В Python преобразование строки в нижний регистр – одна из базовых операций работы с текстом. Это действие полезно при обработке пользовательского ввода, сравнения строк, или перед тем как сохранить данные в базу данных, чтобы избежать ошибок из-за различий в регистре символов.
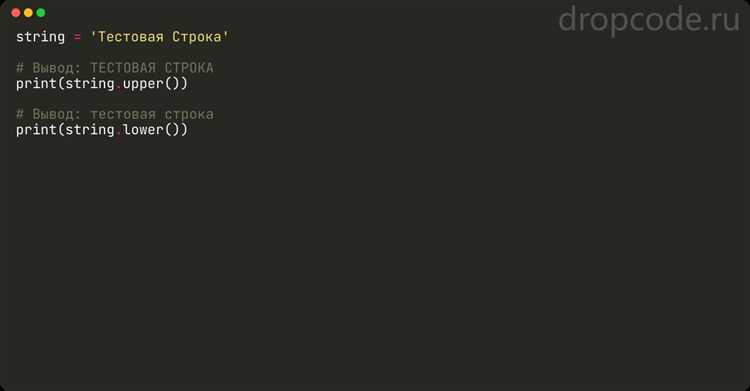
Для преобразования строки в нижний регистр в Python используется метод lower(). Этот метод применим к объектам строк и возвращает новую строку, в которой все символы исходной строки приведены к нижнему регистру. Важно отметить, что метод не изменяет оригинальную строку, а создает новую.
Пример использования метода lower():
text = "Привет, Мир!"
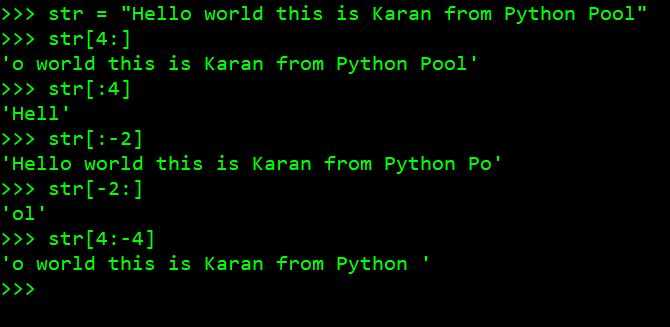
lower_text = text.lower()
Обратите внимание, что метод lower() работает только с буквами. Символы, такие как цифры, знаки препинания или пробелы, остаются неизменными. В случае с кириллицей метод правильно обрабатывает русские буквы, приводя их в нижний регистр.
Если требуется произвести преобразование строки в нижний регистр для сравнения с другой строкой, всегда проверяйте, что обе строки приведены к одному регистру. Это избавит от возможных ошибок при сравнении строк, где одна может быть написана с заглавными буквами, а другая – с маленькими.
Использование метода lower() для преобразования строки
Основное преимущество использования lower() заключается в его простоте и эффективности. Рассмотрим, как он работает:
text = "Python IS Awesome"
result = text.lower()
Как видно из примера, метод преобразует все символы, которые являются буквами, в строчные. Неалфавитные символы, такие как пробелы и знаки препинания, остаются без изменений.
Метод lower() можно использовать в разных сценариях:
- Когда необходимо сравнить строки, игнорируя регистр букв.
- Для обработки пользовательского ввода, например, для стандартизации текста перед сохранением в базу данных.
- При анализе текста, чтобы привести все буквы к одному регистру для удобства дальнейшей обработки.
Пример использования метода для сравнения строк:
input_text = "Hello World"
if input_text.lower() == "hello world":
print("Строки одинаковы!") # Строки одинаковы!
Метод lower() всегда возвращает строку, поэтому важно помнить, что исходная строка не изменяется. Для работы с измененной строкой следует присвоить результат переменной или использовать его напрямую.
Метод lower() не изменяет символы, которые уже находятся в нижнем регистре, что позволяет эффективно использовать его без дополнительных проверок на регистр.
Пример работы с нижним регистром для различных типов данных
В Python преобразование в нижний регистр применяется не только к строкам, но и может быть использовано в разных контекстах. Рассмотрим несколько примеров работы с нижним регистром для различных типов данных.
Строки: Основной тип данных, с которым работает метод lower(), это строки. Например, строка "HELLO World". Для преобразования её в нижний регистр, достаточно вызвать метод lower():
text = "HELLO World"
lower_text = text.lower() # результат: "hello world"
Важно помнить, что метод lower() не изменяет саму строку, а возвращает новую строку в нижнем регистре.
Списки строк: Когда работаешь с коллекциями строк, можно применить метод lower() ко всем элементам списка с помощью map() или генераторов списков:
words = ["HELLO", "WORLD", "PYTHON"]
lower_words = list(map(str.lower, words)) # результат: ['hello', 'world', 'python']
Использование генераторов списков выглядит так:
lower_words = [word.lower() for word in words]
Множества: Если необходимо преобразовать все элементы множества в нижний регистр, можно применить map() или генератор. Например, для множества с различными регистрами:
words_set = {"HELLO", "World", "Python"}
lower_set = {word.lower() for word in words_set} # результат: {'hello', 'world', 'python'}
Словари: Для работы с ключами и значениями словаря также используется метод lower(). Это удобно, если нужно преобразовать все ключи словаря в нижний регистр:
data = {"First": 1, "Second": 2, "THIRD": 3}
lower_data = {key.lower(): value for key, value in data.items()} # результат: {'first': 1, 'second': 2, 'third': 3}
Обработка вводных данных: При получении строковых данных, например, через ввод пользователя, полезно сразу применять lower(), чтобы привести все к единому виду:
user_input = input("Введите команду: ").lower()
Такой подход помогает избежать проблем с чувствительностью к регистру в дальнейшем, например, при сравнении строк.
Использование метода lower() также важно при работе с текстовыми файлами или при анализе текста, где важно игнорировать различия между заглавными и строчными буквами.
Как справиться с символами, которые не меняются при использовании lower()
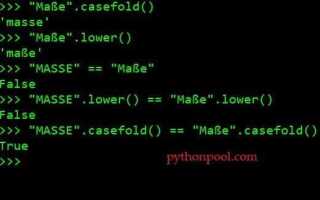
Метод lower() в Python применяется для преобразования строки в нижний регистр. Однако, бывают случаи, когда он не изменяет определенные символы. Это связано с особенностями работы с символами в разных кодировках и алфавитах. В частности, метод lower() не изменяет символы, которые уже находятся в нижнем регистре, и символы, которые не имеют различий между регистрами.
Примером таких символов являются буквы в некоторых алфавитах, такие как латиница с диакритическими знаками (например, é, ç). Для таких символов метод lower() не изменяет их, так как они уже воспринимаются как маленькие буквы, несмотря на наличие дополнительных знаков.
С другой стороны, некоторые символы, например, буквы в определенных языках, могут быть обработаны по-разному. Это касается, например, греческих символов или символов других алфавитов, где существует регистровое различие, но стандартный метод Python может не обеспечить правильное преобразование в нижний регистр для всех символов.
Для более точного контроля за преобразованием можно воспользоваться функциями, обеспечивающими поддержку специфичных языков и символов, например, str.casefold(). Этот метод выполняет более глубокую нормализацию, и он лучше справляется с символами, у которых могут быть разные формы записи в зависимости от регистра.
Чтобы гарантировать правильность преобразования, важно учитывать, что Python использует стандартные правила для разных языков и символов. В случаях, когда необходимо работать с текстом в специфическом алфавите или символами, стоит использовать дополнительные библиотеки, такие как unidecode, которая помогает преобразовывать символы с диакритиками в их базовые формы.
Как преобразовать строку в нижний регистр с учётом локализации
При работе с текстами на разных языках важно учитывать локализацию при преобразовании строки в нижний регистр. Стандартный метод str.lower() в Python не всегда корректно обрабатывает символы, зависящие от языка, например, в турецком языке или других с особыми правилами для букв в верхнем и нижнем регистре.
Для решения этой проблемы Python предоставляет модуль locale, который позволяет учитывать правила локализации при преобразовании строк. Важно правильно установить локаль для корректной работы метода.
Пример преобразования строки с учётом локализации:
- Установите нужную локаль с помощью
locale.setlocale() для корректной работы с символами, специфичными для вашей локали.
- Используйте метод
str.lower(), который будет учитывать локальные особенности преобразования букв.
Пример кода:
import locale
# Устанавливаем локаль для Турции
locale.setlocale(locale.LC_ALL, 'tr_TR.UTF-8')
# Строка с турецкими символами
text = 'Istanbul'
# Преобразуем в нижний регистр с учётом локализации
lower_text = text.lower()
print(lower_text) # istanbul
Для локалей, где важны такие различия, как в турецком языке (где буква 'I' становится 'ı', а 'i' становится 'İ'), метод lower() с учётом локализации будет работать корректно, учитывая все правила преобразования.
Важные замечания:
- Если локаль не установлена или установлена неправильно, метод
str.lower() будет работать без учёта особенностей, что может привести к некорректным результатам.
- Для работы с конкретными языками важно установить правильную локаль перед применением метода
lower().
- При необходимости обработки строк на разных языках используйте библиотеку
pyuca или другие решения для точного учёта локализации.
Учёт локализации важен при разработке многоязычных приложений, так как одно и то же слово может быть преобразовано по-разному в зависимости от языка. Это особенно важно в случаях, когда правильность преобразования влияет на лексикографический порядок или отображение текста.
Методы преобразования строк в нижний регистр при работе с пользовательским вводом
При работе с данными, введенными пользователем, важно учитывать, что ввод может быть в любом регистре. Чтобы обеспечить корректность обработки текста, часто необходимо привести строку к нижнему регистру. В Python для этого можно использовать несколько методов.
Один из самых простых способов – это использование метода lower(), который преобразует все символы строки в нижний регистр. Например, если пользователь вводит строку с переменным регистром, можно использовать input().lower() для приведения всей строки к единому формату:
user_input = input("Введите текст: ").lower()
Этот метод является быстрым и эффективным, но стоит помнить, что он не изменяет саму строку в памяти, а создает новый объект с результатом преобразования. Это важно учитывать, когда работаешь с большими объемами данных.
В случаях, когда необходимо привести только отдельные части строки к нижнему регистру (например, для сравнения данных или проверки ввода), можно комбинировать метод split() для разделения строки на слова и lower() для каждого из них. Это позволяет нормализовать данные, например, при поиске по ключевым словам или фильтрации текста:
keywords = input("Введите ключевые слова: ").split()
keywords_lower = [keyword.lower() for keyword in keywords]
Еще один метод, который стоит упомянуть – это использование регулярных выражений, если требуется более сложная обработка текста. Например, можно использовать библиотеку re, чтобы привести все буквы в строке к нижнему регистру:
import re
user_input = input("Введите текст: ")
user_input = re.sub(r'[A-Z]', lambda x: x.group(0).lower(), user_input)
Это может быть полезно в случаях, когда нужно учитывать только заглавные буквы и оставлять другие символы без изменений.
Преобразование строки в нижний регистр также полезно при сравнении пользовательского ввода с заранее заданными значениями. Например, при вводе команд или параметров, которые могут быть записаны в любом регистре, использование lower() гарантирует, что сравнение будет проводиться корректно:
if user_input.lower() == "yes":
print("Вы согласились")
Методы преобразования строк в нижний регистр в Python просты и удобны для работы с пользовательским вводом, минимизируя вероятность ошибок при анализе текста.
Преобразование строки в нижний регистр через регулярные выражения
Для преобразования строки в нижний регистр с использованием регулярных выражений в Python, можно применить функцию `re.sub()`. Однако стоит отметить, что регулярные выражения сами по себе не предназначены для изменения регистра символов, поэтому нужно комбинировать их с дополнительными методами Python для эффективного выполнения задачи.
Простой пример использования регулярных выражений для замены символов на их эквиваленты в нижнем регистре:
import re
text = "ПрИвЕт Мир!"
lowercase_text = re.sub(r'[A-Za-zА-Яа-яЁё]', lambda x: x.group(0).lower(), text)
print(lowercase_text)
В этом примере `re.sub()` проходит по каждому символу строки, и с помощью функции `lambda` символы, соответствующие регулярному выражению, преобразуются в нижний регистр. Регулярное выражение `[A-Za-zА-Яа-яЁё]` включает все буквы латинского и русского алфавита, как в верхнем, так и в нижнем регистре.
Однако стоит учитывать, что данный способ может быть не самым эффективным при работе с большими объемами текста. В большинстве случаев для преобразования строки в нижний регистр достаточно использовать стандартный метод строк `lower()`, который выполнит задачу быстрее и с меньшими затратами.
Использование регулярных выражений для таких задач оправдано в специфических случаях, когда необходимо преобразовывать только определенные части строки или когда необходимо учитывать сложные паттерны символов.
Вопрос-ответ:
Как в Python преобразовать строку в нижний регистр?
Для того чтобы преобразовать строку в нижний регистр в Python, используется метод `.lower()`. Например, если у вас есть строка `s = "Hello World"`, то `s.lower()` вернёт `"hello world"`. Этот метод не изменяет оригинальную строку, а возвращает новую строку, где все символы переведены в нижний регистр.
Можно ли изменить строку в месте, чтобы она стала в нижнем регистре?
Метод `.lower()` возвращает новую строку, а не изменяет оригинальную, так как строки в Python неизменяемы. Если вы хотите сохранить результат преобразования в той же переменной, нужно просто присвоить результат обратно: `s = s.lower()`. В этом случае переменная `s` будет содержать строку в нижнем регистре.
Какие символы в строке изменяются при применении метода lower()?
Метод `.lower()` изменяет только символы, которые являются буквами, приводя их к нижнему регистру. Все остальные символы, такие как цифры, пробелы, знаки препинания и т. д., остаются без изменений. Например, строка `"Python 3.0!"` после применения метода станет `"python 3.0!"` — цифры и восклицательный знак не изменятся.
Что произойдёт, если строка уже в нижнем регистре и я снова применю метод lower()?
Если строка уже полностью в нижнем регистре, то метод `.lower()` просто вернёт её без изменений. Например, если строка `s = "python"` и вы вызовете `s.lower()`, то результат будет всё та же строка `"python"`. Метод не вызовет ошибок и не повлияет на строку, если она уже соответствует ожидаемому результату.