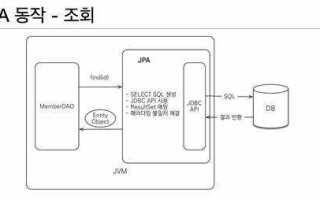
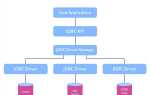
Java Persistence API (JPA) – это стандарт Java для работы с объектно-реляционным отображением (ORM), позволяющий описывать, управлять и сохранять данные Java-объектов в реляционной базе данных без использования явных SQL-запросов. JPA не является реализацией, а лишь спецификацией, которую реализуют такие библиотеки, как Hibernate, EclipseLink и DataNucleus.
Основная идея JPA заключается в описании связей между объектами и таблицами базы данных с помощью аннотаций. Аннотации вроде @Entity, @Id, @OneToMany и @JoinColumn позволяют указать, какие поля класса соответствуют колонкам таблицы, а также задать правила связей между таблицами.
Работа с JPA начинается с настройки persistence.xml или использования Spring Boot, где конфигурация может задаваться в application.properties. Обязательные параметры включают URL базы данных, имя пользователя, пароль и указание используемой реализации JPA. Без этого JPA-контекст не будет создан, и доступ к базе будет невозможен.
Для взаимодействия с базой используется EntityManager. Через него выполняются операции persist, merge, remove и find. Все операции должны выполняться в рамках транзакции, которую можно контролировать вручную или через декларативную аннотацию @Transactional в Spring.
Работа с запросами возможна как через JPQL (аналог SQL, но с ориентацией на Java-классы), так и через Criteria API, который позволяет строить запросы программно и безопасно с точки зрения типов. Это особенно полезно для сложной фильтрации и динамических условий.
Как настроить JPA в проекте на основе Maven
Для подключения JPA в Maven-проекте требуется добавить зависимости в pom.xml. Пример конфигурации с использованием Hibernate:
<dependencies>
<dependency>
<groupId>jakarta.persistence</groupId>
<artifactId>jakarta.persistence-api</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.4.Final</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.3</version>
</dependency>
</dependencies>
Создайте файл persistence.xml в директории src/main/resources/META-INF. В этом файле настраивается единица хранения:
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
version="3.0">
<persistence-unit name="main-unit" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<class>com.example.model.User</class>
<properties>
<property name="jakarta.persistence.jdbc.url" value="jdbc:postgresql://localhost:5432/mydb"/>
<property name="jakarta.persistence.jdbc.user" value="postgres"/>
<property name="jakarta.persistence.jdbc.password" value="password"/>
<property name="jakarta.persistence.jdbc.driver" value="org.postgresql.Driver"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/>
<property name="hibernate.show_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
Реализация сущностей должна соответствовать стандарту JPA. Пример класса:
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
// геттеры и сеттеры
}
Для инициализации EntityManager используйте Persistence.createEntityManagerFactory("main-unit"). Не используйте фабрику повторно, создавайте один экземпляр на приложение и закрывайте его при завершении работы.
Что такое Entity и как правильно её описывать

Имя класса, по умолчанию, соответствует имени таблицы, но его можно переопределить с помощью аннотации @Table(name = "имя_таблицы"). Названия полей отражают имена столбцов. Для явного указания используется @Column(name = "имя_столбца"), если требуется задать иное имя, тип или дополнительные параметры.
Каждое поле должно иметь геттеры и сеттеры. Приватные поля, доступ к которым осуществляется через методы, обеспечивают корректную работу JPA. Стандартный конструктор без аргументов обязателен, иначе фреймворк не сможет создать экземпляр класса.
Тип поля, помеченного @Id, чаще всего Long или UUID. Для автогенерации ключа применяется @GeneratedValue(strategy = GenerationType.IDENTITY) или другие стратегии, в зависимости от СУБД и требований проекта.
Для связей между таблицами используются аннотации @OneToOne, @OneToMany, @ManyToOne, @ManyToMany и @JoinColumn. Обратные стороны связей требуют параметра mappedBy. Правильное описание связей исключает дублирование и ошибки при сериализации.
Инициализация коллекций в связях (например, List, Set) должна происходить сразу, чтобы избежать NullPointerException и проблем при каскадных операциях. Используйте new ArrayList<>() или new HashSet<>() в конструкторе или при объявлении.
Переопределение equals() и hashCode() должно основываться на идентификаторе. Избегайте использования коллекций и связанных сущностей в этих методах, чтобы предотвратить зацикливание и утечки памяти.
Наследование возможно с использованием @Inheritance. Наиболее распространённый вариант – @Inheritance(strategy = InheritanceType.JOINED), при котором каждая сущность хранится в своей таблице и связывается с родительской через внешний ключ.
Как использовать аннотации для связей между таблицами
JPA предоставляет аннотации для описания связей между сущностями, отражающих отношения в базе данных: @OneToOne, @OneToMany, @ManyToOne и @ManyToMany. Каждая из них применяется в зависимости от типа связи между таблицами и влияет на схему генерации SQL-запросов и каскадных операций.
Для связи «один к одному» используется @OneToOne. Например, если у каждого пользователя есть один паспорт, то в сущности User нужно объявить поле с аннотацией @OneToOne и указать @JoinColumn для определения внешнего ключа:
@OneToOne
@JoinColumn(name = "passport_id")
private Passport passport;
Связь «многие к одному» обозначается @ManyToOne. Это характерно, например, для связи между заказами и пользователем, где много заказов могут принадлежать одному пользователю:
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
Для обратной стороны связи используется @OneToMany. Важно указать атрибут mappedBy, чтобы избежать создания лишней промежуточной таблицы:
@OneToMany(mappedBy = "user")
private List<Order> orders;
Связь «многие ко многим» требует аннотации @ManyToMany. По умолчанию создается промежуточная таблица. Можно указать её явно через @JoinTable:
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses;
Для каскадных операций добавляется атрибут cascade, а для подгрузки – fetch. Пример:
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List<Order> orders;
Нельзя использовать аннотации без понимания их влияния на структуру базы и поведение ORM. Обязательно учитываются направление связи, тип загрузки и каскадирование.
Чем отличается EntityManager от Repository и когда использовать каждый

persist()– сохраняет новую сущность в базе данных.merge()– обновляет уже существующую сущность.remove()– удаляет объект.find()иcreateQuery()– используются для загрузки данных вручную.getTransaction()– необходимо вручную управлять транзакциями (вне Spring).
Repository – это абстракция, предоставляемая Spring Data JPA. Интерфейсы CrudRepository, JpaRepository, PagingAndSortingRepository упрощают стандартные операции и автоматически реализуются Spring’ом. Репозитории сокращают объём кода и устраняют необходимость вручного написания SQL или JPQL в простых случаях.
- Методы
save(),findById(),delete()реализуются автоматически. - Возможность объявления методов с автогенерацией запросов по имени:
findByUsernameAndStatus(). - Поддержка пагинации и сортировки из коробки.
- Интеграция с Spring Context, транзакции управляются автоматически через
@Transactional.
Когда использовать EntityManager:
- Необходимо использовать нестандартные JPQL или SQL-запросы.
- Требуется ручное управление транзакциями или состоянием контекста персистентности.
- Нужно повысить производительность за счёт тонкой настройки запросов и кэширования.
Когда использовать Repository:
- Работа ограничивается стандартными CRUD-операциями.
- Проект использует Spring Data и требуется быстрое прототипирование.
- Не нужны прямые SQL-запросы или сложная оптимизация под конкретную БД.
EntityManager обеспечивает максимальную гибкость, но требует больше кода и понимания внутренней работы JPA. Репозитории экономят время на типичных задачах и лучше подходят для большинства приложений, где важна скорость разработки.
Как выполнять запросы с помощью JPQL и Criteria API

JPQL (Java Persistence Query Language) позволяет формировать запросы к сущностям, а не к таблицам. Пример выборки всех пользователей с определённым статусом:
TypedQuery<User> query = entityManager.createQuery(
"SELECT u FROM User u WHERE u.status = :status", User.class);
query.setParameter("status", Status.ACTIVE);
List<User> users = query.getResultList();Для агрегатных функций:
Long count = entityManager.createQuery(
"SELECT COUNT(u) FROM User u WHERE u.registered = true", Long.class)
.getSingleResult();При необходимости объединения таблиц используется JOIN:
List<Order> orders = entityManager.createQuery(
"SELECT o FROM Order o JOIN o.customer c WHERE c.city = :city", Order.class)
.setParameter("city", "Москва")
.getResultList();Criteria API подходит для динамически формируемых запросов. Пример фильтрации пользователей по дате регистрации:
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<User> cq = cb.createQuery(User.class);
Root<User> user = cq.from(User.class);
cq.select(user).where(cb.greaterThan(user.get("registrationDate"), someDate));
List<User> result = entityManager.createQuery(cq).getResultList();Для сложных условий можно использовать Predicate:
List<Predicate> predicates = new ArrayList<>();
if (name != null) {
predicates.add(cb.equal(user.get("name"), name));
}
if (status != null) {
predicates.add(cb.equal(user.get("status"), status));
}
cq.where(cb.and(predicates.toArray(new Predicate[0])));Для сортировки используется orderBy:
cq.orderBy(cb.desc(user.get("lastLogin")));JPQL проще и читаемее, если структура запроса заранее известна. Criteria API предоставляет больше гибкости при генерации запросов во время выполнения.
Как настроить каскадные операции и управление транзакциями
В JPA каскадные операции позволяют автоматически выполнять действия с зависимыми сущностями, такие как сохранение, обновление или удаление. Для настройки каскадных операций используется аннотация @Cascade, которая указывается на ассоциациях между сущностями (например, @OneToMany, @ManyToOne, @ManyToMany). При этом важно учитывать, что каскадные операции не всегда необходимы, их следует применять с осторожностью, чтобы не повлиять на производительность и логику приложения.
Для настройки каскадных операций в JPA необходимо указать в аннотациях, какие операции должны быть выполнены для зависимых сущностей. Например:
@OneToMany(cascade = CascadeType.ALL)
private List children;
Здесь операция CascadeType.ALL позволяет автоматически каскадировать все основные операции (сохранение, обновление, удаление) на сущности ChildEntity. Можно также указать конкретные операции, например:
@OneToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
private List children;
Это указывает, что каскадировать будут только сохранение (PERSIST) и обновление (MERGE) сущностей, но не удаление (REMOVE).
Что касается управления транзакциями, то в JPA оно обычно выполняется через EntityManager, который предоставляет методы для начала, подтверждения и отката транзакций. Важным аспектом является правильное использование аннотаций транзакций для обеспечения атомарности операций.
Для настройки транзакций в JPA чаще всего используется аннотация @Transactional, которая применяется к методам или классам. Например:
@Transactional
public void saveEntity(Entity entity) {
entityManager.persist(entity);
}
Аннотация @Transactional позволяет обеспечить автоматическое управление транзакциями – если метод завершится успешно, транзакция будет зафиксирована; в случае исключения – откатится. Если приложение использует Spring, можно также настроить уровни изоляции и propagation для более сложных сценариев работы с транзакциями.
Важно помнить, что каскадирование операций и управление транзакциями должны быть настроены в зависимости от бизнес-логики приложения. Неправильная настройка каскадирования может привести к несанкционированному удалению данных, а ошибки в транзакционном менеджменте – к потере данных или их некорректному состоянию.
Вопрос-ответ:
Что такое JPA и зачем его использовать в Java?
JPA (Java Persistence API) — это спецификация для работы с базами данных в Java-приложениях. Она предоставляет стандартный интерфейс для отображения объектов Java на таблицы базы данных. JPA упрощает взаимодействие с базой данных, позволяя разработчикам работать с объектами, а не с SQL-запросами, тем самым снижая количество ошибок и улучшая читаемость кода. Это важно при разработке крупных приложений, где необходимо часто работать с базой данных.
Как настроить JPA в проекте на Java?
Для настройки JPA в проекте нужно подключить зависимость в файл pom.xml (если используется Maven). Например, можно добавить зависимость от Hibernate (реализация JPA) и драйвера базы данных. Затем, в файле persistence.xml указывается настройки подключения к базе данных, а также классы-сущности, которые будут отображаться в таблицы базы данных. После этого можно начинать работу с репозиториями и сущностями в коде.
Что такое сущности в JPA и как их использовать?
Сущности в JPA — это классы, которые отображаются на таблицы в базе данных. Каждый объект класса будет связан с записью в таблице, а его поля — с колонками таблицы. Для того чтобы класс стал сущностью, его нужно пометить аннотацией @Entity. В сущности также могут быть указаны связи с другими сущностями, например, @OneToMany или @ManyToOne для описания отношений между таблицами.
Какие основные аннотации используются в JPA?
В JPA есть несколько ключевых аннотаций, которые упрощают работу с сущностями. Например, @Entity — для пометки класса как сущности, @Id — для указания поля, которое будет являться первичным ключом, @GeneratedValue — для генерации значений первичного ключа. Также часто используется аннотация @Column, чтобы настроить параметры столбца, например, его имя или тип данных. Важно правильно комбинировать эти аннотации для правильной работы с базой данных.
Что такое EntityManager в JPA и как с ним работать?
EntityManager — это интерфейс, который предоставляет API для работы с сущностями в JPA. Он позволяет создавать, изменять, удалять и искать сущности в базе данных. Для работы с EntityManager обычно используется контейнер зависимостей, например, через внедрение с помощью @PersistenceContext. Для выполнения операций с сущностями используются методы EntityManager, такие как persist (для сохранения объектов), merge (для обновления объектов) и remove (для удаления объектов).