Python предоставляет разнообразные инструменты для работы с HTTP-серверами, что делает его одним из самых популярных языков для разработки веб-приложений. Одним из основных подходов является использование стандартных библиотек, таких как http.server и requests, а также более сложных фреймворков, таких как Django и Flask.
Для взаимодействия с HTTP-сервером в Python обычно используются клиент-серверные модели. На клиентской стороне часто применяется библиотека requests, которая упрощает отправку HTTP-запросов и обработку ответов. С помощью нее можно работать с методами GET, POST, PUT, DELETE и другими, что позволяет легко интегрировать Python-программу с внешними веб-сервисами. Простота в использовании и возможность добавления заголовков, параметров и данных формы делают эту библиотеку удобной для большинства задач.
На серверной стороне Python часто используется Flask или Django для создания полноценного веб-сервера. Эти фреймворки позволяют обрабатывать HTTP-запросы, управлять маршрутизацией, работать с базами данных и создавать API. Flask идеально подходит для небольших проектов, где необходима простота и гибкость. Django, в свою очередь, предлагает более полный набор функций для создания крупных веб-приложений, включая систему авторизации, работу с шаблонами и админкой.
Кроме того, Python предоставляет возможности для создания собственных HTTP-серверов с помощью библиотеки http.server, которая является частью стандартной библиотеки. Этот подход подходит для быстрых экспериментов или разработки небольших внутренних сервисов, однако для масштабных проектов рекомендуется использовать более зрелые фреймворки.
Как отправлять HTTP запросы с использованием библиотеки requests
Для начала необходимо установить библиотеку, если она ещё не установлена:
pip install requestsПосле установки можно приступать к отправке запросов. Рассмотрим основные методы:
- GET – запрашивает данные с сервера.
- POST – отправляет данные на сервер.
- PUT – обновляет данные на сервере.
- DELETE – удаляет данные с сервера.
GET-запрос
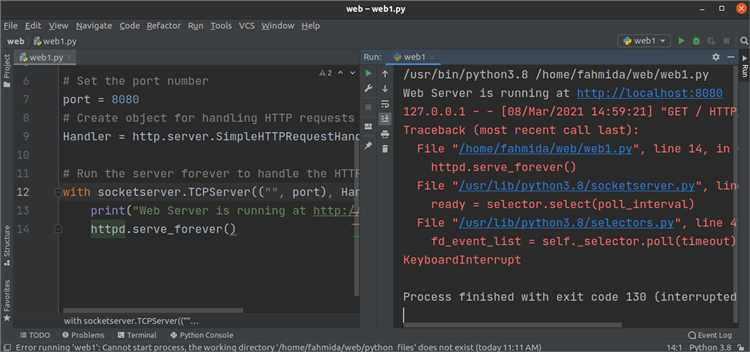
Для получения данных с сервера используется метод requests.get(). Он отправляет HTTP-запрос типа GET на указанный URL.
import requests
response = requests.get('https://api.example.com/data')
if response.status_code == 200:
print(response.json()) # Обработка ответа в формате JSON
else:
print("Ошибка запроса:", response.status_code)
Метод json() позволяет автоматически декодировать ответ, если он представлен в формате JSON.
POST-запрос
Чтобы отправить данные на сервер, используется метод requests.post(). Это удобно для отправки форм, JSON-объектов или других данных.
import requests
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('https://api.example.com/submit', data=data)
if response.status_code == 201:
print("Данные успешно отправлены")
else:
print("Ошибка отправки:", response.status_code)
Если данные должны быть отправлены в формате JSON, можно воспользоваться параметром json:
response = requests.post('https://api.example.com/submit', json={'key1': 'value1'})
Дополнительные параметры запросов
Библиотека requests предоставляет ряд дополнительных параметров для настройки запросов:
- headers – для указания заголовков запроса, например, для авторизации.
- params – для передачи параметров в URL (например, параметры фильтрации).
- timeout – для ограничения времени ожидания ответа от сервера.
- auth – для указания данных для базовой авторизации.
Пример запроса с параметрами и заголовками:
response = requests.get(
'https://api.example.com/search',
headers={'Authorization': 'Bearer YOUR_TOKEN'},
params={'query': 'python', 'page': 1},
timeout=10
)
Обработка ошибок
Для надёжной работы с HTTP-запросами важно правильно обрабатывать возможные ошибки. Библиотека requests поддерживает исключения, такие как requests.exceptions.Timeout и requests.exceptions.RequestException, которые помогут отлавливать проблемы, связанные с сетевыми ошибками.
try:
response = requests.get('https://api.example.com/data', timeout=5)
response.raise_for_status() # Проверка на успешный статус
except requests.exceptions.Timeout:
print("Превышено время ожидания")
except requests.exceptions.RequestException as e:
print(f"Произошла ошибка: {e}")
Метод raise_for_status() автоматически генерирует исключение, если статус код ответа не указывает на успешное выполнение запроса (коды 4xx и 5xx).
Заключение
Библиотека requests делает работу с HTTP-запросами в Python быстрой и простой. Важно грамотно использовать параметры запросов и правильно обрабатывать ошибки, чтобы минимизировать вероятность сбоев в приложении. Благодаря этому инструменту, взаимодействие с API и веб-ресурсами становится удобным и эффективным.
Как обрабатывать ответы сервера в Python
Ответ сервера, получаемый через requests.get() или аналогичные методы, представляет собой объект, содержащий множество полезных данных. Основной атрибут ответа – это response.status_code, который указывает на статус выполнения запроса. Код состояния может быть 200 для успешных запросов, 404 для «Не найдено» или 500 для ошибки сервера. Это позволяет быстро понять, был ли запрос успешным, и принять соответствующие меры.
Для проверки успешности запроса можно использовать свойство response.ok, которое возвращает True, если код состояния находится в диапазоне от 200 до 299. Это удобный способ для автоматической проверки корректности ответа без явной проверки статуса кода.
Если запрос прошел успешно, следующим шагом будет извлечение данных из ответа. Наиболее распространенные форматы данных – это JSON, текст или бинарные файлы. Для работы с JSON-данными используется метод response.json(), который преобразует JSON-ответ в словарь Python. Например:
response = requests.get('https://api.example.com/data')
data = response.json()В случае текстовых данных можно использовать response.text для получения строки с ответом. Для бинарных данных (например, изображений или файлов) используется response.content, который возвращает ответ в виде байтов.
Работа с ошибками – важная часть обработки ответов. В случае получения кода состояния, указывающего на ошибку (например, 404 или 500), можно использовать исключения. Библиотека requests позволяет легко обрабатывать ошибки с помощью метода raise_for_status(), который вызывает исключение, если код состояния не указывает на успешный запрос:
response = requests.get('https://api.example.com/data')
response.raise_for_status()Если запрос не удался, то будет поднято исключение requests.exceptions.HTTPError, которое можно поймать и обработать.
Если сервер возвращает ошибку или нестандартные данные, полезно использовать метод response.text для диагностики, чтобы понять, что именно вернул сервер. В некоторых случаях, например при получении HTML-страниц с ошибками, текст ошибки может быть полезен для дальнейшего анализа и принятия решения о корректности запроса.
В случае взаимодействия с API, важным аспектом является правильная обработка статусов 4xx и 5xx. В ответах с кодами этих классов часто содержатся дополнительные данные, которые можно извлечь с помощью response.json() или response.text, чтобы понять детали ошибки.
Настройка заголовков HTTP запроса в Python
Пример настройки заголовков в запросе с использованием requests:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Authorization': 'Bearer your_token',
'Accept': 'application/json',
}
response = requests.get('https://api.example.com/data', headers=headers)
print(response.text)В этом примере заголовок User-Agent указывает, какой браузер или устройство делает запрос. Заголовок Authorization используется для передачи токена аутентификации в формате Bearer. Заголовок Accept информирует сервер о том, что клиент ожидает ответ в формате JSON.
При использовании библиотеки requests также можно легко манипулировать дополнительными заголовками, такими как Content-Type, который указывает тип данных, отправляемых в теле запроса. Например, если отправляется JSON-данные, настройка будет выглядеть так:
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer your_token',
}
response = requests.post('https://api.example.com/submit', json={'key': 'value'}, headers=headers)
print(response.text)Важно учитывать, что заголовки могут быть специфичными для API или сервера, с которым вы взаимодействуете, поэтому рекомендуется тщательно изучить документацию сервера для правильной настройки заголовков.
Кроме того, заголовки могут быть использованы для контроля кэширования запросов. Например, заголовок Cache-Control позволяет указать, как сервер должен обрабатывать кэшированные данные. Заголовок If-Modified-Since может помочь уменьшить нагрузку на сервер, запрашивая ресурс только в случае его изменения.
Для отправки запросов с кастомными заголовками можно также использовать другие методы библиотеки requests, такие как requests.post(), requests.put() и requests.delete(), все из которых поддерживают передачу заголовков через параметр headers.
Как отправлять POST запросы с данными в Python

Для отправки POST запросов с данными в Python чаще всего используют библиотеку requests. Она позволяет легко отправлять данные в формате формы, JSON или другого типа. Для этого нужно выполнить несколько простых шагов.
Первым делом необходимо установить библиотеку requests, если она еще не установлена, используя команду:
pip install requests
Для отправки POST запроса с данными формы (тип application/x-www-form-urlencoded) можно использовать следующий код:
import requests
url = 'https://example.com/api'
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post(url, data=data)
print(response.status_code)
print(response.text)
Если нужно отправить данные в формате JSON (тип application/json), необходимо преобразовать данные в JSON и указать правильный заголовок:
import requests
import json
url = 'https://example.com/api'
data = {'key1': 'value1', 'key2': 'value2'}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers)
print(response.status_code)
print(response.json())
Когда необходимо отправить файлы вместе с данными, можно использовать параметр files:
import requests
url = 'https://example.com/upload'
files = {'file': open('example.txt', 'rb')}
response = requests.post(url, files=files)
print(response.status_code)
print(response.text)
Если требуется авторизация для выполнения запроса, можно передать параметры auth:
import requests
from requests.auth import HTTPBasicAuth
url = 'https://example.com/api'
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post(url, data=data, auth=HTTPBasicAuth('username', 'password'))
print(response.status_code)
print(response.text)
Важно учитывать, что данные, отправляемые через POST, могут быть больше, чем при GET-запросах, и сервер должен быть настроен на их прием. Также, всегда следует проверять статус код ответа для диагностики возможных ошибок.
Реализация взаимодействия с REST API через Python
Для взаимодействия с REST API в Python используется библиотека requests, которая позволяет отправлять HTTP-запросы и обрабатывать ответы. Чтобы начать работу с API, необходимо выполнить несколько шагов.
1. Установка библиотеки
Перед тем как начать использовать requests, нужно установить её с помощью команды:
pip install requests2. Основные методы HTTP-запросов
REST API работает с различными методами HTTP, основными из которых являются GET, POST, PUT и DELETE. Для каждого из них в библиотеке requests существуют соответствующие функции.
- GET – используется для получения данных с сервера. Пример:
response = requests.get('https://api.example.com/data')Функция возвращает объект Response, который содержит данные ответа, статусный код и другие параметры.
- POST – применяется для отправки данных на сервер. Пример:
response = requests.post('https://api.example.com/data', json={'key': 'value'})Здесь мы отправляем данные в формате JSON. Для передачи других типов данных можно использовать параметры data или files.
- PUT – используется для обновления существующих данных на сервере. Пример:
response = requests.put('https://api.example.com/data/1', json={'key': 'new_value'})- DELETE – применяется для удаления данных с сервера. Пример:
response = requests.delete('https://api.example.com/data/1')3. Обработка ответа от API
После отправки запроса важно обработать ответ, который приходит от сервера. Ответ хранится в объекте Response, который содержит такие атрибуты как:
response.status_code– статусный код HTTP-ответа (например, 200 для успешного запроса, 404 для ошибки «Не найдено»).response.json()– метод для извлечения данных в формате JSON.response.text– текстовое представление ответа в виде строки.
Пример обработки ответа:
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Ошибка: {response.status_code}")4. Использование заголовков и аутентификации
Для работы с защищёнными API может потребоваться передача заголовков или аутентификационных данных. Например, для использования API с токеном аутентификации можно передать заголовок Authorization:
headers = {'Authorization': 'Bearer YOUR_TOKEN'}
response = requests.get('https://api.example.com/data', headers=headers)Также часто API требует отправки дополнительных данных, например, типа контента:
headers = {'Content-Type': 'application/json'}
response = requests.post('https://api.example.com/data', json={'key': 'value'}, headers=headers)5. Обработка ошибок
Важно предусмотреть обработку ошибок при работе с API. Библиотека requests может сгенерировать исключение в случае проблем с подключением или таймаутом. Для этого используется блок try-except:
try:
response = requests.get('https://api.example.com/data', timeout=10)
response.raise_for_status() # Проверка на ошибки HTTP
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")6. Рекомендации по безопасности
- Не храните токены и ключи API в коде. Используйте переменные окружения или специальные конфигурационные файлы для их хранения.
- Убедитесь, что ваше соединение защищено (HTTPS), чтобы избежать перехвата данных.
- Следите за ограничениями на количество запросов к API (rate limiting), чтобы не нарушить условия использования API.
Таким образом, взаимодействие с REST API через Python с использованием библиотеки requests предоставляет гибкие возможности для работы с внешними сервисами. Важно следить за правильной обработкой ошибок и безопасностью данных.
Работа с cookies и сессиями в HTTP запросах
Для работы с cookies в Python часто используется библиотека `requests`. Основная цель cookies – поддержание состояния между запросами. Пример работы с cookies:
import requests
# Получение cookies с первого запроса
response = requests.get('http://example.com')
cookies = response.cookies
# Отправка cookies с последующим запросом
response = requests.get('http://example.com/dashboard', cookies=cookies)
Важный момент: cookies передаются с каждым запросом на тот же сервер автоматически, если не указаны другие параметры. При этом можно использовать параметры `cookies` для явной передачи данных cookie.
Сессии в HTTP запросах позволяют серверу сохранять данные о пользователе на протяжении нескольких запросов. В Python для работы с сессиями используется объект `Session` из библиотеки `requests`. Он автоматически управляет cookies и позволяет отправлять запросы с теми же параметрами (например, заголовки и cookies), что и в предыдущих запросах. Пример использования сессий:
import requests
# Создание сессии
session = requests.Session()
# Отправка первого запроса
session.get('http://example.com')
# Отправка второго запроса с использованием той же сессии
session.get('http://example.com/dashboard')
Сессия автоматически передаст все cookies, сохраненные с первого запроса, что упрощает работу с авторизацией и состоянием пользователя на протяжении нескольких HTTP-запросов.
Cookies могут содержать различные параметры, такие как время жизни (`expires`), путь (`path`), домен (`domain`), флаг безопасности (`secure`) и флаг HttpOnly. Важно понимать, как эти параметры влияют на работу cookies. Например, флаг `secure` гарантирует, что cookie будет передаваться только через защищенное соединение HTTPS, а `HttpOnly` предотвращает доступ к cookie через JavaScript на клиентской стороне.
Работа с сессиями и cookies требует внимания к безопасности. Например, при хранении cookies на клиенте важно использовать механизмы защиты от CSRF (Cross-Site Request Forgery) и XSS (Cross-Site Scripting). Также следует контролировать время жизни cookies, чтобы минимизировать риск их использования после истечения срока действия.
Сессии и cookies полезны при реализации функционала, требующего аутентификации и сохранения пользовательских настроек. Однако, для того чтобы они были эффективными и безопасными, важно учитывать особенности их реализации на серверной стороне, например, использовать зашифрованные идентификаторы сессий и безопасное управление cookies.
Как настроить прокси для HTTP запросов в Python
Для работы с HTTP-прокси в Python часто используется библиотека requests, которая позволяет легко настроить прокси для всех исходящих запросов. Чтобы подключиться через прокси, достаточно передать нужные параметры в функции запроса.
Основной способ настройки – передача словаря с параметрами прокси в аргумент proxies. Вот пример настройки для одного прокси-сервера:
import requests
proxies = {
"http": "http://username:password@proxyserver:port",
"https": "https://username:password@proxyserver:port"
}
response = requests.get("http://example.com", proxies=proxies)
print(response.text)
В словаре proxies указываются два ключа: http и https, каждый из которых имеет значение URL прокси-сервера. Если прокси требует аутентификацию, в URL можно передать имя пользователя и пароль. Важно использовать правильный протокол: http или https, в зависимости от того, какой протокол требуется для соединения.
Если прокси-сервер не требует аутентификации, пример будет проще:
proxies = {
"http": "http://proxyserver:port",
"https": "https://proxyserver:port"
}
response = requests.get("http://example.com", proxies=proxies)
Для случаев, когда требуется использовать разные прокси для различных типов запросов, можно задать разные параметры для http и https. Если же прокси не нужен для всех запросов, его можно задать только для конкретных.
В некоторых случаях может понадобиться отключить прокси для определённых сайтов. Для этого можно использовать параметр no_proxy:
import requests
proxies = {
"http": "http://proxyserver:port",
"https": "https://proxyserver:port"
}
no_proxy = "example.com"
response = requests.get("http://example.com", proxies=proxies, headers={"No-Proxy": no_proxy})
Для более сложных случаев, например, если нужно динамически переключать прокси в зависимости от ситуации, можно использовать библиотеки, такие как PySocks, для работы с SOCKS-прокси, или настроить прокси на уровне ОС.
Кроме того, важно помнить, что работа через прокси может повлиять на производительность и скорость запросов, так как каждый запрос будет проходить через дополнительный сервер. Поэтому прокси стоит выбирать с учётом этих факторов.
Отладка HTTP запросов и анализ ошибок в Python
Для эффективной отладки HTTP запросов в Python важно использовать инструменты, которые позволят отслеживать запросы, анализировать ответы и выявлять потенциальные ошибки. Один из наиболее распространённых подходов – использование библиотеки requests в сочетании с логированием и отладочными средствами.
Для начала стоит настроить логирование запросов. Библиотека requests позволяет использовать стандартное логирование Python, чтобы записывать все запросы и ответы, включая заголовки и тело. Это поможет понять, что именно отправляется на сервер и какой ответ возвращается.
Пример настройки логирования для HTTP запросов:
import logging
import requests
logging.basicConfig(level=logging.DEBUG)
response = requests.get('https://httpbin.org/get')
import http.client
http.client.HTTPConnection.debuglevel = 1
response = requests.get('https://httpbin.org/get')
Это обеспечит более подробную информацию о каждом запросе, что помогает в анализе проблем, связанных с сетью.
Анализ ошибок HTTP запросов – важный этап в отладке. Проблемы могут быть связаны с различными аспектами: от неверных URL до ошибок на стороне сервера. В Python можно легко обрабатывать такие ошибки с помощью исключений. Пример обработки ошибок:
try:
response = requests.get('https://example.com')
response.raise_for_status() # Возбудит исключение при ошибке HTTP
except requests.exceptions.HTTPError as errh:
print(f"HTTP ошибка: {errh}")
except requests.exceptions.ConnectionError as errc:
print(f"Ошибка соединения: {errc}")
except requests.exceptions.Timeout as errt:
print(f"Ошибка таймаута: {errt}")
except requests.exceptions.RequestException as err:
print(f"Ошибка запроса: {err}")
Такой подход позволяет ловить конкретные типы ошибок и реагировать на них соответствующим образом, например, перезапускать запросы или логировать ошибки для дальнейшего анализа.
Кроме того, полезным инструментом для анализа HTTP ответов является использование кода состояния (status code). Для примера, можно обработать статусный код ответа следующим образом:
if response.status_code == 200:
print("Запрос успешен")
elif response.status_code == 404:
print("Страница не найдена")
elif response.status_code == 500:
print("Ошибка сервера")
else:
print(f"Неверный статус: {response.status_code}")
Применение таких проверок помогает сразу выявить проблему на уровне статуса ответа. Это полезно для быстрого выявления ошибок в процессе взаимодействия с сервером.
Наконец, если запросы взаимодействуют с API, важно удостовериться в правильности отправляемых данных. Применение библиотеки pdb для отладки кода позволяет в реальном времени проверять содержимое запросов и ответов, а также значения переменных на различных этапах выполнения программы.
Вопрос-ответ:
Как Python может взаимодействовать с HTTP сервером?
Python позволяет взаимодействовать с HTTP сервером через различные библиотеки, такие как `requests`, `http.client`, или фреймворки типа `Flask` или `Django`. Обычно для выполнения HTTP-запросов используется библиотека `requests`, которая упрощает процесс отправки GET, POST, PUT и других типов запросов. Это позволяет Python скриптам подключаться к серверу, получать данные и отправлять информацию, например, на веб-сайт или API.
Что такое библиотека requests и как она помогает в работе с HTTP запросами?
Библиотека `requests` — это популярный инструмент для работы с HTTP запросами в Python. Она предоставляет простой и интуитивно понятный интерфейс для отправки HTTP-запросов. С её помощью можно быстро отправлять запросы типа GET, POST, PUT, DELETE и обрабатывать ответы от сервера. Одним из её главных преимуществ является удобство работы с параметрами, заголовками и телом запроса, а также автоматическая обработка ошибок и поддержка различных форматов данных, таких как JSON.
Можно ли обрабатывать данные, полученные с HTTP сервера в Python?
Да, Python позволяет легко обрабатывать данные, полученные с HTTP сервера. Например, с помощью библиотеки `requests` можно получать данные в формате JSON, текст или файл. Для работы с полученными данными используется стандартный модуль `json` для парсинга JSON-ответов. После этого данные можно обрабатывать и анализировать, в зависимости от потребностей приложения. Кроме того, Python поддерживает работу с различными кодировками и может автоматически декодировать содержимое ответа, если это необходимо.
Как создать HTTP сервер с помощью Python?
Для создания простого HTTP сервера в Python можно использовать модуль `http.server`, который позволяет запустить сервер прямо из командной строки. Также можно воспользоваться фреймворками как `Flask` или `Django`, если нужно создавать более сложные веб-приложения. Модуль `http.server` предоставляет базовые возможности для обработки запросов и отправки ответов, в то время как фреймворки позволяют настроить маршруты, обработчики и подключать базы данных.