Извлечение одной строки из базы данных – это базовая, но критически важная операция в работе с SQL. Она применяется при поиске конкретной записи по уникальному идентификатору, логину пользователя или другому точно определённому значению. При этом важно не просто получить первую попавшуюся строку, а именно ту, что соответствует заданному критерию с минимальной нагрузкой на систему.
Для выборки одной строки используется конструкция SELECT с ограничением LIMIT 1 или оператором TOP 1 в зависимости от диалекта SQL. Например, в MySQL запрос выглядит как SELECT * FROM users WHERE id = 42 LIMIT 1. В SQL Server – SELECT TOP 1 * FROM users WHERE id = 42. Эти конструкции не только ограничивают результат до одной строки, но и оптимизируют работу запросов, сокращая объём обрабатываемых данных.
Если строка должна выбираться на основе определённого порядка (например, самой новой записи), необходимо использовать ORDER BY в связке с LIMIT или TOP. Например: SELECT * FROM orders ORDER BY created_at DESC LIMIT 1. Такой подход гарантирует, что будет возвращена именно последняя добавленная строка, а не случайная из множества.
При работе с большими объёмами данных важно убедиться, что поля, участвующие в фильтрации или сортировке, индексированы. Это напрямую влияет на скорость выполнения запроса и нагрузку на сервер. Для поиска по id индекс создаётся автоматически, но для других полей его может потребоваться задать вручную.
Как выбрать одну строку с помощью оператора SELECT
Чтобы извлечь только одну строку из таблицы, используйте оператор SELECT с добавлением конструкции LIMIT 1. Это гарантирует, что результатом будет ровно одна запись, даже если условию удовлетворяют несколько строк:
SELECT * FROM пользователи WHERE статус = 'активен' LIMIT 1;
Если важно, какая именно строка будет выбрана (например, самая новая или с наименьшим идентификатором), добавьте ORDER BY:
SELECT * FROM заказы ORDER BY дата_создания DESC LIMIT 1;
Для выборки конкретной строки по первичному ключу используйте условие WHERE с точным значением:
SELECT имя, email FROM клиенты WHERE id = 1023;
В случае, если запрос может не вернуть данных, заранее обрабатывайте ситуацию на стороне приложения, проверяя наличие результата. Это особенно важно при использовании SELECT в API-запросах или бизнес-логике.
Используйте выборку конкретных столбцов вместо * для повышения производительности и читаемости запроса:
SELECT имя, телефон FROM сотрудники WHERE отдел = 'финансы' ORDER BY id ASC LIMIT 1;
Использование условия WHERE для поиска конкретной строки
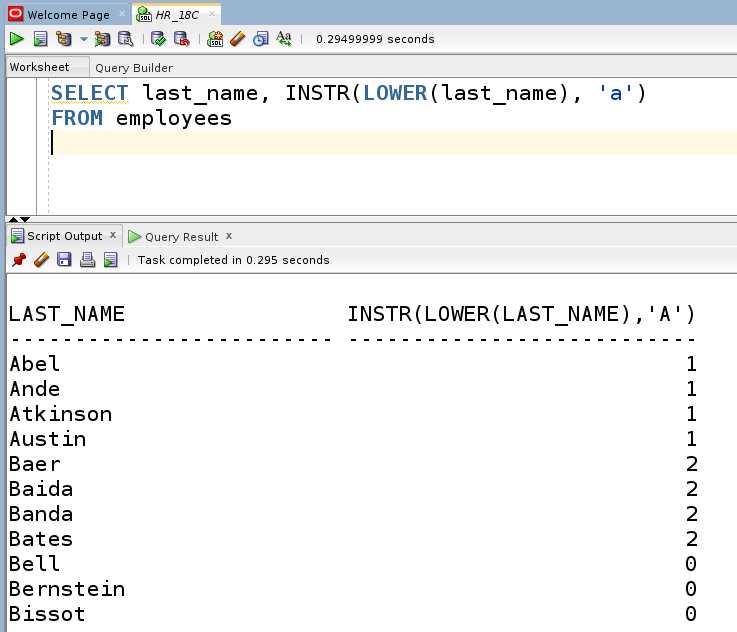
Чтобы извлечь одну строку из таблицы, необходимо точно указать условие, которое идентифицирует нужную запись. Оператор WHERE ограничивает выборку, позволяя получить только те данные, которые соответствуют заданному критерию.
Например, если необходимо найти пользователя с определённым идентификатором, используйте следующий запрос:
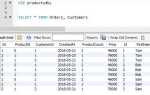
SELECT * FROM users WHERE id = 42;
Значение id должно быть уникальным, чтобы гарантировать получение одной строки. Если уникальность не обеспечена, результатом может стать несколько записей. Используйте LIMIT 1, если цель – получить только первую подходящую строку, несмотря на возможные дубликаты:
SELECT * FROM orders WHERE customer_id = 10 ORDER BY created_at DESC LIMIT 1;
Если поле содержит текст, заключайте значение в одинарные кавычки:
SELECT * FROM products WHERE name = ‘Монитор 27″ IPS’;
Для точного совпадения используйте оператор =. Для гибкого поиска применяйте LIKE с шаблонами:
SELECT * FROM employees WHERE email LIKE ‘%@example.com’;
Убедитесь, что условие в WHERE использует индексируемое поле. Это повысит скорость выполнения запроса, особенно при работе с большими таблицами.
Пример извлечения строки по уникальному идентификатору
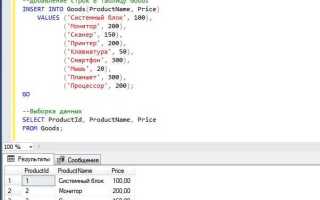
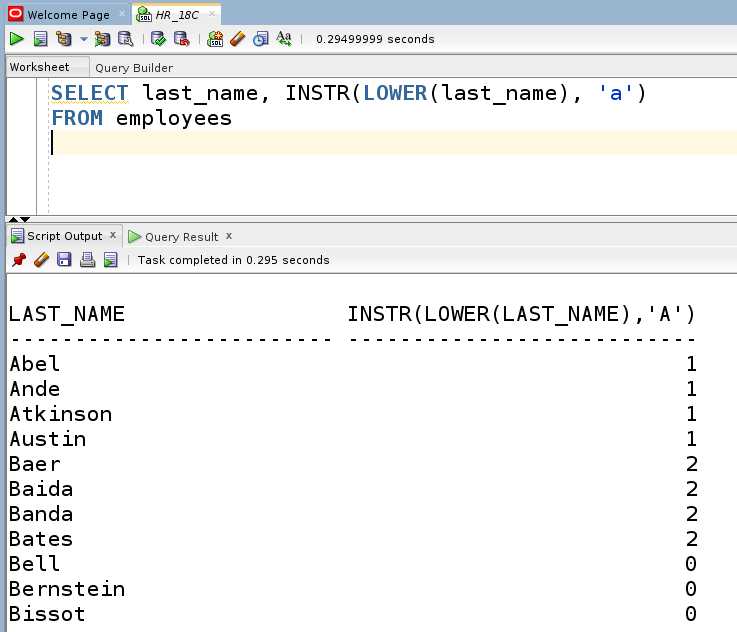
Для получения одной строки из таблицы по уникальному идентификатору используется конструкция SELECT с условием WHERE. Предположим, имеется таблица users с полем id как первичным ключом. Чтобы извлечь пользователя с идентификатором 5:
SELECT * FROM users WHERE id = 5;Если известны только конкретные столбцы, которые необходимо получить, указываются их имена, например:
SELECT name, email FROM users WHERE id = 5;Для повышения безопасности при работе с пользовательскими данными используйте параметризованные запросы. Пример на языке SQL с использованием плейсхолдера для идентификатора:
SELECT * FROM users WHERE id = ?;При использовании PostgreSQL или SQLite в приложении на Python с библиотекой sqlite3:
cursor.execute("SELECT * FROM users WHERE id = ?", (user_id,))Важно убедиться, что поле id индексировано. Это существенно снижает время выполнения запроса. В PostgreSQL это реализуется автоматически при создании первичного ключа:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT,
email TEXT
);Если идентификатор уникален, запрос всегда вернёт не более одной строки. Проверка наличия результата после выполнения запроса:
row = cursor.fetchone()
if row:
print(row)Такой подход позволяет извлекать данные эффективно, минимизируя нагрузку на базу данных и избегая ненужной обработки результатов запроса.
Как ограничить выборку одной строкой с помощью LIMIT
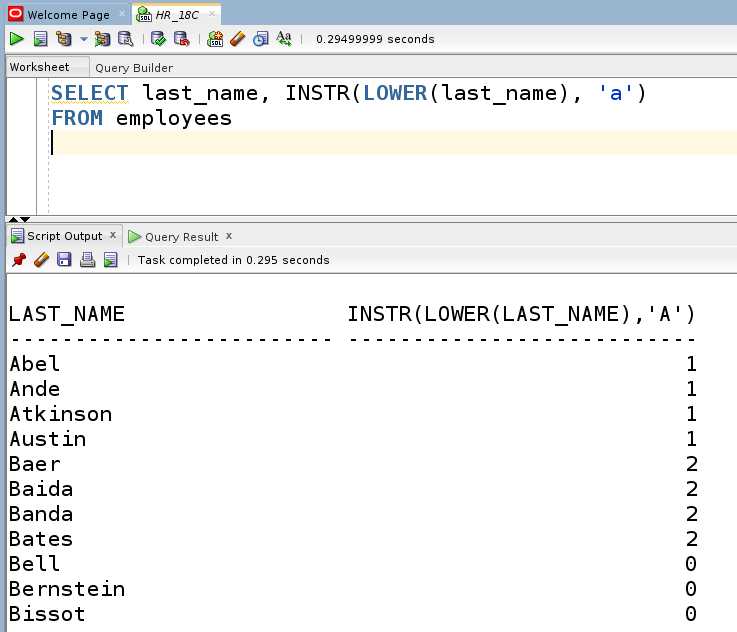
Оператор LIMIT используется для жёсткого ограничения количества возвращаемых строк. Чтобы получить ровно одну строку, после LIMIT указывается значение 1.
SELECT * FROM users LIMIT 1;Без ORDER BY результат будет зависеть от физического порядка хранения данных, что непредсказуемо и не рекомендуется. Чтобы извлекать конкретную строку – например, первую по алфавиту или самую новую – добавляйте сортировку:
SELECT * FROM users ORDER BY created_at DESC LIMIT 1;Такой запрос вернёт последнего добавленного пользователя. Если важен минимальный ID:
SELECT * FROM users ORDER BY id ASC LIMIT 1;Для конкретных полей:
- Ищете пользователя с максимальной зарплатой –
ORDER BY salary DESC LIMIT 1 - Нужен первый заказ клиента –
ORDER BY order_date ASC LIMIT 1
Если необходимо пропустить несколько строк и получить, скажем, вторую по порядку:
SELECT * FROM users ORDER BY id ASC LIMIT 1 OFFSET 1;Используйте LIMIT совместно с WHERE, если нужно ограничить выборку по условию, но вернуть лишь одну строку:
SELECT * FROM orders WHERE status = 'completed' ORDER BY completed_at DESC LIMIT 1;Для повышения производительности создавайте индексы по полям сортировки. Это особенно важно, если таблица содержит десятки тысяч записей и выше.
Оптимизация запроса для работы с большими таблицами
Для этого стоит использовать ограничение выборки с помощью LIMIT или аналогичных конструкций в зависимости от СУБД. Это важно, если необходимо обработать только одну строку или несколько строк из большого набора данных.
Необходимо уделить внимание индексам. Использование индексов значительно ускоряет поиск строк, особенно по колонкам, которые часто участвуют в условиях WHERE, ORDER BY и JOIN. Однако, важно помнить, что создание индексов на слишком многих колонках может замедлить операции вставки и обновления данных.
Для улучшения работы с большими таблицами стоит использовать пагинацию. Вместо того чтобы загружать все строки за один запрос, делайте выборки порциями. Например, с использованием конструкции OFFSET и LIMIT, которые позволяют работать с ограниченным числом строк, что снижает нагрузку на сервер и ускоряет выполнение запроса.
Использование параллельных запросов также является мощным инструментом для ускорения работы с большими таблицами. Некоторые СУБД поддерживают выполнение нескольких запросов одновременно, что позволяет эффективно распределять нагрузку и ускорять обработку данных.
Если в запросе используется несколько таблиц, оптимизацию можно улучшить за счет правильного выбора порядка соединения таблиц. Правильный порядок соединений может существенно повлиять на время выполнения запроса. Важно сначала соединять таблицы с меньшим количеством строк или те, где используется фильтрация данных, чтобы уменьшить объем промежуточных данных на каждом этапе выполнения запроса.
Не стоит забывать и про кэширование запросов. В некоторых случаях повторяющиеся запросы могут быть кэшированы, что значительно сокращает время на их выполнение. Важно анализировать, какие запросы выполняются часто, и на основе этого принимать решение об их кэшировании.
Последним важным шагом является анализ планов выполнения запросов. Использование инструментов профилирования и анализа, таких как EXPLAIN в MySQL или PostgreSQL, позволяет понять, какие операции забирают наибольшее время. Это поможет настроить индексы и перестроить запросы для достижения наилучшей производительности.
Как обрабатывать ошибки при выполнении SQL-запроса

При работе с базами данных важно грамотно обрабатывать ошибки, чтобы предотвратить сбои в приложении и обеспечить точность выполнения запросов. Ошибки могут возникать на разных этапах выполнения SQL-запроса: от синтаксических до логических. Рассмотрим основные подходы и методы для их обработки.
- Обработка ошибок на уровне SQL-запроса: Основной причиной ошибок является некорректный синтаксис запроса. Всегда проверяйте правильность написания SQL-выражений, особенно при динамическом формировании запросов. Использование параметрических запросов помогает избежать ошибок, связанных с SQL-инъекциями и неправильным форматированием данных.
- Использование конструкций для обработки ошибок: Многие СУБД поддерживают встроенные механизмы обработки ошибок, такие как
TRY...CATCHв SQL Server илиEXCEPTIONв PostgreSQL. Эти конструкции позволяют перехватывать ошибки и выполнять дополнительные действия (например, логирование или откат транзакции) при возникновении исключений. - Отладка запросов: В случае возникновения ошибки важно точно понять, на каком этапе произошел сбой. Используйте инструменты для профилирования запросов (например,
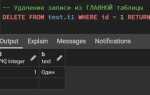
EXPLAINв PostgreSQL) или включайте подробное логирование SQL-запросов в вашем приложении для анализа ошибок на уровне кода. - Работа с транзакциями: Оборачивание запросов в транзакции помогает избежать частичных изменений данных в случае ошибки. При возникновении исключения следует откатить все изменения с помощью
ROLLBACK, чтобы вернуть базу данных в стабильное состояние.
Пример обработки ошибок в SQL Server с использованием конструкции TRY...CATCH:
BEGIN TRY -- SQL-запрос, который может вызвать ошибку SELECT * FROM Users WHERE id = 'not_a_number'; END TRY BEGIN CATCH -- Логирование ошибки PRINT 'Ошибка: ' + ERROR_MESSAGE(); END CATCH
При использовании библиотеки в коде, важно проверять возвращаемые значения ошибок и обрабатывать их до того, как они приведут к критическим последствиям. Пример на Python с использованием библиотеки pyodbc:
import pyodbc
try:
conn = pyodbc.connect(dsn='DataSourceName', user='user', password='password')
cursor = conn.cursor()
cursor.execute('SELECT * FROM Users WHERE id = ?', (user_id,))
result = cursor.fetchone()
except pyodbc.Error as e:
print(f"Ошибка при выполнении запроса: {e}")
finally:
conn.close()
Проверка ошибок на уровне базы данных, особенно в сложных запросах, способствует быстрому выявлению проблем и повышению стабильности работы приложений. Включение логирования, использование транзакций и обработка исключений – основные шаги для минимизации рисков и обеспечения надежности работы с SQL-запросами.
Вопрос-ответ:
Как вывести одну строку из базы данных SQL?
Для того чтобы вывести одну строку из базы данных SQL, используется команда `SELECT` с добавлением условия, чтобы получить только одну нужную строку. Например, запрос `SELECT * FROM таблица WHERE условие LIMIT 1` выберет только одну строку из таблицы, соответствующую заданному условию.
Каким образом можно ограничить количество строк, которые выводятся в SQL-запросе?
Чтобы ограничить количество строк, используемых в запросе, можно добавить оператор `LIMIT`. Например, запрос `SELECT * FROM таблица LIMIT 1` выведет только одну строку. В этом случае `LIMIT 1` ограничивает выборку одной строкой. Этот метод часто используется, когда необходимо получить только одну строку или несколько строк с условием.
Как выбрать только одну строку по определенному условию в SQL?
Для выбора одной строки, соответствующей определенному условию, используйте `SELECT` с конструкцией `WHERE`, а также ограничьте выборку с помощью `LIMIT`. Например, запрос: `SELECT * FROM таблица WHERE столбец = ‘значение’ LIMIT 1` вернет только одну строку, которая удовлетворяет условию в `WHERE`.
Как убедиться, что запрос SQL действительно вернет только одну строку?
Для этого нужно использовать `LIMIT 1`, чтобы точно получить только одну строку. Например, запрос `SELECT * FROM таблица WHERE условие LIMIT 1` гарантирует, что будет возвращена только одна строка. Однако, если условие не выполнено, запрос не вернет никакой строки.
Можно ли использовать команду SQL, чтобы получить первую строку из таблицы без учета условий?
Да, можно использовать команду `SELECT * FROM таблица LIMIT 1`. Этот запрос вернет только одну строку, но без учета условий. Результатом будет первая строка в таблице, независимо от содержимого данных.