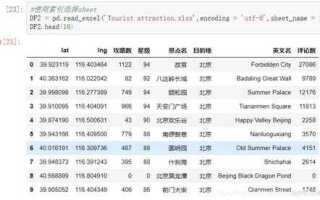
Формат CSV широко используется для обмена табличными данными между различными системами. В Python для работы с CSV-файлами доступен встроенный модуль csv, а также внешние библиотеки, такие как pandas. Использование этих инструментов позволяет сохранять данные с заданными разделителями, кодировкой и структурой строк без лишних преобразований.
Модуль csv позволяет создавать и записывать строки поэлементно. Функция csv.writer используется для последовательной записи строк в файл. Чтобы задать собственный разделитель (например, точку с запятой), необходимо указать параметр delimiter. Также важно установить newline=» при открытии файла, чтобы избежать появления пустых строк в Windows.
Библиотека pandas упрощает процесс записи, особенно при работе с большими наборами данных. Метод DataFrame.to_csv() позволяет быстро сохранить таблицу с нужной кодировкой (например, utf-8 или cp1251), без индексов (index=False) и с конкретным разделителем (sep=’;’).
При работе с кириллическими символами стоит избегать стандартной кодировки ascii – вместо неё безопаснее использовать utf-8-sig, особенно если файл предназначен для открытия в Microsoft Excel. Это предотвращает некорректное отображение символов и избавляет от необходимости ручной перекодировки.
Как сохранить данные в CSV с помощью Python
Для записи данных в CSV-файл используйте модуль csv, входящий в стандартную библиотеку Python. Он поддерживает как построчную запись, так и запись из словарей с автоматическим определением заголовков.
Обычная запись в CSV начинается с открытия файла в режиме ‘w’ с указанием newline=», чтобы избежать лишних пустых строк в Windows:
with open(‘output.csv’, ‘w’, newline=», encoding=’utf-8′) as f:
writer = csv.writer(f)
writer.writerow([‘Имя’, ‘Возраст’, ‘Город’])
writer.writerow([‘Анна’, 28, ‘Москва’])
Если данные представлены в виде списка словарей, удобнее использовать csv.DictWriter. Он требует явного указания полей в параметре fieldnames:
data = [{‘Имя’: ‘Иван’, ‘Возраст’: 35, ‘Город’: ‘Тверь’},
{‘Имя’: ‘Ольга’, ‘Возраст’: 42, ‘Город’: ‘Казань’}]
with open(‘users.csv’, ‘w’, newline=», encoding=’utf-8′) as f:
writer = csv.DictWriter(f, fieldnames=[‘Имя’, ‘Возраст’, ‘Город’])
writer.writeheader()
writer.writerows(data)
Для изменения разделителя укажите параметр delimiter. Например, для использования точки с запятой:
writer = csv.writer(f, delimiter=’;’)
При работе с Unicode всегда задавайте encoding=’utf-8′, иначе возможны ошибки при чтении файла сторонними программами.
Если требуется сохранить данные в виде строки без записи в файл, используйте io.StringIO вместо файла. Это удобно при передаче CSV по сети или в буфер обмена.
Сохранение списка словарей в CSV с помощью модуля csv
Для записи списка словарей в CSV-файл используйте модуль csv и класс DictWriter. Это позволяет сохранить ключи словаря в качестве заголовков столбцов, а значения – как строки таблицы.
Пример:
import csv
данные = [
{"имя": "Алексей", "возраст": 30, "город": "Москва"},
{"имя": "Мария", "возраст": 25, "город": "Санкт-Петербург"},
{"имя": "Иван", "возраст": 35, "город": "Новосибирск"}
]
с_открытым_файлом = open("люди.csv", "w", newline="", encoding="utf-8")
с = csv.DictWriter(с_открытым_файлом, fieldnames=["имя", "возраст", "город"])
с.writeheader()
с.writerows(данные)
с_открытым_файлом.close()Убедитесь, что ключи в словарях совпадают с заголовками, переданными в fieldnames. Очерёдность заголовков определяет порядок столбцов в файле.
Параметр newline="" предотвращает добавление лишних пустых строк в Windows. Указание encoding="utf-8" обеспечивает корректное сохранение кириллических символов.
Если порядок ключей не совпадает или отсутствуют какие-либо значения, DictWriter не выбрасывает ошибку, но в результирующем файле появятся пустые ячейки. При необходимости проверяйте данные заранее.
Указание названий столбцов при записи в CSV
Для сохранения данных в CSV с заданными названиями столбцов удобно использовать модуль csv из стандартной библиотеки Python. При использовании csv.DictWriter необходимо заранее определить список заголовков и явно записать их с помощью метода writeheader().
Пример:
import csv
данные = [
{"Фамилия": "Иванов", "Имя": "Иван", "Возраст": 30},
{"Фамилия": "Петров", "Имя": "Пётр", "Возраст": 25}
]
с_открытием("файл.csv", "w", newline="", encoding="utf-8") as файл:
поля = ["Фамилия", "Имя", "Возраст"]
writer = csv.DictWriter(файл, fieldnames=поля)
writer.writeheader()
writer.writerows(данные)
Если пропустить вызов writeheader(), файл будет содержать только строки с данными без заголовков. Порядок полей в fieldnames определяет расположение столбцов в CSV. Для записи только части полей необходимо исключить ненужные ключи или сформировать новые словари с нужным набором данных.
Если исходные словари содержат ключи, которых нет в fieldnames, и используется строгий режим (extrasaction='raise'), возникнет исключение. Чтобы игнорировать лишние поля, задаётся extrasaction='ignore':
writer = csv.DictWriter(файл, fieldnames=поля, extrasaction='ignore')Порядок действий: задать заголовки, создать объект DictWriter с нужными параметрами, вызвать writeheader(), затем writerows() или writerow() для поочерёдной записи строк.
Запись строк по одной в файл CSV
Для построчной записи используется модуль csv, входящий в стандартную библиотеку. Он обеспечивает корректную обработку разделителей, кавычек и кодировок. Работа с файлом начинается с открытия его в режиме ‘w’ или ‘a’ (если требуется дозапись), с указанием newline=», чтобы избежать появления пустых строк в Windows.
Создаётся объект csv.writer, которому можно передавать списки для записи. Каждая строка добавляется вызовом writer.writerow(). Формат списка должен строго соответствовать ожидаемой структуре файла, включая порядок и количество элементов.
Пример:
import csv
with open('данные.csv', 'w', newline='', encoding='utf-8') as файл:
writer = csv.writer(файл)
writer.writerow(['Имя', 'Возраст', 'Город'])
writer.writerow(['Анна', 29, 'Москва'])
writer.writerow(['Иван', 34, 'Самара'])Если строки формируются динамически, запись можно выполнять в цикле:
данные = [
['Мария', 22, 'Казань'],
['Олег', 41, 'Екатеринбург']
]
with open('люди.csv', 'a', newline='', encoding='utf-8') as файл:
writer = csv.writer(файл)
for строка in данные:
writer.writerow(строка)Следует контролировать длину списков перед записью, особенно при работе с пользовательским вводом или внешними источниками. Несоответствие количеству столбцов приведёт к структурным ошибкам при последующем чтении.
Для автоматического экранирования специальных символов, таких как запятые и кавычки, достаточно полагаться на поведение csv.writer без ручной обработки текста. Это избавляет от необходимости вручную заключать значения в кавычки.
Использование pandas для сохранения DataFrame в CSV
- Для сохранения без индекса используется параметр
index=False:df.to_csv("output.csv", index=False) - Чтобы задать кодировку, например
utf-8-sigдля корректного открытия в Excel:df.to_csv("output.csv", index=False, encoding="utf-8-sig") - Разделитель можно изменить с запятой на точку с запятой:
df.to_csv("output.csv", sep=";", index=False) - Если требуется сохранить только определённые столбцы:
df.to_csv("output.csv", columns=["col1", "col2"], index=False) - Чтобы не сохранять заголовки:
df.to_csv("output.csv", index=False, header=False)
Метод to_csv() также поддерживает потоковую запись в файл через объект file, что удобно при работе с временными файлами или HTTP-ответами.
with open("output.csv", "w", encoding="utf-8") as f:
df.to_csv(f, index=False)При использовании нестандартных форматов данных рекомендуется указать параметры date_format и float_format, чтобы сохранить форматирование чисел и дат:
df.to_csv("output.csv", index=False, date_format="%Y-%m-%d", float_format="%.2f")Настройка кодировки и разделителя при сохранении CSV
При сохранении данных в CSV важно учитывать кодировку и разделитель, чтобы файл корректно отображался и обрабатывался на разных системах. Python предоставляет гибкие средства для работы с этими параметрами через модуль csv.
По умолчанию модуль csv использует разделитель запятую («,») и кодировку utf-8, но эти значения можно изменить в зависимости от потребностей.
Настройка разделителя
Для задания собственного разделителя в CSV-файле нужно указать параметр delimiter при открытии файла для записи. Это полезно, например, при работе с данными, где в качестве разделителя используется точка с запятой или табуляция.
delimiter=";"– разделитель, если данные имеют структуру с точкой с запятой.delimiter="\t"– используется для табуляции.
Пример записи данных с изменённым разделителем:
import csv
data = [["Имя", "Возраст"], ["Иван", 25], ["Анна", 30]]
with open("data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file, delimiter=";")
writer.writerows(data)Настройка кодировки
При работе с кодировками важно учитывать, что некоторые системы или приложения требуют особую кодировку для корректного отображения данных. Наиболее часто используемая кодировка для CSV – это utf-8, но в некоторых случаях может потребоваться использование других, например, utf-16 или windows-1251.
encoding="utf-8"– стандартная кодировка, поддерживаемая большинством современных программ.encoding="windows-1251"– полезно для работы с русскоязычными данными в старых системах.encoding="utf-16"– применяется, если данные содержат символы, которые не поддерживаются вutf-8.
Пример записи с другой кодировкой:
with open("data_utf16.csv", mode="w", newline="", encoding="utf-16") as file:
writer = csv.writer(file, delimiter=",")
writer.writerows(data)Примечания
- Не стоит использовать кодировку
utf-8с BOM для работы с CSV в Python, так как это может привести к неожиданному поведению при чтении данных в других программах. - Для обработки данных с нестандартными символами используйте кодировку
utf-16, которая гарантирует поддержку большинства международных символов. - При работе с большими объемами данных стоит учитывать производительность при выборе кодировки. Например,
windows-1251быстрее, но ограничена только определённым набором символов.
Добавление данных в существующий CSV-файл
Чтобы добавить новые строки в уже существующий CSV-файл, можно использовать модуль csv из стандартной библиотеки Python. Вместо того чтобы перезаписывать файл, можно открыть его в режиме добавления (append mode) и записать новые данные.
Для этого откроем файл с использованием режима ‘a’ (append), что позволяет добавлять данные в конец без удаления старых. Важно также учитывать правильный формат данных для корректной записи.
Пример кода:
import csv
# Данные для добавления
new_data = ['Мария', '25', 'Москва']
# Открываем файл в режиме добавления
with open('data.csv', mode='a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# Записываем данные
writer.writerow(new_data)
В данном примере добавляется одна строка с информацией о человеке в существующий CSV-файл. Обратите внимание на использование параметра newline=» , чтобы избежать появления лишних пустых строк при записи.
Если структура файла изменится, например, если количество столбцов увеличится, важно удостовериться, что данные, которые добавляются, соответствуют структуре текущего файла. Ошибки могут возникнуть, если количество элементов в списке не совпадает с количеством колонок в файле.
Также стоит помнить, что если файл будет открыт с параметром ‘a’ и в нем нет заголовков, то новая строка будет добавлена без заголовков. Если вам нужно обновить заголовки, это следует делать отдельно.
Обработка спецсимволов и кавычек при сохранении
При сохранении данных в CSV-формат важно учитывать обработку спецсимволов и кавычек, чтобы избежать ошибок при чтении файлов или искажений информации.
Основные проблемы возникают с символами, которые могут быть интерпретированы как разделители или кавычки, такими как запятые, кавычки и новые строки. Для корректного сохранения данных в таких случаях используют экранирование и оборачивание значений в кавычки.
1. Экранирование спецсимволов
В Python для экранирования можно использовать символ обратной косой черты (\). Это важно, когда в данных встречаются символы, которые могут быть восприняты как разделители или маркеры конца строки.
- Если в значении встречается запятая, она не будет проблемой, если данные заключены в кавычки.
- Для кавычек внутри строки можно использовать две кавычки подряд. Например, значение
O'Reillyбудет записано как"O''Reilly".
2. Кавычки в данных
Строки, содержащие запятые, новые строки или кавычки, необходимо оборачивать в двойные кавычки. Если в строке есть сами двойные кавычки, их экранируют с помощью двух кавычек подряд.
- Пример записи строки с кавычками:
"She said, ""Hello!"" and left." - Запись строки с новой строкой:
"Hello, world" and "Python is fun"
3. Использование параметра quoting в Python
При работе с библиотекой csv можно использовать параметр quoting, чтобы автоматически управлять кавычками. Это гарантирует, что все значения с разделителями или кавычками будут правильно обрабатываться.
csv.QUOTE_MINIMAL– кавычки ставятся только вокруг значений, содержащих спецсимволы.csv.QUOTE_ALL– кавычки ставятся вокруг всех значений.csv.QUOTE_NONNUMERIC– кавычки ставятся только вокруг строковых значений.csv.QUOTE_NONE– кавычки не используются, необходимо экранировать спецсимволы вручную.
4. Пример кода для обработки спецсимволов
Пример использования библиотеки csv для сохранения данных с учётом кавычек и спецсимволов:
import csv
data = [["John, Doe", "25", "Developer"], ["Jane", "O'Reilly", "30", "Designer"]]
with open('data.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file, quoting=csv.QUOTE_MINIMAL)
writer.writerows(data)
В данном примере имена с запятой и апострофом будут правильно обработаны, а вокруг этих значений будут поставлены кавычки.
Сохранение CSV без индекса в pandas
Для сохранения данных в CSV без индекса в pandas достаточно использовать параметр index=False в методе to_csv(). Это предотвратит добавление индекса в итоговый файл, что может быть полезно при экспорте данных, где индекс не имеет значения.
Пример:
import pandas as pd
Создаем DataFrame
data = {'Название': ['Алексей', 'Мария', 'Дмитрий'],
'Возраст': [28, 22, 35]}
df = pd.DataFrame(data)
Сохраняем в CSV без индекса
df.to_csv('output.csv', index=False)
В этом примере в CSV-файл будет записана только информация о людях, без столбца с индексами. В случае, если индекс важен, но его нужно сохранить отдельно, можно использовать параметр index_label для задания имени столбца индекса.
Еще один момент: параметр header=True по умолчанию сохраняет заголовки колонок в первой строке. Если они не нужны, можно установить header=False.
Для более сложных сценариев, например, когда необходимо исключить индекс в условных случаях, можно использовать условные конструкции перед вызовом to_csv().