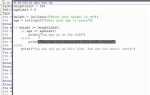
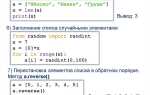
При работе с байтами в Python часто возникает необходимость преобразования их в строковый формат. Этот процесс декодирования важен при взаимодействии с текстовыми данными, передаваемыми по сети, сохранёнными в файлах или полученными из внешних источников. В Python для таких задач используется метод decode(), который позволяет выбрать нужную кодировку для корректного перевода байтов в строку.
Для правильного декодирования важно понимать, что байты могут быть закодированы в различных форматах, таких как UTF-8, ASCII или другие специфические кодировки. Если при декодировании выбранная кодировка не совпадает с реальной, возникнет ошибка. Рекомендуется всегда явно указывать кодировку, чтобы избежать неожиданных результатов, особенно когда работаешь с данными, полученными из внешних источников.
Пример использования метода decode() следующий: при наличии байтового объекта, например, b’Hello World’, его можно преобразовать в строку с помощью метода decode(‘utf-8’), что вернёт строку «Hello World». Важно помнить, что для каждой кодировки существуют свои особенности, поэтому знание контекста данных всегда помогает выбрать оптимальный способ декодирования.
Преобразование байтов в строку с использованием метода decode()

Метод decode() в Python используется для преобразования байтов (тип bytes) в строку (тип str) с учетом кодировки. Этот метод позволяет извлечь текстовые данные, закодированные в байтах, и правильно интерпретировать их в виде строки.
 decode() требует указания кодировки. Если кодировка байтов не совпадает с указанной, будет вызвана ошибка UnicodeDecodeError.
decode() требует указания кодировки. Если кодировка байтов не совпадает с указанной, будет вызвана ошибка UnicodeDecodeError.
Часто используемые кодировки для декодирования байтов:
- utf-8 – самая популярная кодировка для текстовых данных в интернете.
- latin-1 – часто используется для западноевропейских языков.
- cp1251 – кодировка для русского языка в Windows-системах.
Пример обработки ошибок при декодировании:
byte_data = b'\xd0\x9f\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'
try:
text = byte_data.decode('ascii')
except UnicodeDecodeError:
print("Ошибка декодирования – неверная кодировка.")Если байты не соответствуют выбранной кодировке, метод decode() может выбросить исключение UnicodeDecodeError. Чтобы избежать этого, можно использовать параметр errors, который определяет поведение при ошибке. Возможные значения:
- strict – выбрасывает исключение (по умолчанию).
- ignore – игнорирует ошибочные байты.
- replace – заменяет ошибочные байты символом
�.
Пример с параметром errors:
byte_data = b'\xd0\x9f\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82\x80'
text = byte_data.decode('utf-8', errors='replace')
В случае использования байтов, полученных из различных источников (например, при чтении данных из файла или сети), важно всегда удостоверяться в правильности кодировки для корректного преобразования в строку.
Работа с кодировками при декодировании байтов
Декодирование байтов в Python тесно связано с выбором правильной кодировки. Кодировка определяет, как байты преобразуются в строку символов. Без правильной кодировки декодирование может привести к ошибкам или некорректным результатам. Рассмотрим основные моменты при работе с кодировками.
При декодировании байтового массива в строку важно знать исходную кодировку. Наиболее распространённые кодировки включают:
- UTF-8 – наиболее популярная кодировка, поддерживающая все символы Unicode.
- Latin-1 – часто используется для обработки данных на европейских языках.
- Windows-1251 – стандартная кодировка для русскоязычных систем Windows.
- ASCII – кодировка, поддерживающая только английские символы.
Для декодирования байтов в строку используется метод decode(). Пример:
bytes_data = b'\xd0\xb8\xd0\xbb\xd1\x8c'
decoded_string = bytes_data.decode('utf-8')
print(decoded_string)
Если выбранная кодировка не совпадает с реальной кодировкой данных, Python выбросит исключение UnicodeDecodeError. Чтобы избежать этого, рекомендуется использовать параметр errors, который позволяет указать, как поступать при ошибках декодирования:
- 'ignore' – игнорирует символы, которые не удается декодировать.
- 'replace' – заменяет некорректные символы на специальный символ (например, ?).
- 'backslashreplace' – заменяет некорректные символы на их escape-последовательности.
Пример с параметром errors='ignore':
bytes_data = b'\xd0\xb8\xd0\xbb\xd1\x8c\x80'
decoded_string = bytes_data.decode('utf-8', errors='ignore')
print(decoded_string)
Иногда необходимо работать с байтовыми данными, которые могут иметь неоднозначную кодировку. В таких случаях полезно использовать библиотеку chardet, которая автоматически пытается определить кодировку. Пример использования:
import chardet
bytes_data = b'\xd0\xb8\xd0\xbb\xd1\x8c'
result = chardet.detect(bytes_data)
encoding = result['encoding']
decoded_string = bytes_data.decode(encoding)
print(decoded_string)
Кроме того, важно учитывать возможные проблемы с декодированием при работе с файлами. Если файл был сохранён в специфической кодировке, необходимо явно указать её при открытии файла, например:
with open('file.txt', 'rb') as file:
bytes_data = file.read()
decoded_string = bytes_data.decode('utf-8')
print(decoded_string)
Таким образом, правильный выбор кодировки при декодировании байтов в Python критичен для корректной обработки данных. Важно учитывать особенности исходных данных и использовать подходящие методы для избежания ошибок.
Декодирование байтов с учётом ошибок в данных
При декодировании байтов в Python может возникнуть ошибка `UnicodeDecodeError`, если последовательность содержит недопустимые байты. Это часто случается при работе с повреждёнными файлами, нестабильными сетевыми соединениями или неправильной кодировкой источника.
Для управления ошибками декодирования используйте параметр errors в методе bytes.decode(). Значение по умолчанию – 'strict', при котором ошибка приводит к исключению. Чтобы избежать сбоя, применяйте альтернативные стратегии:
'ignore' – пропускает некорректные байты без уведомления. Подходит, если важна стабильность выполнения, а потеря данных допустима:
data.decode('utf-8', errors='ignore')
'replace' – заменяет ошибочные байты символом '�'. Удобно для логирования или отображения информации пользователю:
data.decode('utf-8', errors='replace')
'backslashreplace' – кодирует ошибочные байты в виде escape-последовательностей, например \x80. Полезно для диагностики:
data.decode('utf-8', errors='backslashreplace')
'surrogateescape' – сохраняет недопустимые байты как суррогатные кодовые точки. Это позволяет повторно закодировать данные без потерь:
data.decode('utf-8', errors='surrogateescape')
Если исходная кодировка неизвестна, используйте библиотеку chardet или charset-normalizer для её определения. После этого можно безопасно декодировать данные с нужной стратегией обработки ошибок.
Как декодировать байты в Unicode с правильной кодировкой
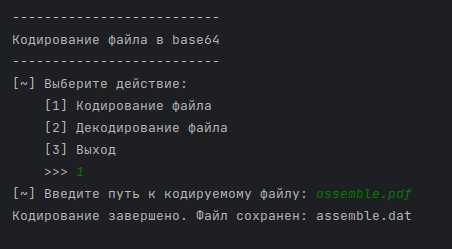
Для точного преобразования байтов в строку Unicode необходимо использовать ту же кодировку, в которой байты были изначально закодированы. Ошибка выбора кодировки приводит к появлению некорректных символов или исключениям UnicodeDecodeError.
Наиболее распространённые кодировки – utf-8, cp1251, latin-1 и utf-16. Правильную кодировку можно определить по метаданным, соглашениям API, BOM (Byte Order Mark) или с помощью анализа содержимого.
Пример декодирования байтовой строки с известной кодировкой:
byte_data = b'\xd0\x9f\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'
text = byte_data.decode('utf-8')
print(text) # Привет
Если кодировка неизвестна, используйте модуль chardet или charset-normalizer для определения вероятной кодировки:
import chardet
raw_bytes = b'\xcf\xf0\xe8\xe2\xe5\xf2'
detected = chardet.detect(raw_bytes)
text = raw_bytes.decode(detected['encoding'])
print(text) # Привет
Для предотвращения сбоев при чтении файлов рекомендуется явно указывать кодировку:
with open('file.txt', 'r', encoding='utf-8') as f:
content = f.read()
Если возможны ошибки в байтах, используйте параметры errors='replace' или 'ignore':
text = byte_data.decode('utf-8', errors='replace')
Краткая справка по популярным кодировкам:
Кодировка
Описание
utf-8
Универсальная, совместима с ASCII, переменная длина символов
cp1251
Windows-кодировка для кириллицы
latin-1
Западноевропейская, фиксированная длина (1 байт)
utf-16
Двухбайтовая, с возможным BOM
Использование библиотеки struct для декодирования бинарных данных
Библиотека struct в Python предоставляет эффективные инструменты для работы с бинарными данными, особенно когда необходимо извлечь значения из байтовых строк в соответствии с конкретными форматами. Она позволяет декодировать данные, представленные в компактном и стандартизированном виде, в том числе данные, записанные в специфичных для платформ форматы, такие как целые числа, числа с плавающей запятой, строки и другие примитивные типы.
Основной инструмент библиотеки – функция struct.unpack(format, buffer), где format определяет структуру данных (например, типы и порядок байтов), а buffer – это исходная байтовая строка. Формат задается строкой, в которой используются символы, обозначающие типы данных. Например, 'i' для целого числа, 'f' для числа с плавающей запятой, 's' для строки.
Для начала работы с struct необходимо указать правильный формат данных, что крайне важно при интерпретации бинарных данных. Строка формата описывает, как интерпретировать данные, начиная с их размера, порядка байтов и типов. Например, чтобы распаковать два целых числа (с учетом их порядка в байтах), формат будет выглядеть как 'ii'.
Для получения правильных данных важно учитывать эндикнесс (порядок байтов) – если данные могут быть в формате little-endian или big-endian, необходимо указать это в строке формата с помощью символов '<' (little-endian) и '>' (big-endian). Пример: ' означает чтение целого числа в формате little-endian.
Библиотека также позволяет работать с фиксированными и переменными размерами данных. Если необходимо прочитать строку с переменной длиной, используется формат 's', который распакует заданное количество байт в строку. Например, для извлечения строки длиной 10 символов используйте '10s'.
Практическим примером может быть следующая задача: распаковка структуры, содержащей целое число, число с плавающей запятой и строку. Формат для этого будет таким: 'i f 10s', где i – целое число, f – число с плавающей запятой, а 10s – строка длиной 10 символов.
Для работы с struct удобно использовать метод struct.pack() для кодирования данных обратно в бинарную строку, что позволяет в случае необходимости сохранять или передавать данные в бинарном формате.
Кроме того, если необходимо распаковать данные в несколько этапов, рекомендуется использовать методы, такие как struct.iter_unpack(), которые позволяют работать с потоковыми данными или большими объемами данных без необходимости загружать их целиком в память.
Использование struct повышает производительность при работе с бинарными форматами, поскольку она оптимизирована для таких операций и предоставляет четкие методы для работы с различными типами данных, следуя стандартам и платформенным особенностям.
Обработка многобайтовых символов при декодировании данных

При работе с текстовыми данными, закодированными в разных форматах, важно учитывать особенности многобайтовых символов. Эти символы занимают более одного байта, что делает их обработку сложнее, чем для односимвольных кодировок, таких как ASCII. Проблемы с многобайтовыми символами часто возникают при декодировании данных, если не выбрать правильную кодировку или не правильно обработать ошибки декодирования.
Основные кодировки, использующие многобайтовые символы, такие как UTF-8 и UTF-16, имеют свою структуру, где каждый символ может занимать от одного до четырех байтов (для UTF-8) или два байта (для UTF-16). При декодировании важно правильно трактовать байты, чтобы избежать ошибок и искажений данных.
Для декодирования байтов в строку в Python используется метод decode(). Если в исходных байтах содержатся некорректные символы или кодировка несовместима с переданными данными, возникает ошибка. Для предотвращения таких ситуаций следует использовать параметр errors. Например, errors='ignore' позволяет игнорировать некорректные символы, а errors='replace' заменяет их на знак вопроса или символ-заполнитель.
Пример обработки ошибки при декодировании с использованием UTF-8:
byte_data = b'\xe2\x82\xac\x80' # Некорректные байты
decoded_data = byte_data.decode('utf-8', errors='replace')
print(decoded_data) # Результат: '€�'
Для работы с многобайтовыми символами важно точно понимать, в какой кодировке переданы данные. Например, при работе с UTF-8 символы с кодами выше 127 могут занимать от 2 до 4 байтов, что требует внимательности при декодировании. Если данные, закодированные в UTF-16, не были распознаны как таковые, результат может быть искажён, поскольку UTF-16 использует два байта для каждого символа.
Некоторые библиотеки, такие как chardet, помогают автоматически определять кодировку данных. Однако, для повышения надежности, рекомендуется заранее знать используемую кодировку или использовать стандартные методы обработки ошибок при декодировании.
Вопрос-ответ:
Что такое байты в Python и как их можно декодировать?
Байты в Python — это тип данных, представляющий собой последовательность байтов. Они часто используются для хранения двоичных данных, например, при работе с файлами, сетевыми соединениями или кодированием. Для того чтобы преобразовать байты в строку, необходимо применить декодирование, указывая соответствующую кодировку, например UTF-8, ASCII и другие. Чтобы декодировать байты, можно использовать метод `.decode()`, например: `my_bytes.decode('utf-8')`.
Какие проблемы могут возникнуть при декодировании байтов в Python?
Основная проблема при декодировании байтов в Python — это несоответствие кодировок. Например, если байты закодированы в одной кодировке, а вы пытаетесь декодировать их в другой, может возникнуть ошибка, такая как `UnicodeDecodeError`. Важно всегда удостоверяться, что кодировка, которую вы указываете в методе `.decode()`, совпадает с той, в которой были закодированы данные. Например, если строка была закодирована в `utf-16`, но вы пытаетесь декодировать её как `utf-8`, Python не сможет правильно интерпретировать байты и выдаст ошибку.
Как выбрать правильную кодировку для декодирования байтов в Python?
Правильную кодировку для декодирования байтов необходимо выбирать в зависимости от того, как данные были закодированы. В большинстве случаев используется кодировка UTF-8, но если вы знаете, что данные были закодированы в другой кодировке, например, Windows-1251 или ISO-8859-1, нужно использовать соответствующую кодировку. Чтобы не допустить ошибок, можно использовать инструмент `chardet`, который помогает определить кодировку автоматически. Пример: `chardet.detect(my_bytes)`.
Можно ли декодировать байты без указания кодировки?
Если вы не укажете кодировку при декодировании байтов, Python попытается применить кодировку по умолчанию, которая в большинстве случаев будет UTF-8. Однако это может привести к ошибкам, если байты закодированы в другой кодировке. Чтобы избежать таких проблем, всегда лучше явно указывать кодировку, особенно если вы работаете с данными, пришедшими из разных источников или систем. В противном случае, если кодировка не будет соответствовать данным, вы получите ошибку декодирования.
Что делать, если при декодировании байтов в Python возникает ошибка?
Если при декодировании байтов возникает ошибка, это обычно связано с несоответствием кодировки. Чтобы справиться с этой проблемой, можно попробовать несколько решений. Во-первых, убедитесь, что указали правильную кодировку. Во-вторых, можно использовать параметр `errors` метода `.decode()`, чтобы указать, как Python должен поступить, если встречает неправильные байты. Например, `my_bytes.decode('utf-8', errors='ignore')` пропустит неверные символы, а `errors='replace'` заменит их на символы-заполнители. Однако такие подходы могут привести к потере данных или искажению информации.