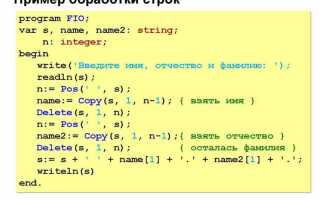
В Python есть несколько методов для работы с подстроками, и понимание того, как правильно вырезать часть строки, важно для эффективной обработки текстов. Одним из самых удобных и универсальных инструментов является срез строк. Используя срезы, можно легко получить любую часть строки, заданную индексами начала и конца.
Синтаксис среза выглядит так: строка[начало:конец]. Индекс начало указывает на позицию первого символа, с которого начнётся подстрока, а конец – на позицию, до которой будет извлечена подстрока (не включая её). Это даёт гибкость в работе с текстом, позволяя извлекать, например, первые несколько символов или последний фрагмент строки.
Для более сложных операций можно использовать отрицательные индексы. Например, строка[-5:-1] вернёт последние пять символов строки, исключая последний символ. Этот приём полезен, когда необходимо работать с концом строки, не зная её точной длины.
Интересной особенностью является использование шага в срезах: строка[начало:конец:шаг]. Шаг позволяет выбирать элементы с определённым интервалом, что может быть полезно для извлечения, например, всех чётных или нечётных символов из строки. Этот метод даёт дополнительные возможности для манипуляций с текстовыми данными.
Использование срезов для извлечения подстроки
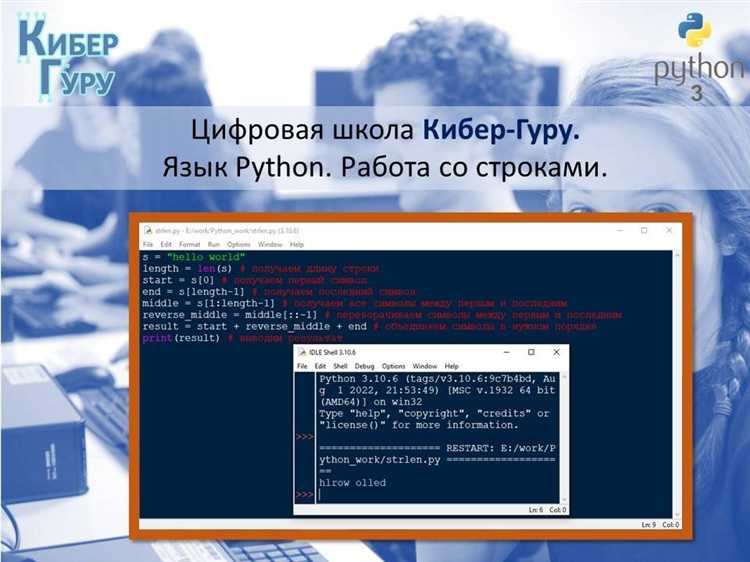
Синтаксис среза следующий:
строка[начало:конец:шаг]
- начало – индекс первого символа, с которого начинается извлечение (включительно). Если не указано, по умолчанию начинается с нулевого индекса.
- конец – индекс, на котором срез заканчивается (не включая этот индекс). Если не указано, срез продолжается до конца строки.
- шаг – интервал между индексами. По умолчанию равен 1, но можно указать большее значение для выборки через определённые промежутки.
Пример извлечения подстроки:
text = "Привет, мир!" substring = text[7:10]
В этом примере будет извлечена подстрока, начиная с индекса 7 и заканчивая на индексе 10 (не включая его), т.е. «ми».
Если нужно извлечь подстроку с конца строки, можно использовать отрицательные индексы:
substring = text[-4:-1]
Это извлечёт последние четыре символа строки, исключив последний символ, результат – «ми».
- Только начало:
substring = text[:5]
– извлечёт первые 5 символов строки.
- Только конец:
substring = text[7:]
– извлечёт подстроку с 7-го символа до конца.
- Шаг:
substring = text[::2]
– извлечёт каждый второй символ строки.
Также возможно комбинировать отрицательные индексы и шаги:
substring = text[-1:-6:-1]
Этот срез извлечёт последние пять символов строки в обратном порядке.
Рекомендации по использованию срезов:
- Всегда проверяйте индексы, чтобы избежать ошибок при извлечении пустых строк.
- Используйте отрицательные индексы для работы с концом строк, особенно если строка имеет динамическую длину.
- Когда нужно работать с большим объёмом данных, обратите внимание на производительность, так как срезы создают новые строки, а не изменяют оригинальные.
Метод.split() для разделения строки на части
Метод split() в Python используется для разделения строки на список подстрок. Этот метод возвращает список, содержащий фрагменты исходной строки, разделённые по указанному разделителю. Если разделитель не передан, строка разбивается по пробелам.
Пример:
text = "Привет мир"
result = text.split()
print(result)
Результат: ['Привет', 'мир']
Метод split() может принимать разделитель в качестве параметра. Например, чтобы разделить строку по запятой:
data = "яблоко,банан,груша"
result = data.split(',')
print(result)
Результат: ['яблоко', 'банан', 'груша']
Если разделитель отсутствует в строке, метод вернёт список, содержащий одну строку, являющуюся исходной:
text = "hello"
result = text.split(',')
print(result)
Результат: ['hello']
Метод split() также принимает необязательный параметр maxsplit, который ограничивает количество разделений. Например:
text = "a,b,c,d,e"
result = text.split(',', 2)
print(result)
Результат: ['a', 'b', 'c,d,e']
Метод split() полезен для обработки данных, например, при разборе CSV файлов или парсинге строк с разделителями. Если необходимо разделить строку по нескольким символам, можно использовать регулярные выражения с методом re.split().
Применение метода.find() для поиска подстроки

Метод find() используется для поиска подстроки в строке и возвращает индекс первого вхождения или -1, если подстрока не найдена. Это полезный инструмент, когда необходимо определить, существует ли подстрока в строке и узнать её позицию для дальнейших операций.
Синтаксис метода следующий:
str.find(substring, start, end)substring – это подстрока, которую ищем. Параметры start и end необязательные. Они позволяют задать диапазон для поиска, где start – индекс, с которого начинается поиск, а end – индекс, до которого будет происходить поиск. Если они не указаны, поиск будет выполнен по всей строке.
Пример использования:
text = "Hello, world!"
position = text.find("world")
print(position) # 7Метод возвращает индекс первого символа подстроки, в данном случае 7, так как слово «world» начинается с этого индекса в строке «Hello, world!».
Если подстрока не найдена, метод вернёт -1:
text = "Hello, world!"
position = text.find("Python")
print(position) # -1find() также полезен для поиска в подстроках с ограничениями. Например, можно искать только в определённом диапазоне символов строки:
text = "The quick brown fox jumps over the lazy dog"
position = text.find("fox", 10, 20)
print(position) # 16Метод find() эффективно используется для поиска без необходимости обработки исключений, так как возвращаемое значение всегда определено: либо индекс, либо -1. Однако, для поиска всех вхождений подстроки, следует использовать другие методы или циклы.
Как вырезать подстроку с помощью регулярных выражений

Для извлечения подстроки, соответствующей определённому шаблону, используйте функцию re.search() из модуля re. Она возвращает объект совпадения, из которого можно получить подстроку через метод group().
Пример: из строки "ID: 45291, статус: активен" нужно извлечь числовой идентификатор. Подходит регулярное выражение r"ID: (\d+)".
import re
text = "ID: 45291, статус: активен"
match = re.search(r"ID: (\d+)", text)
if match:
result = match.group(1) # '45291'
Чтобы вырезать все вхождения, используйте re.findall(). Например, для получения всех чисел из строки: re.findall(r"\d+", text).
Если необходимо заменить найденную подстроку, применяется re.sub(). Пример: удалить все HTML-теги – re.sub(r"<.*?>", "", html_text).
Для ограничения поиска определённой частью строки используйте re.search() с модификатором начала или конца строки: ^ и $. Пример: извлечь текст в начале строки до первого пробела – re.search(r"^\S+", text).
Регулярные выражения эффективны при извлечении подстрок со структурой. Если шаблон известен, это предпочтительный метод по сравнению с split() и slicing.
Вырезание подстроки с использованием индексов и отрицательных значений

В Python строки индексируются с нуля. Также допускается использование отрицательных индексов: -1 – последний символ, -2 – предпоследний и так далее. Это удобно при доступе к символам с конца строки.
- Срез
s[2:5]вернёт символы с индексами 2, 3 и 4. Символ с индексом 5 не включается. - Срез
s[-5:-2]вернёт символы начиная с пятого с конца до третьего с конца, не включая последний индекс. - Если указать только отрицательный старт:
s[-4:]– будет взята подстрока от четвёртого с конца до конца строки. s[:-3]– всё от начала до третьего символа с конца, не включая его.
Комбинации положительных и отрицательных индексов допустимы:
s[3:-2]– начиная с четвёртого символа до второго с конца.s[-7:5]– от седьмого с конца до шестого по счёту символа.
Если начальный индекс больше конечного, результатом будет пустая строка. Это нужно учитывать при работе с динамическими значениями индексов.
Отрицательные индексы особенно полезны при обработке строк с переменной длиной, когда требуется получить фиксированную часть от конца.
Что делать, если индекс выходит за пределы строки
При попытке получить подстроку с индексом, который выходит за пределы строки, Python выбрасывает ошибку IndexError. Чтобы избежать этой ошибки, следует соблюдать несколько рекомендаций:
1. Проверка длины строки. Прежде чем обращаться к индексу, убедитесь, что он находится в пределах от 0 до len(string) — 1. Используйте условные операторы, чтобы избежать ошибок при неправильных индексах:
if index >= 0 and index < len(string):
substring = string[index]
else:
print("Индекс выходит за пределы строки")
2. Использование срезов. Вместо обращения к отдельному символу строки, можно использовать срезы, которые безопасно работают даже с индексами, выходящими за пределы строки. Например:
substring = string[start:end]
Если индексы будут выходить за пределы строки, Python просто вернет пустую строку, не вызывая ошибку. Например, string[10:15] на строке длиной 10 вернет пустую строку, а не ошибку.
3. Обработка ошибок с помощью try-except. Если в вашем коде возможны динамичные индексы, можно использовать блок try-except для перехвата ошибки:
try:
substring = string[index]
except IndexError:
substring = ""
print("Ошибка: индекс выходит за пределы строки")
4. Использование метода get() для безопасного извлечения символа по индексу. В отличие от обычной индексации, метод get() позволяет задать значение по умолчанию, если индекс выходит за пределы строки:
substring = string.get(index, "")
Эти методы помогают избежать ошибок при работе с индексами и делают код более безопасным и предсказуемым.
Как вырезать подстроку в цикле по нескольким критериям
При необходимости вырезать подстроку по нескольким критериям можно использовать цикл для последовательного применения условий фильтрации. Например, если вам нужно извлечь части строки, удовлетворяющие нескольким условиям, это можно сделать с помощью условных операторов внутри цикла.
Рассмотрим пример: у нас есть строка, и нужно извлечь подстроки, которые начинаются с определённой буквы и заканчиваются другой. Для этого можно использовать метод startswith() и endswith() в комбинации с циклом.
text = "apple, banana, apricot, orange"
criteria_start = "a"
criteria_end = "e"
result = []
for word in text.split(", "):
if word.startswith(criteria_start) and word.endswith(criteria_end):
result.append(word)
В данном примере, цикл проходит по каждому слову, разделённому запятой, и проверяет, начинается ли оно с буквы «a» и заканчивается ли на «e». Если оба условия выполнены, слово добавляется в результат.
Если требуется учитывать более сложные критерии, можно комбинировать несколько условий. Например, извлечь подстроки, длина которых больше 5 символов, но начинаются с одной буквы и заканчиваются другой:
text = "apple, banana, apricot, orange"
criteria_start = "a"
criteria_end = "e"
min_length = 6
result = []
for word in text.split(", "):
if len(word) > min_length and word.startswith(criteria_start) and word.endswith(criteria_end):
result.append(word)
Здесь дополнительно проверяется длина строки с помощью len(), что позволяет добавлять только те подстроки, которые соответствуют всем условиям.
Этот метод подходит, когда условия вырезки зависят от нескольких факторов, и позволяет гибко подстраивать логику извлечения данных в зависимости от конкретных нужд.
Вопрос-ответ:
Как вырезать часть строки в Python?
В Python для извлечения подстроки из строки используется срез. Для этого необходимо указать начальный и конечный индекс с помощью синтаксиса: `строка[начало:конец]`. Начальный индекс включает в себя символ, а конечный — не включает. Например, если у вас есть строка `s = «Привет, мир!»`, и вы хотите получить подстроку с 3-го по 7-й символы, то напишете: `s[2:7]`, что вернёт строку «ивет».
Что будет, если указать индексы для среза, которые выходят за пределы строки?
Если индексы среза выходят за пределы строки, Python автоматически не выдаст ошибку. Например, если у вас есть строка `s = «Привет»` и вы попытаетесь выполнить срез с индексами, превышающими длину строки, как в `s[2:10]`, то результатом будет подстрока, начиная с 3-го символа и до конца строки. В данном случае результат будет «вет». Это поведение позволяет удобно работать с срезами без необходимости дополнительно проверять длину строки.
Как можно вырезать подстроку начиная с определённого индекса до конца строки?
Чтобы извлечь подстроку начиная с определённого индекса и до конца строки, достаточно указать только начальный индекс в срезе. Например, если у вас есть строка `s = «Программирование»` и вы хотите вырезать все символы с 6-го индекса до конца, напишите: `s[5:]`. Результатом будет строка «аммирование». Таким образом, второй индекс можно не указывать, и Python сам подберет нужный конец.
Можно ли извлечь подстроку с конца строки?
Да, можно. В Python можно использовать отрицательные индексы, которые начинаются с конца строки. Например, строка `s = «Привет»` имеет символы, доступные по индексам: -1 (последний символ), -2 (предпоследний) и так далее. Если вы хотите вырезать подстроку с конца строки, например, последние 3 символа, вы можете использовать срез: `s[-3:]`. В этом случае результат будет «вет». Таким образом, отрицательные индексы помогают легко работать с символами строки, начиная с её конца.