Python – язык с высокой читаемостью и простотой в использовании, но это не означает, что его код всегда выполняется эффективно. Наоборот, по сравнению с языками, как C или C++, Python может быть значительно медленнее. Оптимизация производительности кода Python требует применения ряда техник, основанных на особенностях интерпретируемого характера языка и его стандартной библиотеки.
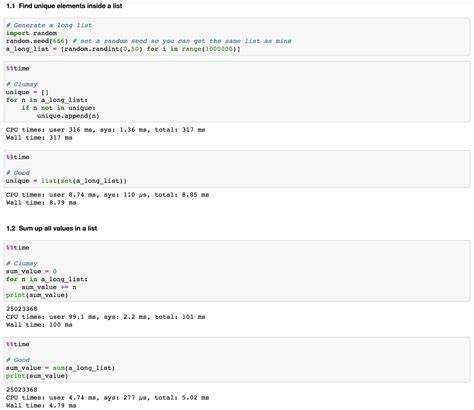
1. Использование встроенных функций и библиотек
Для улучшения скорости работы важно избегать написания собственного кода, если задача может быть решена с помощью встроенных функций или библиотек. Например, операции с коллекциями, такие как sum(), sorted() и min(), могут работать быстрее, чем их ручная реализация через циклы. Библиотека NumPy значительно ускоряет математические операции благодаря оптимизации под низкоуровневые вычисления, используя возможности C и Fortran.
2. Использование генераторов
Когда необходимо работать с большими объемами данных, генераторы часто оказываются эффективнее списков. Генераторы позволяют создавать элементы «на лету», не загружая всю коллекцию в память, что снижает потребление ресурсов. Например, выражения yield позволяют обходить большие коллекции с минимальными затратами памяти, что может существенно повысить производительность в случае обработки больших наборов данных.
3. Избежание глобальных переменных
Доступ к глобальным переменным в Python гораздо медленнее, чем к локальным. Поэтому рекомендуется ограничивать их использование, а переменные, которые не требуют глобальной области видимости, делать локальными. Например, вынесение переменных, которые часто используются в цикле, в локальную область видимости значительно уменьшит время их обработки.
4. Использование многозадачности и параллелизма
Для задач, не зависящих от GIL (Global Interpreter Lock), полезно использовать многозадачность через модули threading или multiprocessing. В то время как threading полезен для I/O-операций, multiprocessing позволяет эффективно использовать несколько ядер процессора, ускоряя вычисления, требующие интенсивных вычислительных ресурсов.
5. Профилирование и анализ производительности
Перед тем как оптимизировать код, важно провести профилирование. Используйте инструменты, такие как cProfile или timeit, чтобы измерить время выполнения различных частей программы и выявить узкие места. Без такого подхода можно улучшить производительность в неправильных местах, не решив реальные проблемы.
Оптимизация циклов и условий
Циклы и условия составляют основу алгоритмической логики, но их неправильное использование может значительно снижать производительность программы. Чтобы повысить эффективность, нужно правильно управлять количеством итераций и избежать лишних вычислений в теле цикла и условных операторов.
Оптимизация циклов
Циклы – одна из самых затратных операций. Несколько советов для их оптимизации:
- Использование генераторов вместо списков: Генераторы не создают всю последовательность в памяти, а генерируют элементы по мере их запроса, что экономит память. Например, вместо создания списка можно использовать
range()илиgenerator expressions. - Прямое обращение к индексам: Избегайте многократного обращения к атрибутам объектов внутри циклов. Лучше заранее сохранить нужное значение в переменной.
- Сокращение количества итераций: Не используйте циклы, которые выполняют ненужные операции. Например, в цикле можно уменьшить диапазон, чтобы избежать лишних шагов.
- Использование встроенных функций: Вместо явных циклов предпочтительнее использовать стандартные функции Python, такие как
sum(),map(),filter(), так как они могут быть более быстрыми, чем их явные аналоги. - Избегание вложенных циклов: Каждый вложенный цикл увеличивает сложность алгоритма. Постарайтесь заменить их более эффективными методами, такими как использование хеш-таблиц для быстрых поисков.
Оптимизация условий
Условия – важная часть логики программы, но их чрезмерное использование или неправильное размещение может замедлить выполнение. Вот несколько методов для повышения производительности:
- Минимизация числа условий: Проводите проверки только тогда, когда это действительно необходимо. Не нужно выполнять одинаковые проверки несколько раз.
- Правильный порядок условий: Часто встречающиеся условия следует проверять первыми, так как это увеличивает вероятность того, что условие будет истинным, и программа пройдет его быстрее.
- Использование логических операторов: Вместо нескольких отдельных условий можно объединить их с помощью логических операторов
and,or, что делает код более компактным и потенциально быстрее исполнимым. - Избегание излишней вложенности: Сложные вложенные условия повышают временную сложность программы. Старайтесь заменять их на более простые или комбинированные логические выражения.
- Применение «раннего выхода» (early return): Вместо того чтобы помещать сложные условия в конец функции, можно выполнить проверку в начале и сразу выйти из функции, если условие выполняется.
Правильная структура циклов и условий помогает избежать значительных потерь производительности. Оптимизируя их, можно значительно ускорить выполнение программ, особенно при работе с большими объемами данных.
Использование встроенных функций и библиотек
Встроенные функции Python оптимизированы для быстрой работы и минимального потребления памяти. Использование этих функций в коде вместо написания собственных аналогов может значительно улучшить производительность. Например, функции sum(), min(), max() работают быстрее, чем аналогичные циклы for. Их использование позволяет не только ускорить выполнение, но и упростить код, повышая его читаемость и поддерживаемость.
Стоит обратить внимание на библиотеку itertools, которая предоставляет ряд мощных инструментов для работы с итерациями. Вместо написания собственных сложных генераторов можно использовать такие функции, как itertools.chain() для объединения нескольких итерируемых объектов, itertools.islice() для частичной итерации или itertools.combinations() для эффективной генерации сочетаний элементов. Эти функции позволяют избежать создания промежуточных списков, что существенно экономит память.
Модуль functools предлагает несколько функций для оптимизации кода. Например, functools.lru_cache() используется для кэширования результатов функций, что особенно полезно при многократных вызовах вычислительных операций с одинаковыми входными данными. Это может значительно ускорить выполнение программ, которые выполняют много повторяющихся вычислений.
Для работы с большими массивами данных эффективнее использовать библиотеки, написанные на C. Библиотека NumPy предоставляет оптимизированные функции для обработки массивов и матриц, что позволяет значительно ускорить выполнение математических операций. Замена обычных циклов на операции с массивами в NumPy может ускорить код в десятки раз.
Также стоит учитывать работу с многозадачностью через multiprocessing или concurrent.futures, когда задача не может быть эффективно решена в одном потоке. Эти модули позволяют параллельно выполнять несколько процессов или потоков, что дает значительное ускорение в задачах с большим количеством вычислений.
Использование встроенных структур данных также влияет на производительность. Например, замена списка на set или dict при поиске элементов может существенно повысить скорость работы, так как эти структуры используют хеширование для быстрого доступа. В случае поиска по коллекции данных, словари и множества будут работать значительно быстрее, чем списки.
Важным аспектом является использование правильных алгоритмов и подходов. Использование функций sorted() и heapq для сортировки и поиска минимальных/максимальных элементов позволяет избежать написания собственных алгоритмов сортировки, которые могут быть менее эффективными. Встроенные алгоритмы Python часто оптимизированы для широкого спектра задач и типов данных, что позволяет использовать их с максимальной эффективностью.
Применение многозадачности и многопоточности
Многозадачность в Python обычно реализуется с использованием модулей threading, asyncio или multiprocessing. Многозадачность позволяет разделить задачи на более мелкие, что улучшает отзывчивость программы. В случае I/O-операций, таких как сетевые запросы или операции с файлами, многозадачность может значительно ускорить выполнение, позволяя выполнять несколько задач одновременно, не ожидая завершения каждой.
Многопоточность полезна для задач, требующих параллельной обработки, например, при выполнении вычислений, которые могут быть разделены на несколько потоков. Однако стоит учитывать, что Python использует механизм Global Interpreter Lock (GIL), который ограничивает выполнение только одного потока Python в один момент времени. Это значит, что многопоточность не даст значительного прироста производительности в случае CPU-bound задач, таких как математические вычисления. В таких случаях лучше использовать многозадачность с модулем multiprocessing, который работает с отдельными процессами, каждый из которых имеет свой собственный интерпретатор Python.
Для улучшения работы с многозадачностью в Python важно понимать различие между синхронными и асинхронными операциями. В случае, если задачи требуют ожидания, например, при запросах к базе данных или сетевых взаимодействиях, стоит использовать асинхронный подход через модуль asyncio. Это позволяет не блокировать основной поток выполнения и эффективно использовать время ожидания.
Для приложений с высоким уровнем параллельности, таких как веб-серверы или программы, работающие с большим количеством подключений, стоит обратить внимание на asyncio в сочетании с aiohttp для асинхронной обработки запросов. Такой подход позволяет значительно сократить задержки, не теряя при этом производительности.
Важно также правильно распределять ресурсы при использовании многозадачности и многопоточности. Неоптимальное использование потоков или процессов может привести к увеличению накладных расходов, особенно при высокой частоте переключений между задачами. Поэтому важно внимательно подходить к выбору числа потоков или процессов в зависимости от мощности системы и характера задач.
Снижение нагрузки на память: работа с большими данными
Для работы с большими массивами данных стоит обратить внимание на библиотеки, такие как NumPy и Pandas. NumPy предоставляет оптимизированные структуры данных, которые экономят память за счёт компактного представления числовых данных, а Pandas позволяет эффективно работать с большими таблицами данных благодаря использованию типов данных с фиксированным размером, таких как `category` или `datetime64`.
Для загрузки и обработки больших файлов, например, CSV или JSON, полезно читать данные порциями с помощью параметра `chunksize` в библиотеках Pandas. Это позволяет загружать в память только часть данных, обрабатывая их поэтапно, что снижает нагрузку на память.
Также стоит учитывать возможности работы с файлами на диске, используя такие методы, как использование базы данных SQLite или формат HDF5 для хранения данных. Эти форматы позволяют сохранять данные в виде блоков и загружать их по частям, что уменьшает потребление памяти.
В случаях, когда нужно работать с большими массивами данных в памяти, можно использовать специализированные структуры данных, такие как `deque` из модуля `collections`. Она позволяет эффективно управлять памятью, добавляя и удаляя элементы с двух сторон, что полезно в ситуациях с потоковой обработкой данных.
Для параллельной обработки больших данных стоит использовать библиотеки, такие как `multiprocessing` или `concurrent.futures`, которые позволяют распределять нагрузку на несколько процессоров, минимизируя использование памяти каждым отдельным процессом.
Не стоит забывать и об оптимизации кода на уровне алгоритмов. Например, использование эффективных алгоритмов сортировки или поиска может существенно снизить потребление памяти. Понимание сложности алгоритмов и выбор наиболее подходящих решений для обработки данных помогает значительно улучшить производительность и снизить нагрузку на память.
Профилирование кода и выявление узких мест
Для повышения производительности Python-кода необходимо не только писать оптимизированный код, но и регулярно анализировать его с помощью инструментов профилирования. Это позволяет выявить участки программы, которые замедляют выполнение, и сосредоточиться на их оптимизации.
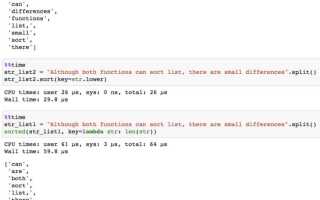
Профилирование – это процесс мониторинга работы программы с целью сбора статистики о времени выполнения различных частей кода. В Python для этого существует несколько инструментов, наиболее популярные из которых – cProfile и line_profiler.
cProfile – стандартный инструмент для профилирования Python-кода. Он анализирует, сколько времени занимает выполнение каждой функции и сколько раз она была вызвана. Для использования достаточно просто запустить программу с ключом профилирования:
python -m cProfile myscript.py
Результаты работы cProfile показывают количество вызовов функций, их общее время работы и время, потраченное на саму функцию без учета времени, потраченного в подфункциях. Это помогает быстро определить, какие функции оказывают наибольшее влияние на производительность.
Для более детального анализа можно использовать line_profiler, который профилирует время выполнения каждого отдельного выражения в строках кода. Это полезно, когда необходимо понять, какая именно строка в функции вызывает задержку. Для работы с line_profiler нужно установить пакет и пометить функции, которые необходимо профилировать, с помощью декоратора:
@profile
После выполнения профилированной программы можно получить подробную информацию о времени, затраченном на каждую строку кода.
После получения профиля важно правильно интерпретировать результаты. Не все медленные участки кода следует немедленно оптимизировать. Оптимизация может привести к усложнению кода, поэтому прежде чем делать изменения, следует оценить, какой эффект они окажут на общую производительность. Важно, чтобы узкие места, выявленные в процессе профилирования, действительно являлись ограничивающим фактором работы программы.
Некоторые распространенные узкие места, которые часто выявляются при профилировании, включают:
- Частые обращения к диску или сети.
- Неэффективное использование структур данных, таких как списки, когда можно использовать множества или словари.
- Задержки, связанные с ненужными вычислениями или повторными операциями в циклах.
После того как узкие места выявлены, следующим шагом будет применение подходящих стратегий оптимизации, таких как использование кеширования, замена медленных операций на более быстрые или применение многозадачности для параллельной обработки данных.
Профилирование – это важный инструмент для повышения производительности, который позволяет не только улучшить конкретные участки кода, но и помогает принять обоснованные решения о том, где и как следует оптимизировать программу.
Реализация алгоритмов с использованием библиотек Cython и PyPy

Cython позволяет ускорить выполнение кода Python, комбинируя его с C, что особенно полезно при работе с вычислительными задачами, требующими интенсивных операций. Чтобы использовать Cython, необходимо преобразовать исходный код Python в C-расширение, которое компилируется в машинный код. Это может привести к значительному увеличению скорости выполнения за счет оптимизации циклов и работы с памятью. Для использования Cython достаточно ввести в код директивы, которые указывают, какие части должны быть компилированы в C, например, с помощью ключевого слова `cdef` для объявления переменных и типов данных. Важно тщательно профилировать код перед и после оптимизации, чтобы убедиться в реальном приросте производительности.
PyPy – это альтернативная реализация интерпретатора Python, использующая JIT-компиляцию для динамической оптимизации кода в процессе его выполнения. PyPy может значительно ускорить многие программы Python, особенно те, которые не сильно зависят от сторонних библиотек на C, поскольку он не требует явных изменений в коде. Основным преимуществом PyPy является способность адаптировать программу к изменениям во время работы, что позволяет минимизировать время ожидания и снизить нагрузку на процессор. PyPy эффективно обрабатывает рекурсивные и циклические алгоритмы за счет улучшенной работы с памятью и лучшей оптимизации кода на лету.
При выборе между Cython и PyPy важно учитывать тип задачи. Если проект требует работы с библиотеками C или нестандартной оптимизации, Cython станет лучшим выбором, так как он позволяет прямо интегрировать Python с кодом на C. Для стандартных задач с интенсивным использованием Python-кода без необходимости прямого взаимодействия с низкоуровневыми библиотеками PyPy может дать значительный прирост производительности без необходимости переписывать существующий код.
Один из способов комбинирования Cython и PyPy – использование Cython для обработки узких мест в коде, где производительность имеет решающее значение, и запуск остальной части приложения через PyPy для повышения общей скорости выполнения. Это позволяет максимально эффективно использовать сильные стороны обеих технологий.
Оптимизация работы с базами данных и API

Для повышения производительности работы с базами данных в Python, важно правильно выбирать подходы для работы с запросами и соединениями. Один из ключевых аспектов – минимизация времени выполнения запросов и ограничение объема передаваемых данных.
Применяйте библиотеку SQLAlchemy для работы с базами данных. Она позволяет эффективно взаимодействовать с реляционными БД через ORM, обеспечивая абстракцию запросов и оптимизацию через использование «ленивых» загрузок (lazy loading) и фильтрации данных до извлечения. Также стоит избегать использования метода ALL() для извлечения всех строк, что может привести к перегрузке памяти.
Использование индексов в базе данных – еще одна важная практика. Индексы значительно ускоряют выполнение запросов на выборку, особенно при наличии сложных условий поиска. Однако индексы имеют свою цену – они замедляют операции вставки и обновления данных, поэтому стоит внимательно подходить к выбору полей для индексации.
Использование кеширования с помощью Redis или Memcached для часто запрашиваемых данных помогает сократить время ожидания. Если API или база данных часто выполняют одни и те же запросы, такие технологии позволяют хранить результаты в памяти и быстро возвращать их при повторных запросах.
С точки зрения работы с API, оптимизация начинается с правильного управления соединениями. Используйте сессии для многократных запросов к одному серверу через requests.Session(), чтобы избежать повторного установления TCP-соединений и повысить производительность. Также важно ограничивать количество одновременных запросов через concurrent.futures или асинхронные библиотеки, такие как aiohttp, чтобы не перегружать сервер.
Обратите внимание на эффективную обработку ошибок API. Ошибки могут происходить по многим причинам: проблемы с сетью, сервером, неверные данные. Использование адекватных тайм-аутов и повторных попыток для кратковременных ошибок (например, через tenacity) улучшит стабильность работы с API.
В случае взаимодействия с REST API стоит применять пагинацию для получения больших объемов данных. Это снизит нагрузку на сеть и ускорит время отклика. Если API поддерживает выборку данных с фильтрацией, всегда используйте фильтры на сервере, а не загружайте лишние данные для последующей фильтрации на клиенте.
Когда нужно работать с большими объемами данных, например, при импорте или экспорте данных, используйте батчи для обработки данных порциями. Это позволит значительно сократить время обработки и снизить нагрузку на систему.
Использование асинхронного программирования в Python
Для реализации асинхронного кода в Python используется модуль asyncio, который предоставляет инструменты для работы с сопрограммами (coroutines). Сопрограммы позволяют приостановить выполнение функции и вернуться к ней позже, что позволяет выполнить другие задачи в промежутке.
Основные компоненты асинхронного программирования:
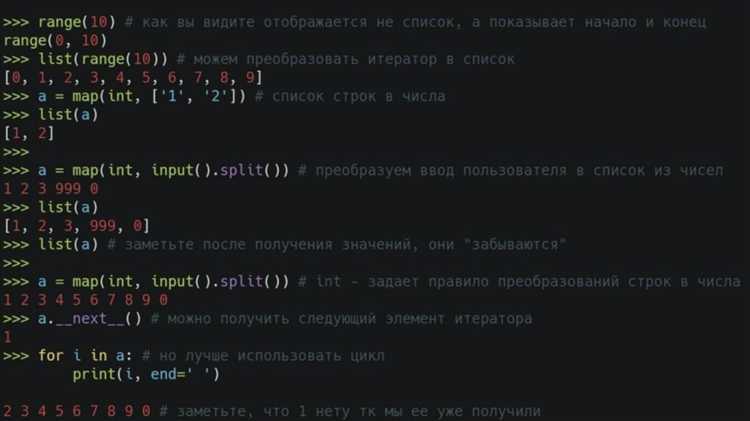
async def– синтаксис для определения асинхронной функции.await– оператор, приостанавливающий выполнение функции до получения результата от асинхронной операции.asyncio.run()– метод для запуска асинхронных задач и создания главного цикла событий.
Пример простого асинхронного кода:
import asyncio
async def fetch_data():
print("Запрос отправлен")
await asyncio.sleep(2)
print("Данные получены")
async def main():
await fetch_data()
asyncio.run(main())
В данном примере функция fetch_data выполняет «долгую» операцию (например, ожидание данных от внешнего источника), не блокируя выполнение программы. Это позволяет, например, одновременно обрабатывать несколько запросов или выполнять другие задачи, не дожидаясь окончания каждой из них.
Практическое применение асинхронного кода включает:
- Обработка множества HTTP-запросов в веб-серверах и клиентах, например, с использованием библиотеки
aiohttp. - Работа с базами данных с использованием асинхронных драйверов, например,
aiomysqlдля MySQL илиasyncpgдля PostgreSQL.
Основные принципы оптимизации с помощью асинхронного программирования:
- Избегайте блокировки основного потока: Используйте
awaitвместо синхронных операций, которые могут блокировать выполнение программы, например,time.sleep(). - Используйте задачи с высокой степенью параллелизма: Асинхронность особенно полезна для сетевых приложений, где важно выполнить множество операций параллельно без значительных потерь в производительности.
- Правильно управляйте исключениями: В асинхронном коде важно правильно обрабатывать исключения, чтобы избежать проблем с незавершёнными задачами.
Ошибки при использовании асинхронного кода:
- Забвение
awaitв асинхронной функции приводит к блокировке выполнения. - Неоптимальное использование асинхронных задач для операций, которые не требуют параллельности (например, обычные вычисления).
- Недостаточная обработка ошибок может привести к неожиданному завершению работы программы.
Вопрос-ответ:
Как уменьшить время выполнения программы на Python?
Чтобы уменьшить время выполнения программы на Python, стоит сначала обратить внимание на использование эффективных алгоритмов и структур данных. Например, используйте списки вместо обычных списков, где это возможно, или рассмотрите использование библиотеки NumPy для работы с массивами чисел. Также важно минимизировать количество повторяющихся операций, например, избегать многократных вычислений одних и тех же значений. Старайтесь также использовать встроенные функции Python, так как они часто оптимизированы для скорости.
Почему использование многозадачности может повысить производительность в Python?
Многозадачность может быть полезна, когда задачи могут быть параллельно выполнены, например, в случае I/O операций. Python позволяет работать с потоками или процессами через библиотеки, такие как threading или multiprocessing. Многозадачность позволяет не тратить время на ожидание завершения операций, таких как чтение с диска или запросы к базе данных, улучшая общую производительность программы.
Какие библиотеки могут ускорить выполнение вычислений в Python?
Существуют несколько библиотек, которые могут значительно ускорить выполнение вычислений в Python. Например, NumPy позволяет работать с многомерными массивами данных и выполнять операции с ними быстрее, чем стандартные списки Python. Для многозадачных вычислений можно использовать библиотеки, такие как Dask, которые параллельно обрабатывают большие объемы данных. Если задача требует работы с большими объемами числовых данных или матриц, можно также использовать библиотеку Cython для компиляции Python-кода в C-код.
Как правильно профилировать код на Python, чтобы найти узкие места в производительности?
Для профилирования кода в Python можно использовать встроенные инструменты, такие как модуль cProfile. Он позволяет увидеть, сколько времени занимает каждая функция в программе. Также полезен модуль timeit для тестирования времени выполнения небольших фрагментов кода. После того как вы обнаружите узкие места, можете попробовать оптимизировать код, например, путем уменьшения числа вызовов функций или улучшения структуры данных, с которой работает программа.
Как уменьшить потребление памяти в программе на Python?
Чтобы уменьшить потребление памяти в Python, следует внимательно относиться к выбору структур данных. Например, вместо обычных списков можно использовать множества или кортежи, которые занимают меньше памяти. Также важно очищать ненужные данные, например, с помощью del или использования встроенной сборки мусора Python. Еще один способ — использовать генераторы, которые позволяют работать с большими данными, не загружая их все сразу в память.