В Python сравнение символов выполняется с использованием стандартных операторов сравнения, таких как ==, !=, <, >, и других. Основное отличие символов от строк в Python заключается в том, что символы считаются элементами строк, а не отдельными типами данных. Это означает, что символы могут быть сравнены напрямую с использованием тех же операторов, что и строки, но их работа ограничена одним символом.
При сравнении символов Python использует их числовое представление в кодировке Unicode. Каждый символ имеет уникальный код, который может быть получен с помощью функции ord(). Например, для символа ‘a’ результат вызова ord(‘a’) будет равен 97. Это представление позволяет выполнять лексикографическое сравнение символов, так как Python проверяет их числовые значения.
Важно понимать, что при сравнении символов Python не делает различий между их представлениями в разных регистрах. Для того чтобы корректно сравнить символы независимо от регистра, можно воспользоваться функцией lower() или upper(), которые приведут символы к единому регистру перед сравнением. Например, выражение ‘a’.lower() == ‘A’.lower() вернёт True, что свидетельствует о равенстве символов с учётом регистра.
Сравнение символов с помощью оператора ==

Оператор == в Python используется для сравнения значений двух символов (тип str). В случае с символами, это сравнение проверяет, идентичны ли два символа по своей сути. Оператор вернёт True, если символы одинаковы, и False в противном случае.
Python сравнивает символы по их Unicode-значению. Например, символы ‘a’ и ‘A’ не равны, поскольку их Unicode-коды различны. Использование == работает по принципу строгого равенства, то есть даже если символы визуально похожи (например, латинская буква и кириллическая), результат сравнения будет False, если коды в таблице Unicode не совпадают.
Пример:
char1 = 'a'
char2 = 'a'
char3 = 'A'
print(char1 == char2) # True
print(char1 == char3) # False
Сравнение может быть полезным при работе с текстами, где важно точно учитывать символы, их регистр и кодировку. Важно помнить, что сравниваются именно символы, а не их визуальное представление, что особенно актуально в случаях с разными шрифтами или символами с похожими графическими формами.
Использование функции ord() для сравнения символов по их кодам

Функция ord() возвращает целочисленный код символа в соответствии с его представлением в Unicode. Это позволяет использовать числовые значения для прямого сравнения символов, основываясь на их позициях в таблице символов.
Для сравнения символов по их кодам достаточно передать символ в функцию ord(). Результатом будет число, которое можно использовать в логических выражениях. Например, символ 'a' имеет код 97, а символ 'b' – 98. Таким образом, сравнив коды этих символов, можно определить их порядок:
if ord('a') < ord('b'):
print("Символ 'a' меньше символа 'b' по коду")
Функция ord() полезна для упорядочивания строк, проверки принадлежности символа к определённому диапазону или для выполнения других задач, где необходимо учитывать именно числовое представление символов. Например, можно проверить, является ли символ буквой латинского алфавита:
def is_latin_letter(char):
return ord('a') <= ord(char) <= ord('z') or ord('A') <= ord(char) <= ord('Z')
Для обратного преобразования числа в символ используется функция chr(), которая принимает числовое значение и возвращает соответствующий символ. Например, chr(97) вернёт символ 'a'.
При сравнении символов через ord() важно помнить, что символы с разными кодами имеют различное значение в контексте сортировки и фильтрации данных.
Как сравнивать символы с учётом регистра
В Python операторы сравнения для символов (строк) чувствительны к регистру. То есть, символы в верхнем и нижнем регистре считаются разными. Рассмотрим основные способы и рекомендации для сравнения символов с учётом регистра.
- Оператор == используется для прямого сравнения символов с учётом их регистра. Например, символ 'a' не равен символу 'A'.
- Оператор != проверяет, что два символа различны, учитывая регистр. Для символов 'a' и 'A' результатом будет True.
Пример:
a = 'a' b = 'A' print(a == b) # False print(a != b) # True
Рекомендуется использовать операторы сравнения, если важно учитывать регистр символов. В случае, когда требуется сравнение без учёта регистра, следует использовать методы, преобразующие символы в один регистр.
- Метод lower() приводит символ к нижнему регистру. Пример: 'A'.lower() вернёт 'a'.
- Метод upper() приводит символ к верхнему регистру. Пример: 'a'.upper() вернёт 'A'.
Пример без учёта регистра:
a = 'a' b = 'A' print(a.lower() == b.lower()) # True
Для работы с большими строками, метод casefold() может быть полезен, так как он более универсален и корректно обрабатывает различные языки. Этот метод подходит для сложных случаев, например, при сравнении символов с акцентами или диакритическими знаками.
- Метод casefold() учитывает различные языковые особенности. Например, в немецком языке 'ß' преобразуется в 'ss'.
Пример использования casefold:
a = 'ß' b = 'ss' print(a.casefold() == b.casefold()) # True
Таким образом, для простого сравнения символов с учётом регистра используйте операторы сравнения. В случае необходимости игнорировать регистр или учитывать особенности локалей, применяйте методы lower(), upper() или casefold().
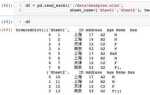
Сравнение символов в строках и списках
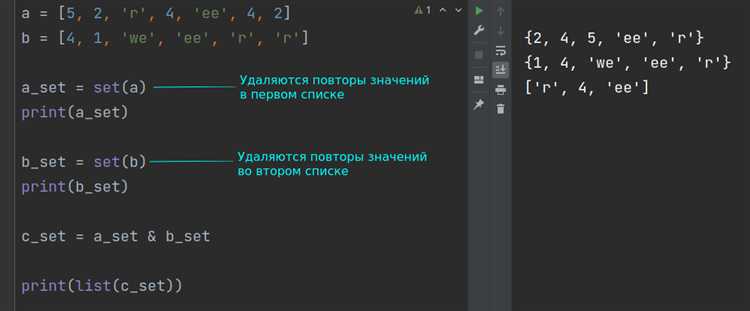
В Python символы строк и элементы списков можно сравнивать как по отдельности, так и в рамках коллекции. Строки и списки имеют несколько различий в поведении при сравнении элементов.
Для строк, сравнение символов происходит по их ASCII или Unicode значениям. Например, символ 'a' будет меньше 'b', потому что его ASCII значение (97) меньше, чем у 'b' (98). Важно, что строки в Python неизменяемы, и при сравнении символов используется индексирование.
Пример сравнения символов в строках:
string1 = "apple" string2 = "banana" result = string1[0] < string2[0] # 'a' < 'b', result будет True
Когда элементы сравниваются в списках, важным фактором является то, что списки могут содержать любые объекты, включая строки. Каждый элемент в списке сравнивается по тому же принципу, что и для строк, с использованием их значений.
Пример сравнения элементов в списках:
list1 = ['a', 'b', 'c'] list2 = ['b', 'a', 'c'] result = list1[0] < list2[0] # 'a' < 'b', result будет True
Основное отличие: строки всегда сохраняют порядок символов и индексируют их, в то время как списки могут содержать объекты любого типа, что позволяет производить сравнение как примитивных значений, так и более сложных структур. Сравнение элементов списка не зависит от позиции их нахождения в памяти.
Для строк можно использовать операторы сравнения, такие как '<', '>', '==', '!=', которые напрямую оперируют с символами, в то время как для списков также применяются те же операторы, но они сначала сравнивают элементы по порядку (индексу) в структуре.
Важно помнить, что сравнение строк и списков производится по значению элементов, а не по их типу. То есть, строка "123" будет меньше строки "213", так как символы '1' меньше '2', а сравнение продолжается по порядку.
Проверка на вхождение символа в строку с помощью оператора in
В Python оператор in позволяет проверить, содержится ли символ или подстрока в строке. Это один из самых быстрых и удобных способов выполнения такой проверки. Оператор возвращает True, если символ найден, и False, если нет.
Пример:
symbol = 'a'
string = 'python'
result = symbol in string # результат True, так как 'a' присутствует в 'python'Оператор in также работает с любыми итерируемыми объектами, такими как списки, кортежи и множества, но для строк он особенно полезен, так как позволяет быстро и лаконично проверить наличие одного символа в другом.
Примечание: Оператор in проверяет точное вхождение символа. Это значит, что если в строке есть символ в верхнем регистре, поиск с символом в нижнем регистре не даст положительный результат.
symbol = 'P'
string = 'python'
result = symbol in string # результат False, 'P' нет в 'python'Если важно учитывать регистр, можно использовать метод lower() или upper() для приведения строки и символа к единому регистру.
symbol = 'P'
string = 'python'
result = symbol.lower() in string.lower() # результат True, оба символа приведены к нижнему региструИспользование оператора in эффективно для проверки вхождения символов в строки с небольшой длиной. Для более сложных проверок, например, когда требуется найти все вхождения символа или индекс его первого появления, лучше использовать методы find() или index().
Использование функций str.casefold() и str.lower() для нормализации регистров
Для сравнения строк в Python важно учитывать возможные различия в регистре символов. Функции str.lower() и str.casefold() помогают нормализовать строки, но их использование зависит от задач.
Функция str.lower() преобразует все символы строки в строчные. Этот метод подходит для большинства ситуаций, когда необходимо просто игнорировать различия в регистре, например, при сравнении строк в текстовых поисковых системах или при анализе данных.
Однако, если требуется более широкая нормализация, учитывающая особенности локализации и языкознания, следует использовать str.casefold(). Этот метод более агрессивно трансформирует символы, учитывая специфические различия в регистрах, такие как буквы с диакритиками в разных языках. Например, casefold() корректно обрабатывает символы типа ß (в немецком языке) и приводит их к эквивалентной форме ss.
Основное различие между этими функциями заключается в том, что casefold() предназначена для сравнения строк в контексте культурных различий, а lower() работает исключительно с базовым регистром без учета языковых особенностей.
Рекомендуется использовать str.casefold(), если необходимо сравнивать строки с учетом разных языков и символов, а str.lower() подходит для базового сравнения строк в одном языке без учета диакритик.
Сравнение символов с учётом Unicode

- Сравнение основано на порядковых номерах:
'а' < 'б', потому чтоord('а') = 1072, аord('б') = 1073. - Влияние регистра:
'А' < 'а', так какord('А') = 1040,ord('а') = 1072. - Визуально одинаковые, но разные символы:
'е' ≠ 'ё', потому чтоord('е') = 1077, аord('ё') = 1105.
Символы могут выглядеть одинаково, но иметь разную кодировку. Пример: латинская 'e' (U+0065) и кириллическая 'е' (U+0435).
- Чтобы избежать ошибок, используйте
unicodedata.name()для анализа символов. - Функция
unicodedata.normalize()помогает сравнивать символы с диакритическими знаками:normalize('NFC', 'é')иnormalize('NFC', 'e\u0301')дадут идентичные строки.
Для корректного сравнения символов из разных языков и форм записи применяйте нормализацию перед сравнением и всегда учитывайте кодовые точки, а не внешний вид символов.