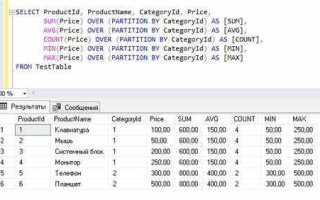
Оконные функции SQL представляют собой мощный инструмент для выполнения сложных аналитических операций, не требующих группировки данных. В отличие от стандартных агрегатных функций, оконные функции позволяют работать с подмножеством строк в пределах окна, сохраняя исходную структуру результата. Это значительно расширяет возможности анализа и ускоряет выполнение запросов.
С помощью оконных функций можно легко решать задачи, которые в противном случае потребовали бы сложных подзапросов или объединений. Например, функция SUM() в окне позволяет подсчитать кумулятивные суммы по группам данных, избегая необходимости в дополнительных вычислениях или объединениях таблиц. Это упрощает запросы и снижает их сложность.
Кроме того, оконные функции позволяют существенно улучшить читаемость запросов. Они помогают минимизировать количество временных таблиц и подзапросов, делая код более компактным и понятным. Вдобавок, это увеличивает скорость выполнения запросов, так как базы данных могут оптимизировать выполнение оконных функций на уровне планирования запроса.
В целом, использование оконных функций в SQL не только повышает производительность, но и открывает новые возможности для аналитики и обработки данных, делая запросы более эффективными и гибкими.
Как оконные функции упрощают расчеты по группе строк
Оконные функции позволяют выполнять расчеты по группе строк без необходимости агрегировать данные или изменять структуру результирующего набора. Это делает код более компактным, улучшает производительность и повышает читаемость запросов. Вместо того чтобы группировать данные и использовать операции с агрегатами, оконные функции могут работать в рамках уже существующего набора строк, выполняя вычисления по «окну», определенному конкретными условиями.
Например, при необходимости рассчитать скользящее среднее для каждой строки в пределах группы, оконная функция позволяет легко настроить окно для каждого значения, а не пересчитывать агрегированные данные для каждой подгруппы. В SQL-запросах это выглядит следующим образом: использование функции AVG() с ключевым словом OVER() позволяет вычислить среднее значение для каждой строки, но с учетом других строк в пределах окна, без явного применения GROUP BY.
Когда дело доходит до сложных расчетов, таких как ранжирование или вычисление процентов от общего итога, оконные функции упрощают логику. Например, использование функции RANK() или DENSE_RANK() позволяет легко определить порядок строк в пределах группы, основываясь на заданном поле, без необходимости дополнительного объединения или сортировки данных.
Ключевое преимущество оконных функций заключается в том, что они позволяют выполнять сложные расчеты по группе строк с минимальными затратами на вычисления и без необходимости переписывать запросы или работать с подзапросами. Это помогает снизить количество операций и повысить общую производительность при обработке больших объемов данных.
Таким образом, оконные функции предлагают значительные преимущества при выполнении расчетов по группам данных, упрощая их реализацию и повышая эффективность работы с SQL-запросами.
Использование оконных функций для подсчета рангов и позиций в наборе данных
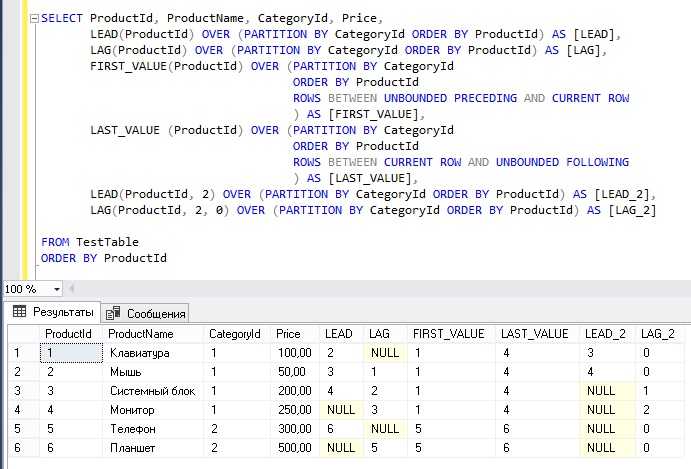
Оконные функции SQL позволяют эффективно вычислять ранги и позиции в наборе данных без необходимости использования подзапросов или агрегации. Это особенно полезно при работе с большими объемами данных, когда важно сохранить оригинальную структуру результатов и получить информацию о позиции каждого элемента в группе.
Для подсчета ранга или позиции часто применяются функции RANK(), DENSE_RANK() и ROW_NUMBER(). Каждая из этих функций имеет свои особенности, которые влияют на результаты.
RANK() назначает уникальный ранг строкам на основе сортировки. Если несколько строк имеют одинаковое значение в сортируемом столбце, они получают одинаковый ранг, а следующий ранг пропускается. Например, если два элемента имеют ранг 1, следующий элемент получит ранг 3, а не 2. Это полезно, когда нужно учесть равенство значений, но при этом сохранить пропуски в рангах.
DENSE_RANK() работает аналогично RANK(), но без пропусков в рангах. В случае равенства значений, следующий элемент получает следующий по порядку ранг. Это может быть полезно, когда необходимо избегать пропусков в ранговой шкале, например, при расчете мест в спортивных соревнованиях, где каждый участник получает свой уникальный номер, даже если несколько участников поделили одно место.
Пример использования оконных функций для подсчета рангов:
SELECT
name,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM employees;
Этот запрос рассчитывает ранг сотрудников на основе их объема продаж. Все сотрудники с одинаковым значением продаж получат одинаковый ранг, а следующий сотрудник получит ранг, пропустивший предыдущий.
Для расчета позиций внутри группы можно использовать функцию PARTITION BY. Это позволяет разделить данные на группы и рассчитывать ранги или позиции внутри каждой группы независимо от других. Например:
SELECT
department,
name,
sales,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY sales DESC) AS position
FROM employees;
Этот запрос рассчитывает позиции сотрудников внутри каждого отдела, начиная с первой строки для каждого отдела. Использование PARTITION BY позволяет выполнять анализ не на всей выборке, а на отдельных группах, что значительно повышает гибкость анализа.
Реализация скользящих агрегатных функций с помощью окон
Оконные функции в SQL позволяют эффективно реализовывать скользящие агрегатные функции, что значительно улучшает производительность при работе с временными рядами или другими типами данных, требующими анализа по окну значений.
Основной концепцией скользящих агрегатных функций является вычисление агрегатов (например, суммы, среднего) на основе набора строк, который динамически изменяется при движении окна по данным. Для этого используются следующие элементы:
- PARTITION BY – делит данные на группы для вычисления агрегатов в каждой группе.
- ORDER BY – задает порядок строк в каждой группе, что важно для корректного вычисления значений скользящих функций.
- ROWS BETWEEN – определяет размер окна, например, количество строк до и после текущей.
Пример использования оконных функций для вычисления скользящего среднего:
SELECT date, sales, AVG(sales) OVER (ORDER BY date ROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS moving_avg FROM sales_data;
В этом примере для каждой строки рассчитывается среднее значение за последние пять дней (включая текущий день), что позволяет анализировать тренды с учетом коротких временных интервалов.
Еще один распространенный пример – вычисление скользящей суммы:
SELECT date, sales, SUM(sales) OVER (ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS moving_sum FROM sales_data;
При таком подходе важно учитывать размер окна, который зависит от анализа. Например, для недельного анализа можно использовать окно в 7 дней, а для месячного – 30.
Скользящие функции находят широкое применение при анализе финансовых данных, статистических выборок и других сценариев, где нужно отслеживать изменение значений во времени или с другими критериями. Окна могут быть настроены на любое количество предыдущих и последующих строк, что дает гибкость в расчете различных агрегатов.
Для повышения эффективности работы с большими объемами данных рекомендуется использовать индексирование по полям, участвующим в ORDER BY, чтобы минимизировать время выполнения запроса.
Оптимизация запросов с оконными функциями для аналитики по временным промежуткам
Анализ временных данных в SQL часто требует агрегации и анализа изменений в течение определённых промежутков времени. Оконные функции позволяют решать эти задачи с высокой эффективностью, минимизируя необходимость в сложных подзапросах и объединениях. Применение оконных функций существенно повышает производительность запросов для аналитики временных данных.
Для работы с временными промежутками необходимо правильно настроить окно, которое будет учитывать последовательность событий в контексте временных меток. Вот несколько ключевых рекомендаций по оптимизации запросов с оконными функциями для временных промежутков:
- Использование правильных окон. Для анализа временных промежутков часто применяется окно, основанное на временных метках, с сортировкой по дате или времени. Важно грамотно определить, какие строки входят в одно окно, чтобы избежать излишней агрегации. Например, оконная функция
ROW_NUMBER()илиRANK()может быть полезна для отслеживания изменений данных по датам. - Меньше данных – быстрее выполнение. Оконные функции обрабатывают данные, ориентируясь на оконную рамку, которая может быть ограничена нужным интервалом времени. Использование фильтрации с
WHEREна этапе выборки позволяет снизить объём обрабатываемых данных, что напрямую влияет на скорость запроса. Для работы с большими объемами данных полезно использовать ограничения по времени, например, анализ за последние 7 дней. - Преимущества
PARTITION BYдля группировки по временным промежуткам. Часто бывает полезно использовать конструкциюPARTITION BYдля группировки данных по интервалам времени. Например, если нужно анализировать данные по неделям, месяцам или кварталам, это поможет разделить исходные данные на меньшие группы и ускорит выполнение запросов. Умное использованиеPARTITION BYпозволяет избежать лишних пересчётов. - Использование
LEAD()иLAG()для сравнения значений во временных промежутках. Оконные функцииLEAD()иLAG()позволяют извлекать данные из соседних строк. Это очень полезно для анализа изменений во времени, например, для вычисления разницы между событиями или промежутками времени. Это значительно упрощает запросы, которые в противном случае потребовали бы использования подзапросов. - Оптимизация сортировки по времени. Когда окно зависит от временной метки, важно обеспечить правильный порядок строк с использованием
ORDER BY. Неверный порядок может привести к неправильным результатам или замедлению запроса. Оптимизируя индексацию столбцов временных меток, можно значительно улучшить производительность запроса при обработке больших объёмов данных. - Использование скользящих окон. В некоторых случаях для анализа данных по временным промежуткам используется скользящее окно. Например, если нужно вычислить скользящее среднее или сумму за последние N дней, то правильно настроенное окно с
ROWS BETWEENпозволяет выполнить запрос с минимальными затратами ресурсов.
Оптимизация запросов с оконными функциями для временной аналитики требует тщательного подхода к выбору окон и грамотной фильтрации данных. Правильное использование оконных функций повышает производительность, делает запросы более читаемыми и позволяет выполнять сложную аналитику с минимальными затратами времени и ресурсов.
Сравнение оконных функций с подзапросами и объединениями

Оконные функции SQL обеспечивают более гибкую и эффективную работу с данными по сравнению с традиционными подзапросами и объединениями. Они позволяют выполнять агрегирование, сортировку и другие операции по строкам в пределах одного результата запроса, не изменяя структуру самих данных. В отличие от подзапросов, которые требуют выполнения дополнительных операций для каждого значения, оконные функции позволяют обрабатывать данные «на лету», снижая нагрузку на систему и повышая производительность.
Подзапросы часто требуют повторного выполнения одних и тех же операций для каждого из результатов внешнего запроса. Это приводит к избыточным вычислениям и увеличивает время выполнения, особенно если подзапросы вложены несколько уровней. Оконные функции, напротив, выполняются один раз на наборе данных, что позволяет избежать повторений и значительно снизить время обработки. Например, использование функции ROW_NUMBER() для нумерации строк или RANK() для определения ранга в пределах группы будет быстрее и проще при использовании оконных функций, чем при организации аналогичной логики через подзапросы.
Объединения (JOIN) обычно используются для комбинирования данных из нескольких таблиц. Однако, если задача состоит в выполнении расчетов по строкам в пределах одной таблицы (например, вычисление скользящего среднего или сравнение текущего значения с предыдущим), использование оконных функций дает явное преимущество. В таких случаях объединения либо вовсе не требуются, либо становятся более сложными, когда используются дополнительные условия для фильтрации строк. Оконные функции, как правило, позволяют обрабатывать все эти операции с меньшими усилиями и без необходимости манипулировать самими данными, что упрощает запрос и делает его более читаемым.
Когда необходимо агрегировать данные по группам, но при этом сохранить исходную структуру строк, оконные функции обеспечивают решение, которое подзапросы и объединения предложить не могут без значительных усилий. Например, использование функции SUM() OVER() для вычисления суммы по каждой строке в группе даст тот же результат, что и подзапрос, но гораздо быстрее и с меньшим количеством кода. В то время как подзапрос потребует группировки и дополнительной фильтрации, оконная функция выполняет все необходимые вычисления за один проход по данным.
В целом, выбор между оконными функциями, подзапросами и объединениями зависит от конкретной задачи. Оконные функции предоставляют явные преимущества в простоте, производительности и удобстве чтения запросов при работе с аналитическими задачами, требующими манипуляций с данным набором строк в пределах группы. Подзапросы и объединения остаются полезными для более сложных случаев, когда требуется работа с различными таблицами или фильтрация на более глубоком уровне.
Как оконные функции помогают в вычислениях на основе текущей и соседних строк
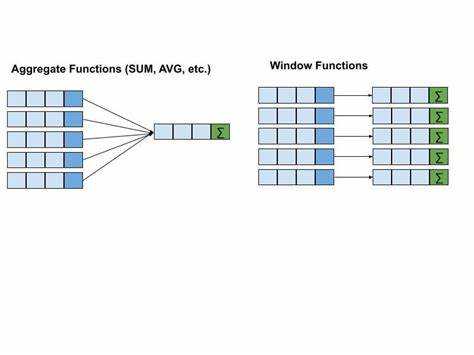
Оконные функции в SQL позволяют выполнять вычисления, используя не только данные текущей строки, но и информацию из соседних строк. Это особенно полезно, когда необходимо анализировать тренды, проводить агрегацию по группам или вычислять скользящие средние без необходимости создавать подзапросы или объединять таблицы. Такие функции сокращают объем запросов и увеличивают их производительность.
Одним из популярных применений оконных функций является вычисление скользящего среднего. Для этого используется функция AVG() с оконным оператором OVER(), который определяет диапазон строк, участвующих в вычислении. Например, для вычисления скользящего среднего за последние 3 строки можно использовать следующий запрос:
SELECT value, AVG(value) OVER (ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg FROM data_table;
В этом примере для каждой строки вычисляется среднее значение по текущей строке и двум предыдущим. Это позволяет проводить анализ тенденций без необходимости вручную делить данные на группы или использовать дополнительные JOIN-операции.
Другим примером является вычисление разниц между текущими и предыдущими значениями. Используя функцию LAG(), можно легко получить доступ к данным соседних строк. Например, для получения разницы между текущим значением и предыдущим можно использовать следующий запрос:
SELECT value, value - LAG(value) OVER (ORDER BY date) AS diff_from_previous FROM data_table;
Здесь функция LAG(value) возвращает значение предыдущей строки, а операция вычитания позволяет получить разницу. Такой подход особенно полезен при анализе изменений, например, для оценки колебаний цен или отклонений в производственных показателях.
Оконные функции также дают возможность делать ранжирование строк по определенным критериям. Например, функция RANK() позволяет вычислять ранг строки в пределах определенной группы, что полезно для создания рейтингов и сортировки данных. Пример:
SELECT id, value, RANK() OVER (PARTITION BY category ORDER BY value DESC) AS category_rank FROM data_table;
В данном случае RANK() присваивает ранг каждому значению в пределах категории, что позволяет эффективно сегментировать данные и оценивать их положение в группе.
Использование оконных функций сокращает количество необходимых операций и делает код более читаемым. Вместо сложных вложенных запросов или объединений таблиц, можно выполнить вычисления непосредственно в рамках одного запроса, что повышает производительность и упрощает поддержку кода.
Применение оконных функций для вычисления кумулятивных сумм и процентов

Оконные функции SQL позволяют эффективно вычислять кумулятивные суммы и проценты, что особенно полезно при анализе временных рядов или других данных, где требуется отслеживать накопленные значения по определённым критериям. Вместо использования подзапросов или сложных агрегаций, оконные функции позволяют выполнить эти операции в одном запросе, улучшая читаемость и производительность.
Для вычисления кумулятивной суммы применяется оконная функция SUM() в сочетании с операторами OVER() и ORDER BY. Она позволяет подсчитать сумму значений по каждому ряду, с учётом всех предыдущих строк, упорядоченных по заданному критерию.
Пример запроса для вычисления кумулятивной суммы продаж по датам:
SELECT
дата,
продажи,
SUM(продажи) OVER (ORDER BY дата) AS кумулятивная_сумма
FROM
продажи_по_датам;В данном примере SUM(продажи) OVER (ORDER BY дата) вычисляет сумму продаж для каждой строки с учётом всех предыдущих дат, создавая кумулятивную сумму по времени.
Для вычисления процентов от кумулятивной суммы используется та же оконная функция. Чтобы вычислить процент от общего объёма на текущий момент, применяется выражение, делящее кумулятивную сумму на общую сумму и умножающее результат на 100.
Пример вычисления процента от общего объёма:
SELECT
дата,
продажи,
SUM(продажи) OVER (ORDER BY дата) AS кумулятивная_сумма,
(SUM(продажи) OVER (ORDER BY дата) / SUM(продажи) OVER ()) * 100 AS процент_от_общей_суммы
FROM
продажи_по_датам;Здесь SUM(продажи) OVER () вычисляет общую сумму всех продаж, а результат делится на текущую кумулятивную сумму, умноженную на 100, чтобы получить процентное соотношение.
Оконные функции позволяют также использовать дополнительные критерии, например, фильтрацию по категориям или регионам, не нарушая общую структуру запроса. Это позволяет гибко и быстро адаптировать запросы под нужды анализа, избегая необходимости писать сложные подзапросы или использовать временные таблицы.
Обработка строк с пропущенными значениями через оконные функции
Оконные функции в SQL предлагают мощные инструменты для обработки строк с пропущенными значениями, улучшая точность и эффективность обработки данных. Использование таких функций позволяет не только обрабатывать отсутствующие значения, но и анализировать данные в контексте соседних строк, что открывает дополнительные возможности для очистки и интерполяции.
Одним из самых распространённых методов работы с пропущенными значениями является использование функций, таких как COALESCE() или IFNULL(), вместе с оконными функциями. Эти функции позволяют заполнять пропуски значениями из соседних строк, что важно при анализе временных рядов или при необходимости замещения пустых значений на основе средних или медианных значений других строк в группе.
Рассмотрим пример. Предположим, у нас есть таблица с данными о продажах, где некоторые строки содержат пропущенные значения для конкретного продукта. С использованием оконной функции AVG(), можно заполнить эти пропуски средним значением по группе товаров:
SELECT product_id, sales, COALESCE(sales, AVG(sales) OVER (PARTITION BY product_id)) AS filled_sales FROM sales_data;
В этом примере COALESCE() заменяет пропущенные значения в колонке sales на среднее значение продаж для каждого product_id. Важно, что AVG(sales) OVER (PARTITION BY product_id) позволяет вычислять среднее значение для каждой группы товаров, игнорируя текущую строку, где может быть пропуск.
Другим подходом является использование оконных функций с сортировкой, например, LAG() или LEAD(), чтобы взять значения из соседних строк. Это полезно в ситуациях, когда необходимо заполнить пропуски на основе предшествующих или последующих значений. Пример:
SELECT product_id, sales, COALESCE(sales, LAG(sales) OVER (PARTITION BY product_id ORDER BY sale_date)) AS filled_sales FROM sales_data;
Здесь, если значение в строке sales отсутствует, используется значение из предыдущей строки, что полезно для заполнения пропусков в данных, где значения могут зависеть от временной последовательности.
Важно отметить, что правильное использование оконных функций для обработки пропущенных значений зависит от контекста данных и целей анализа. В некоторых случаях может быть полезно использовать медианные значения, а в других – скользящие средние. Выбор подходящей функции и метода заполнения пропусков значительно улучшает точность анализа и позволяет более точно моделировать данные.
Вопрос-ответ:
Что такое оконные функции в SQL и зачем они нужны?
Оконные функции в SQL представляют собой специальные функции, которые позволяют выполнять вычисления над наборами строк, которые связаны с текущей строкой в запросе. В отличие от агрегатных функций, оконные функции не сводят строки в одну — они сохраняют результат для каждой строки, но выполняют вычисления на основе других строк, которые находятся в пределах окна (например, предыдущие или следующие строки). Это особенно полезно при анализе данных, таких как расчёт скользящих средних, рангов, сумм по группам и других операций, где важен контекст относительно других записей.