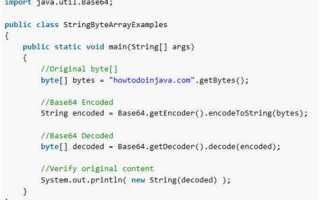
В языке программирования Java работа с текстовыми данными часто требует преобразования строк в байты. Байты являются более низкоуровневыми данными, которые необходимы для работы с сетями, файлами и другими потоками. Понимание того, как правильно преобразовать строку в байты, критически важно для эффективной работы с такими типами данных.
Для преобразования строки в байты в Java используется метод getBytes() класса String. Однако важно учитывать, что строка в Java представлена в виде объектов, кодировка которых может варьироваться. Это имеет значение, потому что разные кодировки могут по-разному интерпретировать символы, что влияет на результат преобразования. Наиболее распространёнными кодировками являются UTF-8, UTF-16 и ISO-8859-1.
Пример использования метода getBytes() выглядит следующим образом:
String str = "Привет, мир!"; byte[] bytes = str.getBytes(StandardCharsets.UTF_8);
Этот код преобразует строку в массив байтов с использованием кодировки UTF-8, которая является наиболее популярной для интернета. Если кодировка не указана, по умолчанию используется кодировка платформы, что может привести к различным результатам на разных системах. Чтобы избежать таких проблем, всегда указывайте кодировку явно.
Использование метода getBytes() для преобразования строки в байты
Первый вариант – это вызов getBytes() без параметров. В этом случае строка преобразуется в байты с использованием платформенной кодировки (по умолчанию это UTF-8). Пример:
String str = "Пример";
byte[] bytes = str.getBytes();Однако использование платформенной кодировки может привести к неожиданным результатам, особенно если приложение работает в разных регионах с различными настройками по умолчанию. Чтобы избежать таких проблем, рекомендуется явно указывать кодировку, которая гарантирует совместимость в разных средах.
Второй вариант – это использование getBytes(String charset), где в качестве аргумента передается название кодировки. Например, чтобы преобразовать строку в байты с использованием UTF-8, следует вызвать метод так:
byte[] bytes = str.getBytes("UTF-8");Явное указание кодировки помогает избежать ошибок, связанных с различиями в кодировках по умолчанию. Особенно важно это при работе с международными приложениями или при передаче данных через сеть.
Одним из важных аспектов при использовании getBytes() является то, что метод может вызывать UnsupportedEncodingException, если указанная кодировка недоступна. Поэтому рекомендуется обрабатывать это исключение или использовать кодировку по умолчанию (например, UTF-8), которая поддерживается на всех платформах.
Как выбрать кодировку при преобразовании строки в байты
Выбор правильной кодировки при преобразовании строки в байты в Java зависит от нескольких факторов, включая целевую среду и предполагаемое использование данных. Преобразование строки в байты осуществляется с помощью метода getBytes(), который принимает кодировку как параметр. Если кодировка не указана, используется система по умолчанию, которая может не подходить для всех случаев.
Наиболее распространённые кодировки: UTF-8, UTF-16 и ISO-8859-1. Каждая из них имеет свои особенности. UTF-8 является универсальной кодировкой, которая поддерживает все символы Unicode и является наиболее предпочтительной в большинстве приложений, особенно при работе с веб-технологиями. UTF-16 используется в Java по умолчанию для хранения строк, однако она может занимать больше памяти и не всегда совместима с внешними системами, требующими других кодировок.
При выборе кодировки важно учитывать, как данные будут использоваться или передаваться. Например, при взаимодействии с веб-сервисами или базами данных часто используется UTF-8. При этом важно удостовериться, что и сервер, и клиент используют одну и ту же кодировку. В случае работы с legacy-системами или старыми базами данных может потребоваться использование ISO-8859-1 или других специализированных кодировок.
Если кодировка не указана явно, система использует кодировку по умолчанию, что может привести к непредсказуемому поведению, особенно в международных приложениях. Рекомендуется всегда указывать кодировку при преобразовании строки в байты, чтобы избежать возможных проблем с несовместимостью символов.
Для указания кодировки в методе getBytes(String charset) необходимо использовать её имя. Например, для UTF-8 кодировка будет выглядеть как «UTF-8», а для ISO-8859-1 – «ISO-8859-1». В случае использования неверной кодировки будет выброшено исключение UnsupportedEncodingException, что позволяет оперативно выявить ошибку в приложении.
Таким образом, выбор кодировки зависит от специфики задачи и среды, в которой происходит обработка данных. Использование универсальной кодировки, такой как UTF-8, является безопасным выбором для большинства современных приложений, но в определённых ситуациях необходимо использовать более узкоспециализированные кодировки для обеспечения совместимости с внешними системами.
Обработка исключений при использовании getBytes() в Java

Метод getBytes() в Java используется для преобразования строки в массив байтов, однако при его использовании важно учитывать возможность возникновения исключений, особенно в контексте кодировки.
Сам метод getBytes() не генерирует явных проверок на исключения, но существует вероятность возникновения ошибок при работе с кодировками. Наиболее важное исключение, с которым стоит столкнуться, это UnsupportedEncodingException. Это исключение возникает, если запрашиваемая кодировка не поддерживается в текущей среде исполнения Java.
При использовании варианта метода getBytes(String charsetName) необходимо убедиться, что строка, переданная в качестве параметра, содержит корректное название кодировки. Если кодировка не поддерживается, будет выброшено исключение UnsupportedEncodingException. Например, если вы укажете кодировку «invalidEncoding», программа завершится с ошибкой:
String text = "Пример текста";
try {
byte[] bytes = text.getBytes("invalidEncoding");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
Чтобы избежать этого, рекомендуется обрабатывать UnsupportedEncodingException в блоке try-catch и использовать стандартные кодировки, такие как UTF-8, которые гарантированно поддерживаются во всех реализациях Java. Например:
String text = "Пример текста";
try {
byte[] bytes = text.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace(); // Запись в лог или альтернативная обработка
}
Если кодировка является частью вашей бизнес-логики и вам нужно работать с несколькими кодировками, всегда проверяйте доступность кодировки с помощью метода Charset.isSupported() перед использованием getBytes():
if (Charset.isSupported("UTF-8")) {
byte[] bytes = text.getBytes("UTF-8");
} else {
System.out.println("Кодировка не поддерживается.");
}
Такой подход минимизирует риск возникновения ошибок и делает код более стабильным и предсказуемым.
Сравнение getBytes() и других методов преобразования строки в байты

Метод getBytes() преобразует строку в массив байтов, используя платформенно-зависимую кодировку по умолчанию, что может привести к потере данных при использовании неподдерживаемых символов. Для получения большего контроля над кодировкой можно использовать перегрузки метода, принимающие параметр типа Charset.
- getBytes(): Использует кодировку по умолчанию (обычно
UTF-8, но зависит от системы). Этот метод может быть недостаточно точным при обработке нестандартных символов. - getBytes(String charsetName): Является более универсальной альтернативой, позволяя явно указать кодировку (например,
UTF-8,ISO-8859-1). Это гарантирует правильное преобразование строки в байты независимо от платформы. - getBytes(Charset charset): Эта версия метода работает аналогично предыдущей, но использует объект
Charsetвместо строки с именем кодировки. Это предоставляет удобство работы с кодировками, особенно при необходимости работы с различными локализациями.
Кроме getBytes(), в Java есть другие способы преобразования строки в байты:
- Charset.encode(CharSequence sequence): Этот метод используется для кодирования строки с использованием заданной кодировки. Он более гибкий и позволяет работать с потоками данных и буферами, что делает его полезным для более сложных задач с кодировкой.
- DataOutputStream.writeUTF(String str): Этот метод записывает строку в поток данных, используя UTF-8. Однако, отличие заключается в том, что результат будет включать префикс с длиной строки в байтах, что важно при чтении данных в другом месте программы.
- String.getBytes(StandardCharsets.UTF_8): С появлением
StandardCharsetsможно легко использовать наиболее популярные кодировки, такие какUTF-8, без необходимости указывать строку с названием кодировки. Это делает код более читаемым и защищенным от ошибок.
Каждый метод имеет свои преимущества в зависимости от контекста задачи:
- getBytes() удобно использовать для быстрого преобразования строки в байты, когда достаточно платформенной кодировки, но в критичных приложениях с международными пользователями предпочтительнее использовать
getBytes(Charset charset). - Charset.encode() предоставляет более высокую гибкость, когда нужно работать с потоками или буферами, а также для кодирования строк в специфические форматы данных.
- writeUTF() полезен в контексте работы с потоками и когда требуется передача строк в формате, подходящем для сетевого общения.
Выбор метода зависит от задачи и требований к кодировке. Если необходимо строго соблюдать стандарты кодировки, лучше использовать перегрузки метода getBytes() с явным указанием кодировки или Charset.encode().
Преобразование строки в байты с учётом специфических кодировок
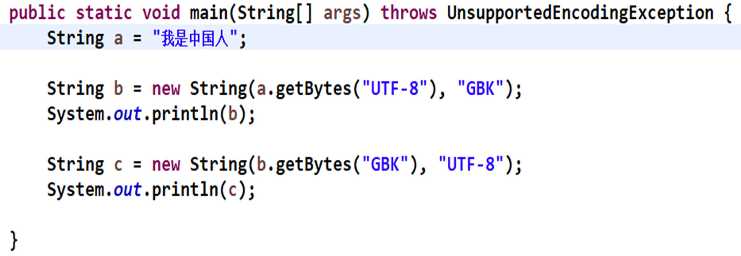
При преобразовании строки в байты в Java важно учитывать кодировку, поскольку одна и та же строка может быть представлена разным количеством байтов в зависимости от выбранной кодировки. Наиболее распространённые кодировки включают UTF-8, UTF-16 и ISO-8859-1. Каждая из них имеет свои особенности, которые необходимо учитывать при конвертации данных.
Для работы с кодировками используется метод getBytes() класса String. Этот метод принимает строку и преобразует её в массив байтов. Чтобы гарантировать корректную конвертацию, необходимо явно указать кодировку. Например, при использовании кодировки UTF-8 метод будет следующим:
String str = "Пример";
byte[] bytes = str.getBytes("UTF-8");
Не указав кодировку, метод по умолчанию использует кодировку платформы, что может привести к непредсказуемым результатам, особенно если кодировка на платформе отличается от нужной.
В случае работы с UTF-8 каждый символ может занимать от 1 до 4 байтов, что делает её гибкой для хранения данных различных языков. В отличие от UTF-8, кодировка UTF-16 всегда использует 2 или 4 байта для представления символа. Это важно учитывать, когда требуется минимизировать объём данных, либо обеспечить совместимость с системами, использующими определённую кодировку.
Для кодировок, таких как ISO-8859-1, каждый символ всегда занимает 1 байт. Это может быть полезно, если требуется работать с текстами, содержащими только латинские буквы и символы, но для других языков, например, кириллицы, эта кодировка не подходит, так как она не поддерживает их.
Рекомендуется всегда явно указывать кодировку при преобразовании строки в байты, чтобы избежать ошибок при передаче данных между различными системами, использующими разные кодировки. При необходимости проверки поддерживаемых кодировок в Java можно использовать класс Charset:
Charset.availableCharsets();
Он возвращает все доступные кодировки, что помогает убедиться, что выбранная кодировка поддерживается на текущей платформе.
Для корректной обработки строк с учётом кодировок необходимо также учитывать возможные исключения, такие как UnsupportedEncodingException, которые могут возникнуть при неверном указании кодировки. Для надёжности стоит использовать кодировку UTF-8, которая является универсальной и поддерживает все символы большинства современных языков.
Оптимизация памяти при преобразовании больших строк в байты
При работе с большими строками важно минимизировать потребление памяти, особенно при их преобразовании в байты. Ниже рассмотрены способы, которые позволяют эффективно управлять памятью при преобразовании строк в байты в Java.
Основной проблемой при преобразовании больших строк в байты является значительное использование памяти, особенно если строка занимает много памяти в Unicode-формате, а затем преобразуется в массив байтов, что может привести к дополнительному выделению памяти и возможным утечкам. Вот несколько методов для оптимизации этого процесса:
- Использование специфичных кодировок: Преобразование строки в байты с использованием кодировки, которая эффективно использует память для конкретного набора символов, может значительно уменьшить объем занимаемой памяти. Например, если строка состоит только из латинских символов, кодировка UTF-8 будет значительно экономичнее, чем UTF-16.
- Избегание временных объектов: Часто при преобразовании строки в байты создаются промежуточные объекты, например, строковые буферы или другие коллекции. Для сокращения использования памяти стоит избегать создания этих объектов, если это возможно.
- Использование потоков: При работе с большими строками можно использовать потоки (например, InputStream, OutputStream) для поэтапной обработки данных, что позволяет избежать создания огромных промежуточных массивов байтов в памяти. Потоки обеспечивают более низкое потребление памяти за счет обработки данных порциями.
- Размер буфера: Использование большого буфера при преобразовании строки в байты может повысить производительность, но приведет к большему использованию памяти. Для балансировки производительности и экономии памяти рекомендуется подбирать размер буфера в зависимости от объема данных. Размер буфера, равный 8-16 KB, обычно является оптимальным для большинства случаев.
- Использование StringBuilder вместо String: Когда необходимо многократно изменять строку перед ее преобразованием в байты, использование StringBuilder будет эффективнее по памяти, чем String, так как String неизменно создает новые объекты при каждом изменении, в то время как StringBuilder изменяет существующий объект.
Каждый из этих методов поможет вам не только улучшить производительность, но и снизить использование памяти при преобразовании строк в байты, что особенно важно при обработке больших объемов данных или в условиях ограниченных ресурсов.
Как восстановить строку из байтов после преобразования
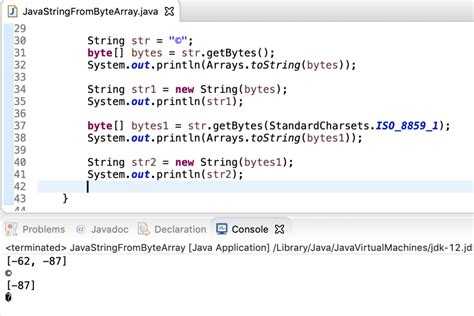
Для восстановления строки из байтов, полученных после преобразования, в Java используется метод String(byte[] bytes, Charset charset). Это позволяет точно восстановить исходную строку, учитывая выбранную кодировку.
Пример восстановления строки из байтов в кодировке UTF-8:
byte[] byteArray = {...}; // Массив байтов, полученный при преобразовании
String restoredString = new String(byteArray, StandardCharsets.UTF_8);Если при преобразовании использовалась другая кодировка, важно указать её при восстановлении. Например, для кодировки ISO-8859-1:
String restoredString = new String(byteArray, StandardCharsets.ISO_8859_1);При отсутствии явного указания кодировки будет использована кодировка по умолчанию системы, что может привести к ошибкам, если байты не соответствуют этой кодировке.
Важно помнить, что при использовании неправильной кодировки для восстановления строки возможна потеря данных или искажение символов. Поэтому всегда проверяйте, что кодировка при преобразовании и восстановлении совпадает.
Практические примеры использования преобразования строки в байты
В Java преобразование строки в байты необходимо для работы с сетевыми соединениями, файловыми операциями и шифрованием. Это особенно важно, когда требуется передать или сохранить данные в бинарном формате.
Для преобразования строки в байты используется метод getBytes(). По умолчанию этот метод использует кодировку UTF-8, но можно указать другую кодировку для специфических случаев.
Пример 1: Преобразование строки в байты по умолчанию (UTF-8):
String text = "Привет, мир!"; byte[] byteArray = text.getBytes();
В этом примере строка «Привет, мир!» преобразуется в байты с использованием кодировки UTF-8. Этот способ подойдет в большинстве случаев, так как UTF-8 является стандартом для обмена текстовыми данными в интернете.
Пример 2: Преобразование строки в байты с указанием конкретной кодировки:
String text = "Привет, мир!";
byte[] byteArray = text.getBytes("ISO-8859-1");
Если необходимо использовать кодировку, отличную от UTF-8, например ISO-8859-1, можно явно указать ее в методе getBytes(). Это полезно, если вы работаете с системами, которые требуют специфической кодировки.
Пример 3: Запись байтов в файл:
import java.io.FileOutputStream;
import java.io.IOException;
String text = "Данные для записи";
byte[] byteArray = text.getBytes();
try (FileOutputStream fos = new FileOutputStream("output.txt")) {
fos.write(byteArray);
} catch (IOException e) {
e.printStackTrace();
}
Здесь строка преобразуется в байты и записывается в файл с помощью FileOutputStream. Такой подход полезен, когда нужно сохранить строку в бинарном формате, например, для обработки в других приложениях.
Пример 4: Использование байтов для передачи данных через сеть:
import java.net.*;
import java.io.*;
String message = "Сообщение для отправки";
byte[] byteArray = message.getBytes();
DatagramSocket socket = new DatagramSocket();
InetAddress receiverAddress = InetAddress.getByName("localhost");
DatagramPacket packet = new DatagramPacket(byteArray, byteArray.length, receiverAddress, 12345);
socket.send(packet);
socket.close();
В этом примере строка отправляется как байтовый массив через UDP-сокет. Байты передаются в сети, что актуально для приложений, работающих с сетевыми протоколами.
Преобразование строки в байты позволяет эффективно работать с данными в бинарном формате, что важно для сетевых коммуникаций, шифрования и других операций, где точность и оптимизация передачи данных критичны.
Вопрос-ответ:
Почему важно указывать кодировку при преобразовании строки в байты?
Когда строка преобразуется в байты, результат зависит от выбранной кодировки. В Java кодировка по умолчанию может не подходить для всех случаев, особенно если приложение должно работать с различными языками или внешними системами. Например, кодировка UTF-8 поддерживает большинство символов, включая символы кириллицы, а кодировка Windows-1251 может не корректно обработать символы, не входящие в латинский алфавит. Использование правильной кодировки помогает избежать ошибок и гарантирует правильное отображение данных в разных системах.
Что произойдет, если не указать кодировку при преобразовании строки в байты?
Если при преобразовании строки в байты не указана кодировка, Java использует кодировку по умолчанию, которая зависит от операционной системы или среды выполнения. Это может привести к непредсказуемым результатам, особенно если строка содержит символы, не поддерживаемые в кодировке по умолчанию. Например, если строка на кириллице будет преобразована в байты без указания кодировки, на некоторых системах символы могут быть искажены или заменены на другие символы, что приведет к потере информации. Поэтому всегда рекомендуется явно указывать кодировку, чтобы избежать подобных проблем.