов', NULL);
Важно помнить, что не все столбцы могут содержать NULL. Для столбцов, где указано ограничение NOT NULL, попытка вставить NULL вызовет ошибку. Поэтому перед вставкой данных следует проверять схему таблицы и типы столбцов.
Рекомендации при использовании значений по умолчанию и NULL:
- Не стоит злоупотреблять NULL, если можно использовать значение по умолчанию, особенно для обязательных полей. Это улучшит читаемость данных.
- Используйте значение по умолчанию для часто встречающихся и стандартных значений, таких как текущее время, стандартный статус или флаг активности.
- Всегда проверяйте, поддерживает ли столбец NULL, и правильно обрабатывайте такие случаи в вашем приложении или запросах.
Правильное использование значений по умолчанию и NULL позволяет повысить гибкость работы с базой данных и улучшить управляемость данных.
Добавление данных из другой таблицы через SELECT
Для добавления данных из одной таблицы в другую с помощью SQL-запроса, используется конструкция INSERT INTO в сочетании с SELECT. Это позволяет не только добавить строки, но и получить данные из другой таблицы, при необходимости применяя фильтры или объединяя таблицы. Важно, чтобы структура таблиц совпадала по числу и типу столбцов.
Основной синтаксис запроса выглядит следующим образом:
INSERT INTO таблица_назначения (столбец1, столбец2, ...) SELECT столбец1, столбец2, ... FROM таблица_источник WHERE условие;
Пример запроса: если требуется добавить в таблицу `orders` данные о клиентах из таблицы `clients`, то запрос будет выглядеть так:
INSERT INTO orders (client_id, order_date, total) SELECT id, registration_date, total_spent FROM clients WHERE total_spent > 1000;
В этом примере из таблицы `clients` выбираются только те клиенты, которые потратили более 1000, и их данные добавляются в таблицу `orders`.
При работе с такими запросами важно помнить о нескольких моментах:
- Типы данных в столбцах обеих таблиц должны быть совместимыми. Например, столбец, в который вставляются данные, должен поддерживать тип данных, соответствующий значениям, выбранным из другой таблицы.
- Если в таблице назначения есть обязательные поля, для которых не предусмотрены значения в запросе, необходимо либо указать их в запросе, либо обеспечить, чтобы они получали значения по умолчанию.
- Если вы объединяете данные из нескольких таблиц, используйте операторы JOIN для связывания таблиц.
Кроме того, важно использовать оператор WHERE для ограничения данных, чтобы избежать вставки лишних или некорректных записей. Это особенно важно при работе с большими объемами данных, чтобы минимизировать нагрузку на систему.
Пример с объединением таблиц:
INSERT INTO orders (client_id, order_date, total) SELECT c.id, NOW(), o.amount FROM clients c JOIN orders o ON c.id = o.client_id WHERE c.status = 'active' AND o.status = 'completed';
Здесь данные из таблиц `clients` и `orders` объединяются через JOIN, и добавляются только те записи, где клиенты активны и заказы завершены.
Использование SELECT для добавления данных позволяет гибко управлять процессом вставки и минимизировать количество повторяющихся операций при работе с большими и взаимосвязанными данными.
Обработка ошибок при попытке вставки дубликатов
При вставке данных в таблицу SQL часто возникает необходимость обработки ошибок, связанных с дублированием уникальных значений. Например, если в таблице есть столбец с ограничением уникальности (например, уникальный индекс или первичный ключ), попытка вставки строки с уже существующим значением в этот столбец приведет к ошибке. Для таких случаев разработаны механизмы, которые позволяют контролировать поведение при возникновении таких ошибок.
Одним из способов предотвращения ошибок дублирования является использование оператора INSERT ... ON DUPLICATE KEY UPDATE (в MySQL) или INSERT ... ON CONFLICT (в PostgreSQL). Эти операторы позволяют, вместо того чтобы завершить выполнение с ошибкой, обновить уже существующую строку с теми значениями, которые не являются уникальными. Такой подход экономит ресурсы и позволяет избежать конфликтов при вставке.
Для примера, в MySQL запрос может выглядеть так:
INSERT INTO users (id, name, email)
VALUES (1, 'Иван Иванов', 'ivan@mail.com')
ON DUPLICATE KEY UPDATE name = 'Иван Иванов', email = 'ivan@mail.com';Здесь, если строка с таким id уже существует, то произойдёт обновление значений в строке, а не ошибка дублирования.
Для PostgreSQL аналогичный запрос будет иметь вид:
INSERT INTO users (id, name, email)
VALUES (1, 'Иван Иванов', 'ivan@mail.com')
ON CONFLICT (id) DO UPDATE SET name = 'Иван Иванов', email = 'ivan@mail.com';Если же не требуется обновлять значения, можно использовать IGNORE в MySQL, что приведёт к игнорированию попытки вставки дубликата:
INSERT IGNORE INTO users (id, name, email)
VALUES (1, 'Иван Иванов', 'ivan@mail.com');Этот запрос не вызовет ошибку, если строка с таким id уже существует, и просто пропустит вставку.
Другим способом предотвращения ошибок является предварительная проверка данных на наличие дубликатов перед выполнением вставки. Для этого можно использовать запрос SELECT, чтобы убедиться, что данные ещё не существуют в таблице, прежде чем вставлять новые значения. Этот метод требует дополнительных операций, но может быть полезен в случаях, когда необходимо точно контролировать логику вставки и обновления данных.
Для эффективного контроля за дубликатами важно также правильно настраивать уникальные индексы в таблицах, чтобы минимизировать возможность ошибок и повысить производительность запросов.
Проверка успешного добавления строки в таблицу
После выполнения SQL-запроса на добавление строки в таблицу важно убедиться, что операция прошла успешно. Это можно сделать несколькими способами, каждый из которых зависит от используемой СУБД и инструментов взаимодействия с базой данных.
Для начала можно использовать SQL-запросы для проверки наличия добавленных данных. Один из самых распространённых подходов – это выполнение SELECT-запроса, который ищет добавленную строку по уникальным значениям или ключам. Например:
SELECT * FROM users WHERE user_id = 123;Этот запрос вернёт все данные пользователя с ID 123, если добавление прошло успешно. Если строка не найдена, значит, операция не удалась.
В некоторых случаях для повышения надёжности можно использовать встроенные механизмы СУБД, такие как проверка значения, возвращаемого функцией вставки. Например, в MySQL можно использовать функцию LAST_INSERT_ID(), которая возвращает последний идентификатор, добавленный в таблицу. Важно, чтобы этот идентификатор был уникальным для каждой строки, добавляемой в таблицу. Пример запроса:
SELECT LAST_INSERT_ID();Ещё один подход – это проверка кода ошибки или статуса операции. В большинстве СУБД можно получить код состояния запроса. Если код успешного выполнения равен 0 или аналогичному значению в вашей СУБД, значит, добавление прошло без ошибок. Например, для PostgreSQL используется команда:
SELECT pg_last_notice();Использование транзакций также помогает гарантировать, что добавление строки прошло успешно. Например, в PostgreSQL можно использовать команду COMMIT, которая фиксирует изменения в базе данных, или ROLLBACK для отмены изменений в случае ошибки.
Наконец, можно комбинировать методы. Например, после вставки строки можно выполнить SELECT-запрос, чтобы убедиться, что данные действительно были добавлены, и в случае отсутствия строк выполнить возврат ошибки или логирование для дальнейшего анализа.
Вопрос-ответ:
Какие ограничения могут возникнуть при добавлении строки в таблицу SQL?
При добавлении строки в таблицу могут возникнуть несколько типов ограничений. Во-первых, если в таблице есть ограничение уникальности (например, уникальный индекс), то попытка вставить строку с дублирующимися значениями вызовет ошибку. Также могут быть проблемы с ограничениями целостности, такими как внешние ключи (если данные в новой строке не соответствуют данным в другой таблице). Еще одним ограничением является тип данных столбцов: если тип вставляемого значения не совпадает с типом столбца, будет выведена ошибка.