Сравнение строк в Python – это не просто проверка на равенство. Важно учитывать особенности языка, такие как регистрация символов, кодировки и поведение встроенных методов. Когда строки имеют разные типы, например, одну строку в нижнем регистре и другую в верхнем, стандартные операторы могут не дать ожидаемых результатов. Изучение всех нюансов этого процесса позволит избежать ошибок и повысить производительность вашего кода.
Первый важный момент – это выбор оператора для сравнения. Оператор == проверяет, равны ли две строки по символам и их порядку, что является наиболее очевидным вариантом. Однако если нужно игнорировать регистр символов, можно воспользоваться методом lower() или upper() для приведения строк к одному регистру перед сравнением. В этом случае сравнение будет нечувствительно к регистру, что может быть полезно при обработке пользовательского ввода или работы с текстами, где важно не учитывать регистр букв.
Для более сложных сравнений, например, когда нужно учитывать только первые несколько символов строки или проводить лексикографическое сравнение, стоит обратить внимание на методы startswith(), endswith() и cmp(). Эти методы позволяют задать более точные условия для проверки строк, что полезно при работе с текстами, где порядок символов имеет значение.
Важным аспектом является также различие между строками с различными кодировками. Python 3 использует строковые объекты в формате Unicode по умолчанию, что может привести к неожиданным результатам при сравнении строк, содержащих специальные символы или различающиеся кодировки. Если строки представляют собой байтовые строки, необходимо использовать метод decode() для преобразования их в строки Unicode перед сравнением.
Правильный выбор метода и понимание различий между строками позволяют избежать множества подводных камней при работе с текстовыми данными.
Сравнение строк с помощью оператора «==»

Важно учитывать, что при сравнении строк учитываются не только символы, но и их регистр. Строки, отличающиеся хотя бы одним символом или регистром, не будут равны. Например, строки «Python» и «python» не равны, так как первый символ в одной строке – заглавная буква, а в другой – строчная.
Пример использования оператора «==»:
str1 = "Hello"
str2 = "Hello"
str3 = "hello"
print(str1 == str2) # True
print(str1 == str3) # FalseТакже стоит помнить, что строки в Python неизменяемы (immutable), поэтому при сравнении объектов строк Python проверяет их содержимое, а не ссылку на объект в памяти.
Для правильного использования оператора «==» рекомендуется всегда быть внимательным к регистру символов и пробелам в строках. Например, строки с лишними пробелами в начале или в конце будут считаться различными, даже если они выглядят одинаково визуально.
Если необходимо сравнивать строки без учета регистра, можно использовать методы str.lower() или str.upper(), чтобы привести обе строки к одному регистру перед сравнением.
str1 = "Hello"
str2 = "hello"
print(str1.lower() == str2.lower()) # TrueТаким образом, оператор «==» – простой и эффективный инструмент для сравнения строк, но требует внимания к деталям, таким как регистр символов и пробелы. Важно учитывать эти нюансы при написании качественного кода.
Использование метода compare() для сравнения строк
Метод compare() принимает два аргумента – строки, которые необходимо сравнить, и возвращает отрицательное число, если первая строка «меньше» второй, положительное число, если первая строка «больше» второй, или ноль, если строки равны. При этом сравнение проводится с учётом локальных настроек, заданных через модуль locale.
Пример использования:
import locale
locale.setlocale(locale.LC_COLLATE, 'ru_RU.UTF-8') # Устанавливаем русскую локаль
result = locale.strcoll('яблоко', 'апельсин') # Сравниваем строки
print(result) # Выведет отрицательное число, так как "яблоко" идет после "апельсин"Стоит отметить, что метод compare() не является стандартным методом для строк в Python. Он используется через библиотеку locale и предназначен исключительно для учёта региональных различий в сортировке строк. В обычных случаях для сравнения строк предпочтительнее использовать стандартные операторы сравнения, такие как ==, >, <.
Основное преимущество использования locale.compare() заключается в точности учёта особенностей языка. Например, в некоторых языках символы с акцентами или диакритическими знаками могут иметь разные позиции в алфавите, что важно при сравнении строк в реальных приложениях, например, при сортировке списков на различных языках.
Сравнение строк с учетом регистра в Python
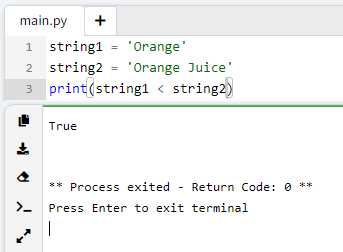
Для обычного сравнения строк в Python можно использовать операторы сравнения: `==`, `!=`, `<`, `>`, `<=`, `>=`. Все эти операторы сравнивают строки, принимая во внимание регистр. Например, строки «abc» и «ABC» будут различными при сравнении с использованием оператора `==`.
Пример:
str1 = "abc" str2 = "ABC" result = str1 == str2 # False
Как видно, результатом сравнения будет False, так как регистр букв в строках различен.
Для явного игнорирования регистра при сравнении строк можно использовать метод `.lower()` или `.upper()`, который приводит все символы строки к одному регистру перед сравнением. Это позволяет выполнить сравнении независимо от регистра.
Пример:
str1 = "abc" str2 = "ABC" result = str1.lower() == str2.lower() # True
Таким образом, оба метода делают строки одинаковыми по регистру, и операторы сравнения могут использоваться корректно.
Кроме того, можно использовать метод `.casefold()`, который работает аналогично `.lower()`, но имеет более широкую область применения, включая символы, которые могут быть написаны в разных регистрах в разных языках. Этот метод рекомендуется использовать, когда необходимо сравнить строки с учетом локальных особенностей.
Пример:
str1 = "straße" str2 = "STRASSE" result = str1.casefold() == str2.casefold() # True
Рекомендуется избегать случайных сравнений строк с учетом регистра, если нет явной необходимости, так как это может привести к нежелательным ошибкам в коде, особенно при обработке пользовательского ввода. Всегда стоит четко понимать, нужно ли учитывать регистр в конкретном контексте.
Как игнорировать пробелы при сравнении строк
При сравнении строк в Python пробелы могут быть значимыми. Иногда возникает необходимость игнорировать пробелы для более точного сравнения. Существует несколько способов добиться этого.
Один из простых и эффективных методов – это использование метода replace(). С помощью этого метода можно удалить все пробелы из строк перед их сравнением:
str1 = "Привет мир"
str2 = "Привет мир"
if str1.replace(" ", "") == str2.replace(" ", ""):
print("Строки равны без учёта пробелов")
Этот способ подходит, если необходимо игнорировать пробелы в любом месте строки. Однако важно помнить, что метод replace() заменяет только пробелы, и если в строках есть другие символы (например, табуляции или новые строки), они не будут удалены.
Для более универсального подхода можно использовать регулярные выражения. В Python для этого удобно применить модуль re, который позволяет удалить все пробельные символы, включая пробелы, табуляции и символы новой строки:
import re
str1 = "Привет мир"
str2 = "Привет мир"
if re.sub(r'\s+', '', str1) == re.sub(r'\s+', '', str2):
print("Строки равны без учёта всех пробельных символов")
В данном случае регулярное выражение \s+ находит все пробельные символы и заменяет их на пустую строку, независимо от их типа или количества.
Если необходимо игнорировать пробелы только в начале и конце строк, можно воспользоваться методом strip(), который удаляет пробельные символы только в этих позициях:
str1 = " Привет мир "
str2 = "Привет мир"
if str1.strip() == str2.strip():
print("Строки равны без учёта пробелов по краям")
Этот метод не затрагивает пробелы внутри строки, что может быть полезно в случае, когда важен только формат на концах строк.
При сравнении строк с учётом игнорирования пробелов важно учитывать контекст задачи. Если нужно сравнивать строки в контексте текста или документа, регулярные выражения могут быть наиболее подходящим решением. В других случаях методы replace() и strip() могут быть проще и быстрее.
Преобразование строк в нижний/верхний регистр перед сравнением

При сравнении строк в Python важно учитывать регистр символов. Чтобы избежать ошибок, связанных с различиями в верхнем и нижнем регистре, можно заранее преобразовать строки в одинаковый регистр. Это упрощает проверку на равенство или сортировку, особенно в ситуациях, когда важна только семантика текста, а не его визуальное отображение.
Методы преобразования: для работы с регистром Python предоставляет два стандартных метода: lower() и upper(). Оба метода возвращают новые строки, преобразованные в нижний или верхний регистр соответственно.
Пример использования lower():
str1 = "Python"
str2 = "python"
if str1.lower() == str2.lower():
print("Строки равны")Пример использования upper():
str1 = "Python"
str2 = "PYTHON"
if str1.upper() == str2.upper():
print("Строки равны")Когда использовать преобразование: Если строки могут быть написаны в разных регистрах (например, имя пользователя, ключи в словарях, значения в базе данных), рекомендуется всегда приводить их к одному регистру перед сравнением. Это предотвращает ошибки при сравнении строк с различным визуальным отображением.
Важное замечание: преобразование строк в нижний или верхний регистр подходит в большинстве случаев, однако следует помнить, что для некоторых языков (например, турецкого) преобразование в регистр может не быть однозначным из-за особенностей локализации. Для таких случаев стоит использовать более продвинутые методы, например, casefold(), который учитывает локализацию.
Пример использования casefold():
str1 = "straße"
str2 = "STRASSE"
if str1.casefold() == str2.casefold():
print("Строки равны")Таким образом, для универсальности и избежания ошибок, лучше использовать метод casefold(), особенно при работе с многими языками и системами, где регистр может влиять на сравнение.
Что делать при сравнении строк с разными кодировками
При сравнении строк с разными кодировками важно учитывать, что Python интерпретирует строки в зависимости от их типа: байтовые строки (тип bytes) и строковые объекты (тип str, кодировка Unicode). Несоответствие кодировок может привести к ошибкам или неожиданным результатам. Чтобы корректно сравнивать такие строки, следует применить несколько шагов.
1. Преобразование строк в единую кодировку. Если одна из строк представлена в байтовом виде, а другая – в виде строки Unicode, преобразуйте байтовую строку в строку Unicode, используя соответствующую кодировку. Для этого можно использовать метод decode() для байтов и encode() для строк. Например, для строки в кодировке UTF-8: byte_str.decode('utf-8').
2. Проверка кодировки. Если строки, которые нужно сравнить, имеют байтовое представление, важно точно знать, в какой кодировке они сохранены. Часто ошибки происходят из-за неверного определения кодировки, что приводит к искажению символов. Используйте библиотеку chardet для автоматического определения кодировки, но всегда старайтесь заранее знать, в какой кодировке строка была получена.
3. Нормализация строк. В случае работы с Unicode строками могут возникать проблемы с символами, представляющими один и тот же визуальный символ, но имеющими разную внутреннюю форму представления (например, символы с акцентами или диакритическими знаками). Для устранения таких несоответствий используйте модуль unicodedata для нормализации строк в одну форму: unicodedata.normalize('NFC', str).
4. Учет различий в кодировках при сравнении. Важно помнить, что сравнение строк с разными кодировками без приведения их к одному виду может привести к ошибочным результатам. Например, строка, закодированная в UTF-8, будет сравниваться с байтовой строкой по байтам, а не по символам, что зачастую приведет к неравенству. Всегда приводите строки к одинаковой кодировке перед сравнением.
5. Использование функции str и bytes для явного преобразования. Если у вас есть необходимость сравнить строку с байтовым представлением, явное преобразование в один из типов может помочь избежать ошибок: str(byte_str, 'utf-8') или bytes(str_obj, 'utf-8'). Такие преобразования важны, чтобы избежать путаницы между строками и байтами.
Решая задачу сравнения строк с разными кодировками, всегда придерживайтесь единой кодировки для всех строк и используйте проверенные методы преобразования и нормализации для корректного результата.
Работа с частичными совпадениями строк с помощью регулярных выражений

Для поиска фрагментов строк в Python используется модуль re. Он позволяет задать гибкие шаблоны и находить частичные совпадения с высокой точностью.
Функции, применяемые для частичного сравнения:
re.search(pattern, string)– находит первое вхождение шаблона в строке.re.findall(pattern, string)– возвращает все совпадения в виде списка.re.finditer(pattern, string)– возвращает итератор с объектами совпадений.
Примеры полезных шаблонов:
r"\bword\b"– точное совпадение слова, ограниченного пробелами или знаками препинания.r"\d{3}-\d{2}-\d{4}"– поиск по формату (например, номера документов).r"(?i)python"– нечувствительный к регистру поиск слова «python».
Рекомендации по использованию:
- Компилируйте шаблоны с помощью
re.compile()для повторного использования и повышения производительности. - Избегайте избыточного применения
.*– оно снижает точность и скорость. - Используйте группы захвата
(), чтобы извлекать части совпавших строк. - Проверяйте результат с помощью
if match:, а не сравнивайте сNoneнапрямую. - Для частичного совпадения подстрок в середине строки используйте шаблон без ограничений по началу и концу:
r"подстрока".
Регулярные выражения незаменимы, если требуется находить совпадения по шаблону, а не по точному значению. Они эффективны в задачах фильтрации, валидации и извлечения данных из текстов любой сложности.
Как правильно сравнивать строки с учетом локализации
Стандартное сравнение строк в Python с помощью операторов ==, <, > и функций вроде sorted() работает по байтовому представлению символов в Unicode и не учитывает культурные особенности алфавита. Это может приводить к некорректным результатам при сравнении строк на языках с особыми правилами сортировки, например, на немецком, французском или русском.
Для корректного сравнения строк с учетом локали следует использовать модуль locale. Пример:
import locale
locale.setlocale(locale.LC_COLLATE, 'ru_RU.UTF-8')
sorted_list = sorted(['ёж', 'яблоко', 'ёлка'], key=locale.strxfrm)
Функция locale.strxfrm преобразует строки так, чтобы их можно было корректно сравнивать с учетом установленных языковых правил.
- Перед использованием обязательно вызывайте
locale.setlocale(). Без этого по умолчанию будет использоваться локаль ‘C’, не поддерживающая культурные особенности сортировки. - Локаль зависит от ОС. Убедитесь, что нужная локаль установлена в системе. В Linux список доступных локалей можно получить командой
locale -a. - Для временной установки локали можно использовать
locale.setlocale(locale.LC_COLLATE, ''), чтобы применить настройки из переменных окружения (например,LANG).
Для более сложных случаев, включая поддержку разных алфавитов и нормализацию, рекомендуется использовать библиотеку PyICU:
from icu import Collator, Locale
collator = Collator.createInstance(Locale('ru_RU'))
sorted_list = sorted(['ёж', 'яблоко', 'ёлка'], key=collator.getSortKey)
PyICUобеспечивает поддержку правил сортировки, близких к поведению в операционных системах и офисных приложениях.- В отличие от
locale, работает одинаково на всех платформах при наличии ICU-библиотеки.
Вопрос-ответ:
Почему при сравнении строк ‘привет’ и ‘Привет’ результат — False?
Python учитывает регистр символов при сравнении строк. Это значит, что строчные и заглавные буквы считаются разными. В строке ‘привет’ все буквы строчные, а в строке ‘Привет’ первая буква — заглавная. Поэтому сравнение `’привет’ == ‘Привет’` возвращает `False`. Если нужно сравнить строки без учёта регистра, можно привести обе к одному регистру с помощью `.lower()` или `.casefold()`: `’привет’.lower() == ‘Привет’.lower()` вернёт `True`.
Как сравнить строки в Python без учёта регистра и особенностей локали?
Для сравнения строк без учёта регистра и с более корректной обработкой символов, включая специфические буквы вроде немецкой ß, рекомендуется использовать метод `.casefold()`. Он делает строку максимально унифицированной для сравнения. Например, `s1.casefold() == s2.casefold()` работает лучше, чем `.lower()` в ситуациях, где важна точность при интернационализации.
В чём разница между операторами `==` и `is` при сравнении строк?
Оператор `==` сравнивает содержимое строк, то есть символы и их порядок. А `is` проверяет, ссылаются ли обе переменные на один и тот же объект в памяти. Например, даже если две строки выглядят одинаково, `s1 is s2` может вернуть `False`, если они созданы независимо. Поэтому для проверки идентичности строк по содержанию нужно использовать `==`, а не `is`.
Можно ли сравнивать строки с использованием регулярных выражений?
Да, для более гибкого сравнения строк, например, когда нужно проверить, соответствует ли строка определённому шаблону, можно использовать модуль `re`. Метод `re.match()` проверяет, начинается ли строка с шаблона, а `re.fullmatch()` — совпадает ли строка полностью. Например: `re.fullmatch(r’\d{3}-\d{2}-\d{4}’, ‘123-45-6789’)` вернёт объект совпадения, если строка соответствует формату, или `None`, если нет.
Как сравнить строки с учётом порядка символов в алфавите?
Для сравнения строк по алфавитному порядку можно использовать стандартные операторы `<`, `>`, `<=`, `>=`. Python сравнивает строки лексикографически — то есть по порядку символов в таблице Unicode. Например, `’abc’ < 'abd'` вернёт `True`, потому что `'c'` идёт раньше `'d'`. Это поведение может отличаться от "человеческого" представления алфавитного порядка, особенно при работе с символами разных языков, поэтому в сложных случаях может потребоваться библиотека `locale` или `PyICU`.