

Разработка переводчика на Python – это увлекательная задача, которая требует знаний в области обработки естественного языка и работы с API переводов. В отличие от простых программ для перевода текста, полноценный переводчик должен учитывать множество факторов: от сложности языка до особенностей синтаксиса и семантики.
Для начала, важно понимать, что создание такого инструмента можно реализовать несколькими способами. Один из наиболее популярных – это использование библиотек, которые взаимодействуют с уже готовыми решениями, такими как Google Translate или Yandex.Translate. Эти библиотеки позволяют избежать сложных алгоритмов машинного перевода и сфокусироваться на интеграции с внешними сервисами.
Одним из удобных инструментов является библиотека Googletrans, которая позволяет интегрировать API Google Translate в ваш проект. Используя её, можно без проблем переводить текст между десятками языков, при этом не требуя от пользователя глубоких знаний в области машинного обучения. Однако, чтобы избежать ограничений по количеству запросов, рекомендуется использовать прокси-серверы или оптимизировать частоту обращений.
Если цель – разработать более специализированное решение, то стоит рассмотреть создание модели на основе нейронных сетей или использования библиотеки Transformers от Hugging Face. Такие подходы позволяют обучать модель на конкретных языках или жанрах текста, что значительно повышает качество перевода в узкой области, например, в юридических или технических текстах.
Выбор библиотеки для работы с API перевода

Для интеграции переводчиков в Python-проекты важно выбрать подходящую библиотеку, которая обеспечит стабильную и эффективную работу с API перевода. Наиболее популярные библиотеки предлагают разные функциональные возможности, подходящие для различных задач. Рассмотрим несколько ключевых вариантов.
Основные требования к библиотеке для работы с API перевода:
- Поддержка популярных API, таких как Google Translate, Yandex Translate, DeepL и других.
- Простота в использовании и настройке.
- Стабильность и хорошая документация.
- Поддержка асинхронных запросов для повышения производительности при массовых переводах.
Рассмотрим несколько популярных библиотек для работы с API перевода:
- Googletrans (неофициальная библиотека для работы с Google Translate API):
- Очень проста в использовании. Позволяет быстро интегрировать переводчик в проект.
- Поддерживает все языки, доступные в Google Translate.
- Бесплатна, но в силу неофициального статуса могут возникать проблемы с обновлениями и ограничениями от Google.
- DeepL (официальная библиотека для работы с DeepL API):
- Предлагает высококачественные переводы, особенно для европейских языков.
- Поддерживает как бесплатную версию с ограничениями, так и платные планы с расширенными возможностями.
- Преимущество – это качество перевода, которое часто превосходит конкурентов, особенно для технического текста.
- translate (библиотека для работы с несколькими API):
- Предоставляет интерфейс для нескольких сервисов перевода, таких как Google Translate, Yandex и Microsoft Translator.
- Позволяет легко переключаться между API, в зависимости от предпочтений или требований проекта.
- Удобна для проектов, где необходимо поддерживать несколько сервисов перевода.
- Yandex Translate (официальная библиотека для работы с Yandex.Translate API):
- Подходит для проектов, ориентированных на российскую аудиторию.
- Обеспечивает стабильную работу и точные переводы, особенно на языки СНГ.
- API имеет бесплатный тариф с ограничениями по количеству запросов.
- mtranslate (легкая библиотека для работы с Google Translate API):
- Минималистичный инструмент с простым API для перевода текста.
- Поддерживает несколько языков и базируется на Google Translate.
- Обладает ограниченными возможностями в сравнении с более сложными решениями, но подходит для небольших проектов.
При выборе библиотеки следует учитывать следующие факторы:
- Цена и ограничения: Некоторые библиотеки могут иметь ограничения на количество запросов в бесплатной версии, что нужно учитывать при масштабировании проекта.
- Надежность и поддержка: Библиотеки с активным сообществом и поддержкой обновлений обеспечат стабильную работу и минимизируют риски сбоев.
- Качество перевода: У разных сервисов перевода есть свои сильные стороны. Например, DeepL отлично справляется с европейскими языками, а Yandex – с русским и языками СНГ.
Лучший выбор зависит от конкретных потребностей проекта. Для простых приложений Googletrans и mtranslate подойдут отлично, для более профессиональных решений с необходимостью высокого качества перевода стоит рассмотреть DeepL или Yandex Translate.
Подключение и настройка Google Translate API на Python
Для создания переводчика с использованием Google Translate API, необходимо выполнить несколько шагов. Начнём с подготовки и установки необходимых инструментов для работы с API.
1. Перейдите на консоль Google Cloud: https://console.cloud.google.com/. Создайте новый проект или выберите существующий.
2. В панели управления проектом откройте раздел «API и сервисы» и выберите «Библиотека». Найдите и активируйте «Cloud Translation API». Это позволит вашему проекту использовать переводчик Google для выполнения перевода текста.
3. После активации API, перейдите в раздел «Учетные данные» и создайте новый API-ключ. Скопируйте ключ, он понадобится для настройки соединения с API.
4. Для работы с API через Python потребуется библиотека `google-cloud-translate`. Установите её с помощью команды:
pip install google-cloud-translate
5. Теперь настройте аутентификацию. Создайте файл с ключом, скачав его в формате JSON в разделе «Учетные данные». Укажите путь к файлу ключа в переменной окружения GOOGLE_APPLICATION_CREDENTIALS, чтобы Python мог авторизоваться:
export GOOGLE_APPLICATION_CREDENTIALS="path_to_your_service_account_file.json"
6. Теперь можно приступать к использованию API. Пример базового кода для перевода текста:
from google.cloud import translate_v2 as translate def translate_text(text, target_language): client = translate.Client() result = client.translate(text, target_lang=target_language) return result['translatedText'] text = "Hello, world!" translated_text = translate_text(text, 'ru') print(translated_text)
Обратите внимание, что использование Google Translate API требует оплаты. Тарифы можно найти в документации Google Cloud, и они зависят от объема переводимого текста. Для небольших проектов может подойти бесплатный лимит API, который предоставляет несколько миллионов знаков в месяц.
Настроив и подключив API, вы сможете интегрировать мощные функции перевода в своё приложение или проект на Python.
Как реализовать поддержку нескольких языков в одном приложении
Для создания переводчика, поддерживающего несколько языков, необходимо обеспечить гибкость и масштабируемость приложения. Один из наиболее эффективных способов – использовать структуру, которая разделяет логику перевода и данные о языках. Это позволяет добавлять новые языки с минимальными изменениями в коде.
1. Структура хранения данных о языках
Для поддержки нескольких языков полезно хранить переводы в отдельных файлах или базах данных. Один из популярных форматов для этого – JSON. В файле можно указать переводы для каждой фразы или слова на всех поддерживаемых языках. Пример структуры JSON-файла:
{
"en": {
"hello": "Hello",
"world": "World"
},
"ru": {
"hello": "Привет",
"world": "Мир"
},
"fr": {
"hello": "Bonjour",
"world": "Monde"
}
}
2. Выбор языка пользователем
В приложении нужно предусмотреть механизм выбора языка. Это можно реализовать через интерфейс, предоставляя пользователю список доступных языков. Для удобства можно сохранять предпочтения пользователя в локальном хранилище или базе данных.
3. Логика перевода
Для каждого перевода создается функция, которая извлекает текст на нужном языке из выбранного источника (например, JSON-файла или базы данных). Пример кода:
import json
def load_translations(language):
with open(f'translations_{language}.json', 'r', encoding='utf-8') as f:
return json.load(f)
def translate(word, language):
translations = load_translations(language)
return translations.get(word, word)
4. Обработка ошибок
5. Поддержка дополнительных языков
Для добавления новых языков достаточно создать новый JSON-файл с переводами и обновить логику выбора языка. Это позволяет масштабировать приложение без значительных изменений в коде.
6. Автоматическое определение языка
Для повышения удобства можно интегрировать библиотеку, которая автоматически определяет язык текста. Это можно сделать с помощью таких библиотек, как langdetect или langid, которые анализируют входной текст и возвращают предполагаемый язык.
7. Интернационализация и локализация
Кроме перевода текста, важно учитывать региональные особенности. Важно, чтобы приложение поддерживало не только перевод, но и особенности даты, времени, чисел и валют. Для этого можно использовать библиотеку babel, которая предоставляет инструменты для работы с локализованными форматами данных.
Таким образом, создание многоязычного переводчика требует правильной организации данных, гибкости в добавлении новых языков и внимательности к локализации приложения в целом.
Обработка ошибок и неточных переводов в системе
При создании переводчика на Python важно учитывать возможность ошибок и неточных переводов, которые неизбежны в любом автоматическом переводе. Основные источники таких проблем – ограничения алгоритмов, контекстные ошибки и специфические особенности языков. Одна из ключевых задач – эффективно обрабатывать эти ситуации, чтобы минимизировать влияние на пользовательский опыт.
Для обнаружения и корректировки ошибок можно использовать несколько подходов. Один из них – интеграция различных переводческих API, таких как Google Translate или Yandex.Translate. Эти сервисы имеют встроенные механизмы для обнаружения и обработки ошибок, включая возвращение информации о проблемах в запросе или ошибках при переводе.
Однако, даже при использовании готовых решений, перевод может быть неточным из-за отсутствия контекста. Например, одно и то же слово может переводиться по-разному в зависимости от контекста. Для решения этой проблемы важно использовать дополнительные алгоритмы для распознавания контекста, такие как нейросетевые модели, которые обучаются на больших корпусах текстов и способны лучше распознавать значение слов в зависимости от их окружения. В Python для этого можно использовать библиотеки, такие как Hugging Face Transformers, которые позволяют интегрировать современные модели перевода, учитывающие контекст.
Еще один важный аспект – работа с синтаксическими и грамматическими ошибками. Некоторые фразы могут быть грамматически правильными, но их перевод может быть неестественным из-за различий в структуре предложений. Чтобы минимизировать такие ошибки, рекомендуется использовать пост-обработку перевода с применением алгоритмов исправления грамматических ошибок. Например, можно интегрировать инструменты для проверки грамматики и стиля, такие как LanguageTool или Grammarly API, которые помогут автоматизировать исправление ошибок после перевода.
Не стоит забывать и о факторах, влияющих на качество перевода. Например, использование сленга, идиоматических выражений или терминологии из узкоспециализированных областей может привести к неправильному переводу. Для таких случаев желательно включать в систему возможность обучения на специфичных текстах или использовать тематические словари для улучшения точности перевода.
Для выявления и исправления неточных переводов можно реализовать систему самопроверки на основе сравнений с эталонными переводами или с использованием обратного перевода. Такой подход позволяет обнаружить отклонения от правильного перевода и предложить альтернативные варианты.
В результате, обработка ошибок и неточных переводов требует комплексного подхода, включающего использование нескольких алгоритмов и сервисов, постоянное обновление моделей и возможность обучения системы на новых данных. Это позволит улучшить качество перевода и минимизировать влияние ошибок на итоговый результат.
Как работать с текстами разной длины и сложностью

При разработке переводчика на Python важно учитывать разнообразие текстов по длине и сложности. Подход к их обработке может значительно повлиять на качество перевода и эффективность работы программы.
Для коротких текстов, таких как фразы или предложения, основное внимание следует уделить точности перевода и контексту. Для таких случаев можно использовать модели машинного перевода, как Google Translate API или DeepL API, которые обеспечивают высокое качество перевода при минимальных усилиях. Однако важно помнить, что при переводе коротких фраз модель может не всегда правильно интерпретировать контекст, особенно при наличии амфиболий (двусмысленных выражений).
Сложность перевода увеличивается с ростом длины текста. Для длинных текстов, например, статей или книг, ключевым становится разделение текста на меньшие логические блоки. Это можно сделать с помощью техник, таких как разделение на предложения или разделение на параграфы. Применение таких методов позволяет повысить точность перевода, предотвращая ошибки, возникающие при попытке перевести слишком большие объёмы текста за один раз.
Для обработки сложных текстов с технической или специализированной лексикой необходимы дополнительные инструменты. Например, можно интегрировать специализированные базы данных или словари для конкретных областей (медицина, IT, право). Важно учитывать, что стандартные модели перевода могут давать неточные результаты в таких случаях, поэтому нужно либо обучать модель на соответствующем корпусе текстов, либо использовать готовые решения, такие как Microsoft Translator API с поддержкой специализированных терминов.
Для повышения качества перевода на всех уровнях можно использовать методы предобработки текста. Например, лемматизация и токенизация помогут лучше понять структуру предложения и улучшить точность перевода. В Python для этих целей удобно использовать библиотеки, такие как spaCy и NLTK.
Наконец, для текста разной длины и сложности важно обеспечить согласованность перевода. Это особенно важно при переводе больших объёмов информации, где контекст может изменяться в зависимости от места в тексте. Для этого можно использовать механизмы памяти перевода (например, Translation Memory), чтобы сохранить уже переведённые фразы и использовать их в дальнейшем для улучшения качества и скорости перевода.
Оптимизация времени отклика при запросах к API
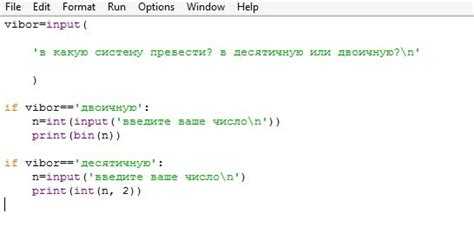
1. Использование асинхронных запросов. В синхронном режиме каждое API-запрос блокирует выполнение программы до получения ответа. Это можно исправить с помощью асинхронных запросов. Библиотеки вроде aiohttp позволяют отправлять запросы и продолжать выполнение программы, не дожидаясь их завершения. В случае нескольких одновременных запросов, использование асинхронности может значительно сократить время отклика.
2. Параллельные запросы. Если API позволяет выполнять несколько запросов одновременно (например, для получения данных о разных языках), следует использовать многозадачность или параллельные запросы. В Python для этого можно воспользоваться библиотеками concurrent.futures или multiprocessing. Это позволяет эффективно распределить нагрузку между несколькими потоками или процессами, что ускоряет обработку данных.
3. Кэширование ответов. Если приложение часто запрашивает одни и те же данные, разумным шагом будет использование кэширования. Библиотеки, такие как requests-cache, позволяют сохранять ответы API в локальном кэше и повторно использовать их без повторных запросов. Это особенно полезно для редких или долгих запросов, которые не требуют актуализации данных в реальном времени.
4. Сжатие данных. Множество API поддерживают сжатие передаваемых данных. Включение сжатия, например с использованием алгоритма gzip, позволяет уменьшить размер передаваемых данных и сократить время передачи. Для этого можно использовать соответствующие заголовки в запросах, такие как Accept-Encoding: gzip.
5. Оптимизация структуры запросов. Важно убедиться, что запросы к API не содержат лишних данных. Снижение размера запроса за счет удаления ненужных параметров и уточнение необходимых полей в ответах поможет ускорить обмен данными. Например, при работе с REST API часто используется параметр fields для указания только нужных полей, что минимизирует объем передаваемой информации.
6. Использование ближайших серверов. Местоположение сервера API также влияет на время отклика. При возможности следует использовать сервера, расположенные ближе к конечному пользователю, или использовать сети доставки контента (CDN), которые могут кэшировать данные на узлах по всему миру и ускорить доступ.
7. Профилирование запросов. Для точной оценки времени отклика необходимо регулярно профилировать запросы. Использование инструментов, таких как time и cProfile в Python, поможет выявить узкие места в производительности и оптимизировать их.
Сочетание этих методов позволяет создать эффективный и быстрый переводчик, минимизируя задержки и улучшая пользовательский опыт. Важно учитывать требования API и настраивать приложение для работы с максимально возможной производительностью, избегая лишних операций и делая запросы максимально быстрыми и точными.
Добавление пользовательских настроек для выбора языков и стилей перевода

Для создания переводчика, который учитывает предпочтения пользователя, важно предоставить возможность выбора языков и стилей перевода. Это можно реализовать с помощью интерфейсов и настроек, которые позволят гибко управлять процессом перевода.
Выбор языков можно реализовать через выпадающий список или радиокнопки, которые позволяют пользователю выбрать исходный и целевой язык. Для этого потребуется использовать библиотеки, такие как googletrans или translate, которые поддерживают множественные языковые пары. Пример базового выбора языков:
from googletrans import Translator
translator = Translator()
result = translator.translate('Привет мир', src='ru', dest='en')
print(result.text)
В этом примере создается переводчик, который переводит текст с русского на английский. Для улучшения UX, можно добавить динамическую загрузку доступных языков с API выбранной библиотеки.
Добавление настроек стилей перевода важно для удовлетворения потребностей пользователей, которые могут предпочитать определенную манеру перевода (формальная, неформальная, литературная и т.д.). В этом случае потребуется добавить настройки, которые будут учитывать контекст и стиль. Например, можно предложить пользователю выбирать между «официальным» или «разговорным» стилем перевода, если библиотека это поддерживает.
Для реализации этого можно добавить в интерфейс дополнительные параметры, такие как переключатели или текстовые поля для ввода предпочтений. Важно понимать, что выбор стиля может потребовать более сложной обработки, так как стандартные API переводчиков часто ограничены в плане настраиваемости стиля. Тем не менее, многие API, например, DeepL, уже предлагают функционал, который позволяет выбирать стиль перевода (формальный, неформальный).
Пользовательский интерфейс для выбора языков и стилей перевода должен быть интуитивно понятным. Важно, чтобы пользователь мог легко переключаться между различными языками и стилями, а также получать быстрые результаты. Можно использовать простые формы с выпадающими списками или кнопками, а также добавить функцию автозаполнения для поиска языков.
Персонализированные настройки можно сохранять в файлах конфигурации или базах данных. Это позволит пользователю настраивать приложение один раз и использовать его без необходимости повторного выбора параметров при каждом запуске. Например, можно хранить последние выбранные языковые пары и предпочтения пользователя в файле или базе данных SQLite.
Вопрос-ответ:
Как создать переводчик на Python для разных языков?
Для создания переводчика на Python можно использовать библиотеки, такие как `googletrans` или `DeepL`. Эти инструменты позволяют взаимодействовать с API популярных переводческих сервисов. Простой переводчик можно создать с помощью библиотеки `googletrans`, которая подключается к API Google Translate. Важно учитывать, что для работы с API, возможно, потребуется зарегистрироваться и получить ключ доступа. В дополнение к этому, полезно будет реализовать обработку ошибок, так как перевод может зависеть от качества интернет-соединения или изменения API.
Какие библиотеки Python лучше всего подходят для создания переводчиков?
Для создания переводчиков на Python стоит обратить внимание на несколько популярных библиотек. Одна из них — это `googletrans`, которая использует API Google Translate и поддерживает множество языков. Вторая — `translate`, которая предоставляет простой интерфейс для перевода текста с использованием различных сервисов, например, Yandex Translate. Для более сложных решений можно использовать библиотеку `DeepL`, которая также имеет API для работы с переводами и поддерживает высокое качество перевода для нескольких языков.
Как обеспечить работу переводчика с несколькими языками одновременно?
Для обеспечения поддержки нескольких языков в переводчике можно использовать массив или словарь для хранения языков. В библиотеке `googletrans` можно явно указывать исходный и целевой языки через параметры `src` и `dest`. Например, для перевода с русского на английский достаточно указать `src=’ru’` и `dest=’en’`. Если необходимо поддерживать множество языков, можно предоставить пользователю интерфейс для выбора языка, либо автоматически определять язык исходного текста с помощью метода `detect` из той же библиотеки.
Можно ли использовать бесплатные API для перевода текста, и насколько они точны?
Да, существует несколько бесплатных API для перевода, таких как Google Translate (через `googletrans`), Yandex Translate и другие. Бесплатные API часто имеют ограничения по количеству запросов или скорости обработки, но для небольших проектов они вполне подходят. Что касается точности, то бесплатные сервисы обычно обеспечивают хороший уровень перевода для большинства языков, но сложные фразы и специфическая лексика могут быть переведены не всегда идеально. Для более точных переводов стоит рассматривать платные сервисы, такие как DeepL.
Как улучшить точность перевода в проекте на Python?
Чтобы повысить точность перевода, можно воспользоваться несколькими подходами. Во-первых, стоит выбрать API, который предоставляет наилучшее качество перевода для нужных языков, например, DeepL. Во-вторых, можно оптимизировать вводимые данные, разбивая длинные предложения на более короткие и простые фразы, что помогает сервисам правильно интерпретировать текст. Также стоит учитывать контекст при переводе, что может быть сложной задачей, и иногда потребуется вручную настраивать систему, чтобы улучшить точность.





