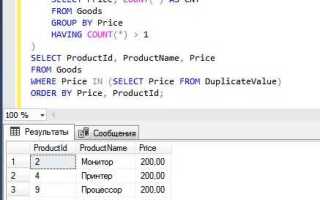
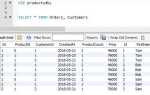
Подсчёт повторяющихся значений в SQL полезен при анализе данных, поиске дубликатов и выявлении аномалий. Основной инструмент для этого – агрегатная функция COUNT() в сочетании с GROUP BY.
Чтобы получить количество повторяющихся значений в конкретном столбце, используется конструкция:
SELECT столбец, COUNT(*) FROM таблица GROUP BY столбец HAVING COUNT(*) > 1;
Ключевое условие – HAVING COUNT(*) > 1, которое отфильтровывает только те значения, которые встречаются более одного раза. Если нужно учесть дополнительные фильтры, добавляется WHERE перед GROUP BY.
Для подсчёта повторов по нескольким столбцам указываются все необходимые поля в GROUP BY. Например:
SELECT поле1, поле2, COUNT(*) FROM таблица GROUP BY поле1, поле2 HAVING COUNT(*) > 1;
Если требуется просто узнать, сколько раз встречается каждое значение, без фильтрации, можно опустить HAVING:
SELECT столбец, COUNT(*) FROM таблица GROUP BY столбец;
Для упорядочивания результата по количеству повторений добавляется ORDER BY COUNT(*) DESC, что позволяет быстро определить самые частые значения.
Как найти дубликаты в одном столбце с помощью GROUP BY
Для поиска повторяющихся значений в одном столбце используется оператор GROUP BY в сочетании с агрегатной функцией COUNT(). Запрос позволяет выявить все значения, которые встречаются более одного раза.
Пример для таблицы users со столбцом email:
SELECT email, COUNT(*) AS count
FROM users
GROUP BY email
HAVING COUNT(*) > 1;Этот запрос сгруппирует записи по адресу электронной почты и отфильтрует только те, которые встречаются два раза и более. Колонка count покажет точное количество повторений.
Если важно исключить пустые значения, добавьте условие WHERE email IS NOT NULL:
SELECT email, COUNT(*) AS count
FROM users
WHERE email IS NOT NULL
GROUP BY email
HAVING COUNT(*) > 1;Для ускорения выполнения на больших объёмах данных рекомендуется создать индекс на проверяемом столбце:
CREATE INDEX idx_email ON users(email);После выполнения запроса можно использовать полученный список дубликатов для удаления, анализа или объединения данных.
Как посчитать количество повторений каждого значения
Чтобы получить количество повторений каждого значения в столбце, используется конструкция GROUP BY в сочетании с агрегатной функцией COUNT(). Запрос показывает, сколько раз каждое уникальное значение встречается в выбранной колонке.
Пример запроса:
SELECT имя_столбца, COUNT(*) AS количество
FROM имя_таблицы
GROUP BY имя_столбца;
Если нужно отсортировать результат по убыванию количества, добавляется ORDER BY COUNT(*) DESC:
SELECT имя_столбца, COUNT(*) AS количество
FROM имя_таблицы
GROUP BY имя_столбца
ORDER BY COUNT(*) DESC;
Фильтрация по количеству возможна через HAVING. Например, чтобы выбрать только те значения, которые встречаются более одного раза:
SELECT имя_столбца, COUNT(*) AS количество
FROM имя_таблицы
GROUP BY имя_столбца
HAVING COUNT(*) > 1;
Для подсчёта повторений с учётом нескольких столбцов, используется группировка по нескольким полям:
SELECT столбец1, столбец2, COUNT(*) AS количество
FROM имя_таблицы
GROUP BY столбец1, столбец2;
Как отфильтровать только те значения, которые повторяются

Для выборки только дублирующихся значений используется конструкция GROUP BY с агрегатной функцией COUNT() и фильтрацией через HAVING. Это позволяет исключить уникальные записи и оставить только те, которые встречаются более одного раза.
Пример: чтобы получить все дублирующиеся имена из таблицы users, запрос будет выглядеть так:
SELECT name FROM users GROUP BY name HAVING COUNT(*) > 1;
Если необходимо вывести не только дублирующееся значение, но и общее количество повторений, используется:
SELECT name, COUNT(*) as total FROM users GROUP BY name HAVING COUNT(*) > 1;
Чтобы отфильтровать повторяющиеся строки по нескольким столбцам, например first_name и last_name, нужно сгруппировать сразу по обоим:
SELECT first_name, last_name FROM users GROUP BY first_name, last_name HAVING COUNT(*) > 1;
Если требуется использовать такие данные в подзапросе для получения полной информации о дублирующихся строках, используется соединение с исходной таблицей:
SELECT * FROM users WHERE (name) IN (SELECT name FROM users GROUP BY name HAVING COUNT(*) > 1);
Такие запросы работают стабильно при наличии индексов по участвующим столбцам. Без индексов возможны потери производительности на больших объёмах данных.
Как учитывать NULL при подсчёте повторяющихся значений
NULL в SQL не считается значением, поэтому при использовании GROUP BY и COUNT() его поведение отличается от обычных данных. По умолчанию COUNT(столбец) игнорирует NULL, а COUNT(*) учитывает все строки, включая те, где значение отсутствует.
Чтобы учесть количество повторов, включая NULL, используйте GROUP BY с IS NULL. Пример:
SELECT
CASE
WHEN column_name IS NULL THEN 'NULL'
ELSE column_name
END AS value_group,
COUNT(*) AS occurrences
FROM table_name
GROUP BY
CASE
WHEN column_name IS NULL THEN 'NULL'
ELSE column_name
END;Такой подход позволяет видеть, сколько раз встречается отсутствие значения. Если важно различать NULL и пустую строку, используйте явное сравнение column_name IS NULL и column_name = » отдельно. Для подсчёта только NULL:
SELECT COUNT(*) FROM table_name WHERE column_name IS NULL;Если задача – найти все значения, которые встречаются более одного раза, включая NULL как отдельную категорию, используйте:
SELECT
value_group,
COUNT(*) AS occurrences
FROM (
SELECT
CASE
WHEN column_name IS NULL THEN 'NULL'
ELSE column_name
END AS value_group
FROM table_name
) AS grouped
GROUP BY value_group
HAVING COUNT(*) > 1;В агрегатных функциях следует помнить: COUNT(DISTINCT column_name) не включает NULL, и если необходимо его учесть, потребуется предварительная замена на строку-заменитель с помощью COALESCE().
Как посчитать дубликаты по нескольким столбцам
Для подсчёта количества дубликатов по нескольким столбцам используется оператор GROUP BY в сочетании с HAVING COUNT(*) > 1. Это позволяет выделить группы строк с одинаковыми значениями в указанных полях.
Пример запроса для таблицы orders, где нужно найти повторяющиеся комбинации значений в столбцах customer_id и order_date:
SELECT customer_id, order_date, COUNT(*) AS count
FROM orders
GROUP BY customer_id, order_date
HAVING COUNT(*) > 1;Запрос вернёт только те сочетания customer_id и order_date, которые встречаются более одного раза. Колонка count покажет, сколько раз каждая комбинация повторяется.
Для поиска полных дубликатов, включающих все поля таблицы, можно использовать:
SELECT *, COUNT(*) AS count
FROM orders
GROUP BY customer_id, order_date, product_id, quantity
HAVING COUNT(*) > 1;Если необходимо удалить дубликаты, оставив одну строку, используется ROW_NUMBER() в CTE или подзапросе. Пример:
WITH ranked AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY customer_id, order_date ORDER BY id) AS rn
FROM orders
)
DELETE FROM orders
WHERE id IN (
SELECT id FROM ranked WHERE rn > 1
);Здесь id – уникальный идентификатор строки. Такой подход безопасен для удаления повторов, при этом одна строка из каждой группы остаётся.
Как отсортировать результаты по количеству повторений
Чтобы получить упорядоченный список повторяющихся значений, используется конструкция GROUP BY с COUNT() и сортировка через ORDER BY. Такой подход позволяет определить, какие значения встречаются чаще остальных.
- Сгруппировать данные по интересующему столбцу:
GROUP BY имя_столбца. - Посчитать количество повторений:
COUNT(*) AS количество. - Отсортировать результат:
ORDER BY количество DESC– для убывающего порядка илиASC– для возрастающего.
Пример для таблицы users и столбца city:
SELECT city, COUNT(*) AS количество
FROM users
GROUP BY city
ORDER BY количество DESC;Если необходимо учитывать только значения с количеством больше одного, добавляется фильтр через HAVING:
SELECT city, COUNT(*) AS количество
FROM users
GROUP BY city
HAVING COUNT(*) > 1
ORDER BY количество DESC;Для ускорения таких запросов рекомендуется создавать индекс на поле, по которому происходит группировка.
Как использовать подзапросы для работы с повторяющимися значениями
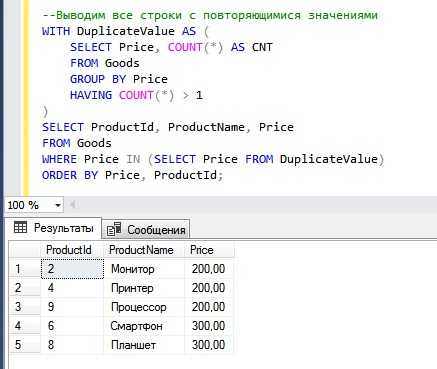
Подзапросы позволяют изолировать набор повторяющихся значений и использовать его в основном выражении. Один из распространённых подходов – применение подзапроса в секции FROM для предварительного подсчёта повторов с группировкой.
Пример: требуется найти имена клиентов, которые встречаются более одного раза в таблице clients.
SELECT name
FROM (SELECT name, COUNT(*) AS cnt FROM clients GROUP BY name) AS t
WHERE t.cnt > 1;
Во внутреннем подзапросе значения агрегируются по полю name, а внешнее выражение фильтрует только те строки, где количество превышает 1. Такой подход изолирует агрегацию от фильтрации, исключая необходимость повторения логики.
Если требуется вернуть не только имя, но и другие поля из основной таблицы, можно использовать подзапрос в WHERE с оператором IN:
SELECT *
FROM clients
WHERE name IN (SELECT name FROM clients GROUP BY name HAVING COUNT(*) > 1);
Этот способ удобен при работе с исходными данными без изменения структуры выборки. Подзапрос определяет, какие значения считаются дублирующимися, а основное выражение возвращает полную информацию по ним.
При больших объёмах данных вложенные запросы следует комбинировать с индексами по столбцам группировки, чтобы сократить время выполнения. Также рекомендуется использовать EXISTS вместо IN, если нужно проверить само наличие повторов, а не извлекать список значений.
SELECT *
FROM clients c
WHERE EXISTS (
SELECT 1 FROM clients c2
WHERE c.name = c2.name AND c.id <> c2.id
);
Этот метод позволяет отобрать все строки, у которых есть дубликаты по имени, исключая саму строку из проверки. Он особенно полезен для поиска точных совпадений с различными идентификаторами.
Вопрос-ответ:
Что такое `HAVING` в SQL и почему его нужно использовать для подсчета повторяющихся значений?
Ключевое слово `HAVING` используется для фильтрации результатов, полученных после применения агрегатных функций, таких как `COUNT()`. В отличие от `WHERE`, которое фильтрует строки до применения агрегатных функций, `HAVING` работает с уже агрегированными данными. Например, если вы хотите отфильтровать значения, которые повторяются больше одного раза, нужно использовать `HAVING COUNT(*) > 1`.
Можно ли посчитать количество повторяющихся значений без использования `GROUP BY`?
Без использования `GROUP BY` подсчитать повторяющиеся значения нельзя, потому что именно эта операция группирует строки по уникальным значениям столбца. Однако, если вас интересуют все повторяющиеся значения в конкретной строке, можно использовать подзапросы или оконные функции, но для точного подсчета повторений чаще всего используется именно `GROUP BY`.