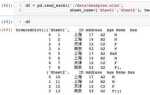
При работе с данными в Python часто возникает задача сравнения двух списков. Это может быть поиск различий между результатами двух вычислений, анализ изменений в структуре данных или проверка на идентичность содержимого. Способы сравнения зависят от контекста: важен ли порядок элементов, наличие дубликатов, типы данных или производительность.
Для прямого сравнения списков используется оператор ==, который проверяет совпадение элементов и их порядка. Однако, если важна только уникальность значений без учёта порядка, эффективнее использовать множества и конструкции вида set(a) == set(b). Такой подход не учитывает количество повторов, но позволяет быстро определить эквивалентность содержимого.
Когда важно учитывать дубликаты, но порядок не играет роли, применяют collections.Counter. Сравнение Counter(a) == Counter(b) покажет, совпадают ли элементы и их количество. Этот способ полезен при анализе составов списков или подсчёте совпадений в наборах данных.
Если нужно выявить различия – какие элементы есть в одном списке, но отсутствуют в другом – используют операции разности между множествами: set(a) — set(b) и наоборот. Для более детального анализа различий с сохранением порядка можно воспользоваться списковыми включениями, например: [x for x in a if x not in b].
При больших объёмах данных критично учитывать производительность. Простое сравнение с использованием циклов может привести к резкому снижению скорости. В таких случаях рекомендуется предварительное преобразование списков в множества или использование специализированных библиотек, таких как numpy для числовых данных или pandas при работе с табличными структурами.
Проверка на полное совпадение списков с учётом порядка элементов
Если важен порядок элементов, простое сравнение списков с помощью оператора == – наиболее надёжный и быстрый способ:
list1 = [1, 2, 3]
list2 = [1, 2, 3]
result = list1 == list2 # TrueЭто сравнение учитывает как длину, так и точное расположение элементов. Подходит для всех типов, включая вложенные структуры:
list1 = [[1, 2], [3, 4]]
list2 = [[1, 2], [3, 4]]
list3 = [[3, 4], [1, 2]]
print(list1 == list2) # True
print(list1 == list3) # FalseЕсли требуется поэлементная проверка с дополнительной логикой, применяют zip() и генераторы:
all(x == y for x, y in zip(list1, list2))Такой подход полезен при частичном сравнении или обработке исключений, например:
try:
all(x == y for x, y in zip(list1, list2))
except TypeError:
# Обработка несовместимых типов
passДля больших списков можно сравнить хеши:
- Применить
hash(tuple(list1)) == hash(tuple(list2)) - Подходит только для хешируемых объектов
- Неэффективен при необходимости отслеживания расхождений
Для отладки различий по индексам:
for i, (a, b) in enumerate(zip(list1, list2)):
if a != b:
print(f'Отличие в позиции {i}: {a} != {b}')Если списки разной длины, zip() обрежет до минимального размера. Для полной проверки используют:
if len(list1) != len(list2):
print("Длины списков не совпадают")
elif list1 != list2:
print("Списки различаются по содержимому и порядку")Резюме:
==– основной способ для строгой проверкиzip()– для анализа отличийhash()– для быстрой проверки идентичности
Сравнение списков без учёта порядка с помощью множества

Если порядок элементов в списках не имеет значения, можно использовать множества. Это особенно эффективно при работе с неупорядоченными данными, где важен только факт наличия элементов.
Для базового сравнения достаточно преобразовать оба списка в множества и использовать оператор равенства:
list1 = [3, 1, 2]
list2 = [2, 3, 1]
if set(list1) == set(list2):
print("Списки равны без учёта порядка")
Этот подход игнорирует повторяющиеся элементы. Например, [1, 2, 2] и [1, 2] будут считаться равными, что недопустимо, если важна кратность значений. В таких случаях следует использовать collections.Counter:
from collections import Counter
list1 = [1, 2, 2]
list2 = [2, 1, 2]
if Counter(list1) == Counter(list2):
print("Списки идентичны по составу и количеству элементов")
Множества также подходят для поиска различий между списками. Например, чтобы получить уникальные элементы, присутствующие только в одном из них:
diff = set(list1) ^ set(list2)Для оптимальной производительности при больших объёмах данных предпочтительнее использовать множества, так как операции сравнения и поиска в них выполняются быстрее, чем в списках.
Нахождение общих элементов между двумя списками
Для определения пересечения двух списков в Python существует несколько эффективных подходов. Выбор зависит от требований к скорости и сохранению порядка элементов.
- Множества: Самый быстрый способ – использование встроенного типа
set. Пример:list1 = [1, 2, 3, 4] list2 = [3, 4, 5, 6] common = list(set(list1) & set(list2))Операция & находит пересечение. Итог не сохраняет порядок и исключает дубликаты.
- Списковое включение: Для сохранения порядка и учета повторений:
common = [x for x in list1 if x in list2]Подходит для небольших списков. При больших объёмах данных – медленно из-за линейного поиска по второму списку.
- Использование Counter: Если важно сохранить количество повторов:
from collections import Counter c1 = Counter([1, 2, 2, 3]) c2 = Counter([2, 2, 3, 4]) common = list((c1 & c2).elements())Результат:
[2, 2, 3]. Подходит для мультимножеств. - Фильтрация через множество: Ускоренный вариант спискового включения:
set2 = set(list2) common = [x for x in list1 if x in set2]Сохраняет порядок из
list1, работает быстрее, еслиlist2большой.
Для массивов с числовыми значениями рекомендуется использовать библиотеки NumPy:
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([3, 4, 5, 6])
common = np.intersect1d(a, b)Функция intersect1d возвращает отсортированный массив уникальных общих элементов.
Определение различий между двумя списками

Для точного выявления различий между двумя списками в Python можно использовать множество (set) и генераторы списков. Множества позволяют быстро определить уникальные элементы, но теряют порядок и не учитывают повторения. Для учета порядка и количества вхождений применяют модуль collections.
Пример с использованием множеств:
list1 = [1, 2, 3, 4]
list2 = [3, 4, 5, 6]
diff1 = set(list1) - set(list2) # элементы, присутствующие только в list1
diff2 = set(list2) - set(list1) # элементы, присутствующие только в list2
Если нужно учитывать количество повторений, используйте Counter:
from collections import Counter
list1 = [1, 2, 2, 3]
list2 = [2, 3, 3, 4]
c1 = Counter(list1)
c2 = Counter(list2)
only_in_list1 = list((c1 - c2).elements()) # [1, 2]
only_in_list2 = list((c2 - c1).elements()) # [3, 4]
Для получения полной симметрической разности с учетом повторений:
sym_diff = list((c1 - c2).elements()) + list((c2 - c1).elements()) # [1, 2, 3, 4]
Если важен порядок элементов, используйте генераторы списков без преобразования в множества:
list1 = [1, 2, 3, 4]
list2 = [3, 4, 5, 6]
only_in_list1 = [x for x in list1 if x not in list2]
only_in_list2 = [x for x in list2 if x not in list1]
Для списков с большим объемом данных оптимальнее использовать множества из-за линейной сложности операций. При сравнении вложенных структур (списков списков, словарей и т.д.) необходимо использовать рекурсивные алгоритмы сравнения или сторонние библиотеки, например deepdiff.
Сравнение списков с вложенными структурами
Сравнение списков, содержащих вложенные элементы – словари, другие списки, кортежи – требует рекурсивного подхода. Простое сравнение с помощью оператора == не выявит различия в структуре при различном порядке ключей в словарях или эквивалентных, но разных типах контейнеров (например, список и кортеж).
Для точного сравнения необходимо использовать модуль deepdiff, который позволяет учитывать вложенность и предоставляет информацию о различиях на любом уровне:
from deepdiff import DeepDiff
a = [{'id': 1, 'data': [1, 2]}, {'id': 2}]
b = [{'id': 1, 'data': [1, 3]}, {'id': 2}]
diff = DeepDiff(a, b, ignore_order=True)
print(diff)Параметр ignore_order помогает игнорировать порядок элементов, если он не важен. Это особенно полезно при сравнении списков словарей, где порядок не имеет значения.
Если использование сторонних библиотек невозможно, пишется рекурсивная функция, сравнивающая типы и содержимое элементов:
def deep_equal(x, y):
if type(x) != type(y):
return False
if isinstance(x, dict):
if x.keys() != y.keys():
return False
return all(deep_equal(x[k], y[k]) for k in x)
if isinstance(x, list):
if len(x) != len(y):
return False
return all(deep_equal(i, j) for i, j in zip(x, y))
return x == yТакой подход работает для произвольной вложенности и сохраняет контроль над логикой сравнения. При этом следует помнить, что zip сравнивает элементы по позиции, и если порядок критичен, это необходимо учитывать.
Для списков, содержащих несортированные словари, важно либо предварительно отсортировать их по ключевому признаку, либо реализовать сравнение с учетом содержимого, а не позиции:
def compare_dict_lists(a, b, key):
a_sorted = sorted(a, key=lambda d: d[key])
b_sorted = sorted(b, key=lambda d: d[key])
return deep_equal(a_sorted, b_sorted)Это гарантирует, что даже при разном порядке элементов, списки будут считаться эквивалентными при совпадении значений по ключу.
Использование библиотеки collections для подсчёта совпадений
Для подсчёта совпадений между двумя списками в Python удобно использовать класс Counter из библиотеки collections. Этот класс позволяет легко подсчитывать количество элементов в коллекциях и эффективно сравнивать их. Основная его задача – подсчёт повторений каждого элемента в списке, что помогает выявить пересечения и различия между списками.
Пример использования Counter для подсчёта совпадений двух списков:
from collections import Counter
list1 = [1, 2, 3, 4, 5, 1]
list2 = [1, 2, 1, 3, 3, 5]
counter1 = Counter(list1)
counter2 = Counter(list2)
common_elements = counter1 & counter2 # Пересечение
print(common_elements)В данном примере оператор & используется для нахождения пересечений между двумя списками. Counter автоматически учитывает количество повторений элементов в каждом списке. Результатом будет новый Counter, который показывает минимальное количество совпадающих элементов.
Если нужно подсчитать не только пересечение, но и различия, то можно использовать операторы - и + для получения элементов, которые присутствуют только в одном списке или только в другом:
difference1 = counter1 - counter2 # Элементы, которые есть только в list1
difference2 = counter2 - counter1 # Элементы, которые есть только в list2
print(difference1)
print(difference2)Оператор - возвращает элементы, которые есть в одном списке, но отсутствуют в другом. Это полезно, когда необходимо выделить уникальные элементы каждого списка.
Для получения всех элементов, которые присутствуют хотя бы в одном из списков, можно использовать оператор +. Этот оператор объединяет элементы обоих списков, сохраняя их количество:
union = counter1 + counter2 # Все элементы из обоих списков
print(union)Использование Counter в таких операциях ускоряет процесс подсчёта и делает код более читаемым. Он значительно проще и эффективнее, чем написание ручных циклов для сравнения элементов. Однако стоит помнить, что Counter чувствителен к порядку элементов в списке, и это может повлиять на результаты, если порядок элементов имеет значение.
Сравнение списков разных типов данных

При сравнении списков в Python, состоящих из элементов разных типов данных, важно учитывать особенности их поведения при сравнении. В отличие от списков, содержащих элементы одного типа, такие структуры могут привести к непредсказуемым результатам или ошибкам, если не использовать корректные подходы.
Когда один из списков включает в себя, например, целые числа, а другой – строки, прямое сравнение через операторы равенства (`==`) или неравенства (`!=`) может привести к неверным результатам. Python не проводит автоматического преобразования типов данных, что важно учитывать. Например, сравнение списка `[1, 2]` и списка `[«1», «2»]` с помощью оператора `==` всегда вернёт `False`, так как строковые и числовые значения не совпадают по типу, несмотря на их схожесть по содержанию.
Для эффективного сравнения списков разных типов данных можно применить несколько подходов. Один из них – приведение всех элементов списков к общему типу данных перед сравнением. Например, можно преобразовать все элементы в строки или числа с помощью функций `str()` или `int()`. Однако стоит помнить, что это приведет к потерям точности в некоторых случаях, например, при сравнении чисел с плавающей запятой и строк, содержащих нечисловые символы.
Еще одним важным моментом является порядок элементов в списках. Даже если оба списка содержат одинаковые элементы, но в разном порядке, сравнение с помощью оператора `==` вернет `False`. Это стоит учитывать, когда речь идет о сравнениях, где порядок имеет значение.
Если необходимо провести более детальное сравнение, например, проверить, есть ли общие элементы в списках разных типов, то можно использовать множество, что избавляет от необходимости учитывать порядок элементов. Для этого конвертируйте списки в множества с помощью функции `set()`, а затем используйте операции пересечения или объединения.
В случае необходимости сравнения вложенных списков, например, списка, содержащего другие списки с разными типами данных, следует использовать рекурсивные методы, которые помогут корректно пройти по каждому уровню вложенности и сравнить элементы. Такие методы позволяют избежать ошибок, связанных с вложенными структурами данных.
Сравнение списков, включающих разные типы данных, требует внимательности и осторожности. Важно точно понимать, какие типы данных присутствуют в списке, чтобы избежать логических ошибок при сравнении и корректно обработать все возможные сценарии.
Поэлементное сравнение двух списков в Python позволяет найти различия на уровне каждого элемента. Для этого можно использовать несколько подходов, включая использование встроенных функций и циклов. Рассмотрим два популярных способа реализации такого сравнения.
Первый способ – это использование цикла for для поэлементного перебора. Пример кода:
list1 = [1, 2, 3, 4, 5]
list2 = [1, 3, 3, 5, 6]
differences = []
for i in range(len(list1)):
if list1[i] != list2[i]:
differences.append((i, list1[i], list2[i]))
print(differences)
В этом примере сравниваются элементы двух списков, и если элемент в одном списке отличается от элемента в другом, индекс и значения добавляются в список differences.
Второй способ – использование встроенной функции zip для параллельного перебора элементов двух списков. Это позволяет избежать необходимости вручную отслеживать индексы:
list1 = [1, 2, 3, 4, 5]
list2 = [1, 3, 3, 5, 6]
differences = [(i, a, b) for i, (a, b) in enumerate(zip(list1, list2)) if a != b]
print(differences)
Функция zip объединяет два списка в кортежи, а enumerate добавляет индекс. Результат – это список кортежей, где каждый элемент содержит индекс и значения из обоих списков, которые отличаются.
Для более сложных сценариев, когда необходимо сравнивать списки с разной длиной, можно использовать функцию itertools.zip_longest для дополнения недостающих элементов:
from itertools import zip_longest
list1 = [1, 2, 3, 4, 5]
list2 = [1, 3, 3]
differences = [(i, a, b) for i, (a, b) in enumerate(zip_longest(list1, list2)) if a != b]
print(differences)
Это решение позволяет эффективно сравнивать списки с разными размерами, при этом элементы из более короткого списка будут дополнены значением None.
При поэлементном сравнении важно помнить о возможности наличия различных типов данных в списках. Для таких случаев можно использовать дополнительные проверки типов для более точного сравнения, например:
differences = [(i, type(a), type(b), a, b) for i, (a, b) in enumerate(zip(list1, list2)) if a != b]
print(differences)
Этот подход позволит вывести не только значения, но и типы данных, что может быть полезно при отладке и анализе данных.