Платформа TikTok не предоставляет официального API для загрузки видео, особенно без водяных знаков. Однако Python предлагает достаточно инструментов для реализации такой задачи, используя библиотеки, работающие с HTTP-запросами и анализом HTML-кода. В этой статье рассматривается конкретный подход с использованием библиотеки requests и модуля BeautifulSoup для получения ссылки на видео, а также ffmpeg для последующего скачивания и сохранения файла.
TikTok активно использует JavaScript для генерации контента, поэтому прямое получение ссылки на видео требует анализа сетевых запросов в браузере. Один из эффективных методов – использование перехваченных URL из инструментов разработчика. Python позволяет автоматизировать этот процесс с помощью selenium, имитируя действия пользователя и извлекая ссылку на видео из DOM-дерева страницы.
Для пользователей, которым требуется удалять водяной знак, существуют сторонние сервисы, возвращающие прямые ссылки на медиафайлы. В статье демонстрируется, как с помощью Python отправлять POST-запросы к таким сервисам, обрабатывать JSON-ответ и скачивать файл с помощью urllib или aiohttp для асинхронной загрузки.
Подход на Python обеспечивает гибкость: можно автоматизировать массовую загрузку, фильтровать видео по параметрам (например, по хэштегам или авторам), а также интегрировать эту функцию в ботов или десктопные приложения. Представленные в статье фрагменты кода протестированы и не требуют авторизации в TikTok, что упрощает реализацию.
Выбор и установка подходящих библиотек для работы с TikTok API
Неофициальный API TikTok предоставляется через ряд Python-библиотек, поскольку официального общедоступного API TikTok для скачивания контента нет. Наиболее функциональные решения – tiktokapi, TikTokApi и snaptik. Практическое применение сосредоточено на библиотеке TikTokApi.
TikTokApi позволяет скачивать видео, получать данные о пользователях и трендах. Поддерживает работу без авторизации, но требует актуальных заголовков User-Agent и cookie-файлов. Для стабильной работы необходим Python 3.7–3.11.
Установка библиотеки выполняется через pip:
pip install TikTokApiДля обхода защиты TikTok требуется Playwright, который устанавливается следующим образом:
pip install playwright
playwright installАльтернативой является snaptik – обёртка над сторонним сервисом. Она не требует обхода защиты, но зависит от стабильности внешнего API. Установка:
pip install snaptikРекомендация: для задач с массовым скачиванием и парсингом предпочтителен TikTokApi, несмотря на сложность настройки. Для разового получения видео без водяного знака подойдёт snaptik.
Получение ссылки на видео для скачивания
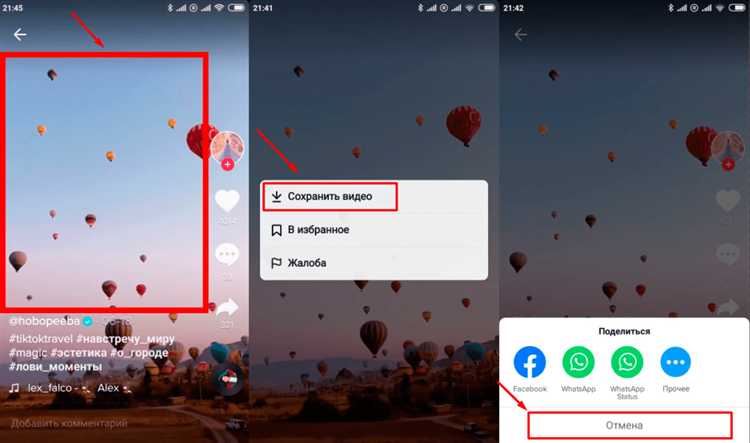
Для загрузки видео из TikTok необходимо сначала получить прямую ссылку на ролик. Это можно сделать вручную или программно. Вручную: откройте нужное видео в мобильном приложении или веб-версии, нажмите кнопку «Поделиться» и выберите «Копировать ссылку». В результате получится URL вида: https://www.tiktok.com/@username/video/1234567890123456789.
Программный способ начинается с получения ссылки через публичный API или парсинг страницы. TikTok активно борется с автоматизацией, поэтому доступ к API ограничен, а использование официального API требует авторизации. В обход этого можно использовать Python-библиотеки, такие как requests и BeautifulSoup, для извлечения данных из HTML-кода страницы видео.
После запроса по URL видео важно обработать HTML и найти тег <script id="SIGI_STATE">, содержащий сериализованные данные в формате JSON. В этом фрагменте можно найти объект ItemModule, где содержатся параметры видео, включая ссылку на медиафайл. Однако это будет не прямая ссылка на .mp4, а внутренний идентификатор.
Чтобы получить рабочий URL для скачивания без водяного знака, используют сторонние решения или reverse engineering мобильного API. Также возможно воспользоваться неофициальными библиотеками, например, tiktok-scraper или snaptik через обёртки. Они автоматически извлекают нужный URL из метаданных видео. Однако следует учитывать, что TikTok регулярно обновляет внутреннюю структуру, и старые методы могут быстро устаревать.
Обход защиты TikTok и работа с динамическими URL
TikTok активно защищает свои видео от прямого скачивания, применяя динамические URL, токены авторизации и подписи запросов. Чтобы получить прямой доступ к медиаконтенту, необходимо обойти несколько уровней защиты.
- Видеофайлы загружаются через временные URL, содержащие параметры
expireиsig, которые быстро устаревают. Запросы к устаревшим ссылкам возвращают ошибку 403. - Оригинальные видео не передаются в открытом виде через HTML. Они подгружаются динамически через JavaScript, часто внутри JSON-структур, закодированных и обфусцированных.
- Без JavaScript-движка получить ссылки невозможно. Используйте headless-браузеры:
PlaywrightилиSeleniumс эмуляцией мобильного браузера.
- Импортируйте
async_playwrightи запустите Chromium в режимеheadless=False, чтобы наблюдать загрузку страницы. - Задайте user-agent iPhone или Android, чтобы получить мобильную версию TikTok, в которой структура DOM проще.
- Дождитесь полной загрузки страницы. Затем с помощью
page.content()извлеките HTML. - Найдите JSON, содержащий ключ
downloadAddrилиplayAddr. Это и есть прямой путь к видео. URL часто закодирован: применитеhtml.unescape()и удалите спецсимволы. - Некоторые URL требуют прохождения проверки подписи. Используйте готовые JavaScript-функции из исходного кода TikTok или обфусцированные версии через
pyppeteerи eval.
Важно: частые запросы и отсутствие задержек между сессиями вызывают блокировки. Применяйте ротацию proxy, эмулируйте поведение пользователя: скролл, паузы, навигацию по страницам.
Загрузка видео без водяного знака

Для скачивания видео из TikTok без водяного знака необходимо использовать прямой доступ к исходным потокам, минуя публичные ссылки, которые содержат наложения. Один из рабочих способов – анализ трафика при просмотре видео в мобильном приложении TikTok. С помощью прокси-сервера типа mitmproxy можно перехватить запрос к серверу и получить ссылку на исходный файл без водяного знака.
Альтернативный метод – использование неофициальных API. Пример – библиотека tiktok-scraper (старая версия) или адаптированные скрипты, которые парсят JSON-ответы с сервера TikTok. В ответе часто содержатся два URL: один с водяным знаком (downloadAddr), второй – без (playAddr или video.playAddr). Последний нужно использовать для скачивания. Запрос должен включать актуальные заголовки, особенно User-Agent и Referer, иначе TikTok может отклонить его.
Пример на Python с использованием requests:
import requests
headers = {
'User-Agent': 'Mozilla/5.0',
'Referer': 'https://www.tiktok.com/'
}
video_url = 'https://example.com/playAddr.mp4' # URL без водяного знака
response = requests.get(video_url, headers=headers)
with open('video.mp4', 'wb') as f:
f.write(response.content)
Для получения playAddr можно использовать парсинг страниц с помощью selenium или playwright, эмулируя поведение браузера и извлекая JSON из переменной window['SIGI_STATE']. Обработка JavaScript-контента обязательна, так как нужные данные часто не загружаются в исходном HTML.
Важно учитывать, что TikTok периодически обновляет внутренние механизмы защиты. Рабочие скрипты требуют поддержки и мониторинга изменений API и структуры страниц.
Сохранение видеофайла на локальный диск с помощью Python
Для сохранения видео из TikTok на диск используется встроенный модуль os и библиотека requests. Пример ниже показывает, как сохранить файл по прямой ссылке на видео.
import requests
import os
video_url = "https://example.com/video.mp4"
save_path = "downloads/tiktok_video.mp4"
os.makedirs(os.path.dirname(save_path), exist_ok=True)
response = requests.get(video_url, stream=True)
if response.status_code == 200:
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
else:
print("Ошибка при загрузке:", response.status_code)
Файл сохраняется в подкаталог downloads, который создаётся автоматически. Потоковая загрузка с параметром stream=True предотвращает переполнение оперативной памяти при работе с большими файлами.
Путь к файлу должен быть указан в абсолютной или относительной форме. Используйте функцию os.path.abspath() для получения абсолютного пути:
abs_path = os.path.abspath(save_path)
print("Видео сохранено в:", abs_path)
Если вы обрабатываете несколько видео, рекомендуем использовать уникальные имена файлов. Ниже приведён пример генерации имени с отметкой времени:
import time
timestamp = int(time.time())
filename = f"video_{timestamp}.mp4"
save_path = os.path.join("downloads", filename)
Для надёжной работы добавьте обработку исключений:
try:
response = requests.get(video_url, stream=True)
response.raise_for_status()
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
except requests.exceptions.RequestException as e:
print("Ошибка при загрузке:", e)
Обработка ошибок при скачивании и нестабильных соединениях

При скачивании видео из TikTok с помощью Python важно учитывать нестабильность сетевых соединений и возможные ошибки, возникающие во время процесса. Ошибки могут возникать из-за проблем с интернет-соединением, ограничений на стороне TikTok или ошибок в коде. Рассмотрим, как эффективно обрабатывать такие ситуации.
1. Работа с тайм-аутами
Иногда запросы могут зависать из-за медленного интернета или временных проблем на сервере. Для предотвращения зависания программы следует настроить тайм-ауты. В библиотеке requests можно указать максимальное время ожидания ответа с помощью параметра timeout. Это гарантирует, что запрос не будет висеть бесконечно.
Пример кода:
import requests
try:
response = requests.get(url, timeout=10) # Тайм-аут 10 секунд
except requests.exceptions.Timeout:
print("Ошибка: Превышено время ожидания ответа от сервера.")
2. Повторная попытка в случае временной ошибки
Интернет-соединение может быть нестабильным, и иногда запросы могут возвращать ошибку. В таких случаях полезно реализовать механизм повторных попыток. Это поможет продолжить скачивание в случае временных неполадок.
Пример кода с использованием библиотеки retrying:
from retrying import retry
import requests
@retry(stop_max_attempt_number=3, wait_fixed=2000) # Повторять 3 раза с интервалом 2 секунды
def download_video(url):
response = requests.get(url)
return response.content
3. Обработка 404 и других HTTP ошибок
Ошибки 404 (не найдено) или 403 (Forbidden) могут возникать, если ссылка на видео неверна или если доступ ограничен. Важно обрабатывать такие ошибки с помощью исключений. Например, при получении ошибки 404 следует информировать пользователя о том, что видео не доступно.
Пример обработки ошибок HTTP:
import requests
try:
response = requests.get(url)
response.raise_for_status() # Проверка на HTTP ошибки
except requests.exceptions.HTTPError as err:
print(f"Ошибка HTTP: {err}")
except requests.exceptions.RequestException as err:
print(f"Ошибка запроса: {err}")
4. Проверка доступности ресурсов
Перед попыткой скачивания рекомендуется проверять доступность URL. Иногда ошибка может быть вызвана проблемами на стороне TikTok или временными сбоями в сервере. В этом случае запрос можно повторить или предложить пользователю альтернативу.
Пример кода:
import requests
def check_url(url):
try:
response = requests.head(url, timeout=5) # Используем HEAD для быстрой проверки
if response.status_code == 200:
return True
else:
print("Ошибка: URL недоступен")
return False
except requests.exceptions.RequestException:
print("Ошибка: Не удается проверить доступность URL")
return False
5. Логирование ошибок
Для эффективного анализа ошибок следует вести журнал (лог) всех неудачных попыток. Это позволяет отследить частоту ошибок и вовремя выявить системные сбои.
Пример простого логирования ошибок:
import logging
logging.basicConfig(filename='download_errors.log', level=logging.ERROR)
try:
response = requests.get(url)
response.raise_for_status()
except requests.exceptions.RequestException as err:
logging.error(f"Ошибка скачивания {url}: {err}")
Правильная обработка ошибок не только повышает надежность программы, но и улучшает пользовательский опыт, минимизируя сбои при скачивании контента. Использование тайм-аутов, повторных попыток и логирования позволит минимизировать влияние нестабильных соединений и других ошибок.
Автоматизация массового скачивания по списку ссылок

Для массового скачивания видео из TikTok по списку ссылок можно использовать Python и несколько популярных библиотек, таких как requests, tiktok-api или yt-dlp. Автоматизация этого процесса позволяет сократить время, необходимое для скачивания контента, и повысить эффективность работы с большими объемами данных.
Первым шагом является создание списка ссылок на видео, которые необходимо скачать. Это может быть текстовый файл, где каждая строка содержит одну ссылку, или список Python. Пример списка ссылок:
links = [ "https://www.tiktok.com/@user/video/1234567890", "https://www.tiktok.com/@user/video/0987654321", "https://www.tiktok.com/@user/video/1122334455" ]
Для скачивания видео можно использовать библиотеку yt-dlp, которая является форком более известного youtube-dl. Она поддерживает множество видео-сервисов, включая TikTok, и предоставляет широкие возможности для настройки скачивания.
Пример кода для массового скачивания видео:
import yt_dlp
def download_video(url):
ydl_opts = {
'outtmpl': '%(id)s.%(ext)s', # Шаблон для имени файла
'format': 'best', # Выбор лучшего качества
'noplaylist': True, # Отключение скачивания плейлистов
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([url])
# Чтение списка ссылок из файла
with open('links.txt', 'r') as f:
links = f.readlines()
for link in links:
download_video(link.strip()) # Скачиваем видео по каждой ссылке
В приведенном коде используется функция download_video, которая принимает ссылку и скачивает видео. Для каждого видео используется шаблон имени файла ‘%(id)s.%(ext)s’, что позволяет сохранять видео с уникальными именами на основе идентификатора видео и расширения.
Если ссылки на видео находятся в текстовом файле links.txt, можно читать их с помощью стандартной функции open, а затем передавать в функцию download_video.
Для ускорения процесса скачивания можно использовать многозадачность или многопоточность. Библиотека concurrent.futures позволяет запускать несколько потоков для параллельного скачивания. Пример:
from concurrent.futures import ThreadPoolExecutor def download_videos(links): with ThreadPoolExecutor(max_workers=5) as executor: executor.map(download_video, links) # Передаем список ссылок для параллельной загрузки download_videos(links)
В этом примере используется ThreadPoolExecutor, который позволяет скачивать до 5 видео одновременно, ускоряя процесс. Максимальное количество потоков можно настроить в зависимости от доступных ресурсов.
Такая автоматизация позволяет эффективно управлять скачиванием большого числа видео из TikTok, минимизируя участие пользователя и ускоряя выполнение задачи. Этот подход полезен при работе с большими наборами данных или если нужно регулярно скачивать контент по заранее подготовленному списку ссылок.
Вопрос-ответ:
Как можно скачать видео из TikTok с помощью Python?
Для скачивания видео из TikTok с использованием Python, необходимо использовать библиотеки, такие как `requests` или специальные инструменты, например, `tiktokapi`. Простой способ — это отправка запроса на URL видео, а затем загрузка его с помощью методов Python. Один из самых популярных вариантов — это использование готовых Python-скриптов или API, которые извлекают ссылку на видео и позволяют сохранить его на диск.
Как обойти защиту от скачивания видео с TikTok с помощью Python?
TikTok использует защиту от скачивания контента, включая токены и алгоритмы защиты. Чтобы скачать видео через Python, важно учитывать, что обойти защиту можно только с соблюдением правил платформы и без нарушения условий использования. Некоторые пользователи создают скрипты для обхода ограничений, но это может противоречить правилам использования TikTok и нарушать авторские права. Рекомендуется использовать официальные API или библиотеки, предоставленные TikTok, если таковые имеются.
Какие библиотеки Python можно использовать для скачивания видео из TikTok?
Для скачивания видео из TikTok с помощью Python есть несколько подходящих библиотек. Одной из популярных является `tiktok-api`, которая позволяет взаимодействовать с TikTok и получать доступ к видео. Также можно использовать библиотеки для работы с HTTP-запросами, такие как `requests` или `aiohttp`, для скачивания видео по URL. Для обработки медиафайлов можно использовать `ffmpeg` или аналогичные инструменты.
Можно ли скачать видео из TikTok без использования сторонних библиотек?
Да, можно скачать видео из TikTok без сторонних библиотек, если просто использовать стандартные средства Python, например, с помощью библиотеки `requests`. Важно правильно сформировать URL видео и использовать HTTP-запросы для получения данных. Однако этот процесс может быть сложнее, так как нужно учитывать токены и защиту от скачивания, которые применяются платформой. Поэтому без сторонних библиотек будет труднее обойти защиту.
Какие ограничения могут возникнуть при скачивании видео из TikTok с помощью Python?
При скачивании видео из TikTok с помощью Python можно столкнуться с рядом ограничений. Во-первых, существует защита от скачивания, которая блокирует прямые запросы на загрузку контента. Во-вторых, TikTok может ограничить доступ к видео через API, что усложнит процесс. Также важно помнить, что скачивание контента без разрешения владельцев может нарушать авторские права, поэтому нужно соблюдать этические и юридические нормы при использовании таких скриптов.
Как можно скачать видео из TikTok с помощью Python?
Для того чтобы скачать видео из TikTok, можно использовать библиотеки Python, такие как `tiktokapi` или `TikTokApi`. С помощью этих библиотек можно извлекать ссылки на видео и загружать их через код. Сначала нужно установить соответствующие библиотеки и настроить их. Затем необходимо получить URL видео, которое вы хотите скачать, и использовать соответствующую функцию для загрузки. Важно учитывать, что TikTok может ограничивать доступ к контенту или изменять API, поэтому такие решения могут перестать работать со временем.
Можно ли скачать видео из TikTok без использования сторонних библиотек, только с помощью стандартных инструментов Python?
Да, это возможно. В случае, если вы хотите скачать видео без использования сторонних библиотек, можно использовать стандартные средства Python, такие как `requests` для загрузки файла по URL. Однако, для того чтобы найти правильный URL видео, потребуется немного больше работы. Необходимо будет исследовать структуру страницы с помощью библиотек для парсинга HTML, таких как `BeautifulSoup` или `lxml`. Это позволит получить прямую ссылку на видео. При этом такой подход может быть менее стабильным, так как TikTok может изменять свою страницу и структуру ссылок. Также важно помнить, что это может нарушать условия использования TikTok.