Чтение данных из файла в Python – это стандартная задача, с которой сталкиваются программисты при обработке информации. В Python для работы с файлами используется встроенная функция open(), которая позволяет открыть файл для чтения, записи или добавления данных. После открытия файла данные могут быть прочитаны различными способами, в зависимости от того, как нужно обработать содержимое.
Самый простой способ – это использование метода read(), который считывает весь файл целиком. Например, чтобы прочитать текстовый файл, достаточно выполнить команду: file = open(‘имя_файла.txt’, ‘r’), а затем data = file.read(). Важно не забывать закрывать файл с помощью file.close() или использовать контекстный менеджер with, что гарантирует автоматическое закрытие файла после завершения работы.
Если файл слишком большой, чтобы читать его целиком, можно использовать метод readline(), который считывает файл построчно. Для обработки больших текстов часто применяют цикл for line in file, что позволяет эффективно работать с файлами без излишней нагрузки на память. В случае работы с бинарными файлами следует указать флаг ‘rb’ при открытии файла.
Не стоит забывать о корректной обработке исключений при чтении файлов. Использование конструкции try-except позволяет избежать сбоев при отсутствии файла или его повреждении. Важно также учитывать кодировку файла, особенно если файл содержит текст на разных языках. Обычно кодировка указывается при открытии файла, например, open(‘имя_файла.txt’, ‘r’, encoding=’utf-8′).
Чтение текстовых файлов с помощью функции open()
Функция open() в Python используется для работы с файлами, включая их чтение. Она открывает файл и возвращает объект файла, который можно использовать для доступа к данным внутри файла. Важно помнить, что файл должен быть закрыт после завершения работы с ним. Это можно сделать с помощью метода close() или контекстного менеджера with.
Пример базового чтения файла:
file = open('example.txt', 'r')
content = file.read()
file.close()
print(content)В данном примере открывается файл в режиме чтения 'r', затем считывается весь его текст с помощью метода read(), и файл закрывается.
Режимы открытия файлов:
'r'– чтение. Файл должен существовать, иначе будет вызвана ошибка.'w'– запись. Если файл существует, его содержимое будет перезаписано.'a'– добавление. Данные будут записаны в конец файла.'rb','wb'– бинарный режим для работы с двоичными данными.'r+'– чтение и запись.
Если файл не существует, при попытке открыть его в режиме 'r' будет вызвана ошибка. В таких случаях можно использовать конструкцию с блоком try...except для обработки исключений.
Для удобства работы с файлами рекомендуется использовать контекстный менеджер with, который автоматически закроет файл после завершения работы:
with open('example.txt', 'r') as file:
content = file.read()
print(content)Контекстный менеджер гарантирует, что файл будет закрыт, даже если во время работы с ним возникнет ошибка.
Методы для чтения данных:
read()– считывает весь файл в одну строку. Если файл большой, это может потребовать значительных ресурсов.readline()– считывает одну строку. Можно использовать в цикле для построчного чтения файла.readlines()– возвращает список всех строк файла.
Для больших файлов рекомендуется использовать чтение по строкам, чтобы не загружать весь файл в память:
with open('example.txt', 'r') as file:
for line in file:
print(line.strip())Этот метод позволяет эффективно работать с большими текстовыми файлами без значительного расхода памяти.
Использование метода read() для извлечения данных
При вызове file.read() весь содержимое файла загружается в переменную. Это может быть полезно, когда нужно обработать данные целиком, например, для анализа текста. Однако важно помнить, что при чтении большого файла с использованием read() возможен высокий расход памяти, так как весь файл будет загружен в оперативную память.
Пример использования:
with open('example.txt', 'r') as file:
content = file.read()
print(content)Метод read() также принимает аргумент, который указывает количество байт, которые нужно прочитать. Например, file.read(100) прочитает первые 100 байт файла. Если аргумент не указан, будет прочитано всё содержимое файла.
При работе с большими файлами рекомендуется использовать чтение файла по частям, чтобы избежать загрузки всей информации в память. Например, можно читать файл в цикле по блокам, что позволяет контролировать объём данных, загружаемых в память в каждый момент времени.
Пример чтения файла по частям:
with open('large_file.txt', 'r') as file:
while chunk := file.read(1024): # Чтение по 1024 байта
process(chunk)Этот метод позволяет эффективно работать с большими файлами, обрабатывая их кусками, что помогает избежать проблем с памятью.
Чтение файла построчно с помощью метода readline()
Метод readline() позволяет читать файл построчно, что удобно при работе с большими файлами, когда загрузка всего содержимого в память может быть неэффективной или невозможной. Этот метод возвращает одну строку за раз, включая символ новой строки в конце строки, если таковой имеется.
Пример использования:
with open('example.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip()) # Удаляем символ новой строки
line = file.readline()В данном примере строка читается в цикле до тех пор, пока метод readline() не вернёт пустую строку, что означает конец файла.
Особенности метода:
- Метод возвращает строку, включая символ новой строки, если он присутствует. Для удаления лишнего символа можно использовать
strip(). - После чтения строки позиция указателя в файле сдвигается, что позволяет последовательно читать файл.
- Если файл слишком большой, этот метод предпочтительнее для работы, так как не требует загрузки всего файла в память.
Рекомендации:
- Используйте
with open()для автоматического закрытия файла после завершения работы, что гарантирует правильное освобождение ресурсов. - Чтение файла с помощью
readline()может быть неэффективным при частых операциях с маленькими файлами, так как метод вызывает дополнительные операции с файловой системой. - Для обработки больших текстов можно использовать цикл, который будет читать файл до конца, обрабатывая каждую строку по мере чтения.
Обработка больших файлов с методом readlines()
Метод readlines() позволяет читать все строки из файла и сохранять их в список. Для работы с большими файлами важно учитывать, что этот метод может вызвать высокое потребление памяти, так как загружает весь файл в оперативную память сразу. Это может стать проблемой при обработке очень крупных файлов.
Для минимизации использования памяти, можно обрабатывать файл построчно, используя readlines() в сочетании с подходами, такими как обработка данных пакетами. Например, можно читать файл частями, передавая его в другие структуры данных или сразу же обрабатывая. Важно помнить, что при чтении больших файлов с помощью readlines() файл должен быть в доступном для чтения состоянии, а также обеспечить правильное управление позиционированием указателя файла.
Пример эффективного использования readlines() для чтения больших файлов:
def process_large_file(filename):
with open(filename, 'r') as file:
# Чтение файла частями
chunk_size = 1000 # Размер "пакета" строк для чтения
while True:
lines = [file.readline() for _ in range(chunk_size)]
if not lines:
break
# Обработка строк
for line in lines:
process_line(line)
В данном примере используется цикл, который читает строки пакетами, уменьшая нагрузку на память. Каждый пакет строк обрабатывается до того, как следующий будет загружен, что позволяет эффективно работать с большими файлами, не перегружая память.
Чтение CSV файлов с помощью библиотеки csv
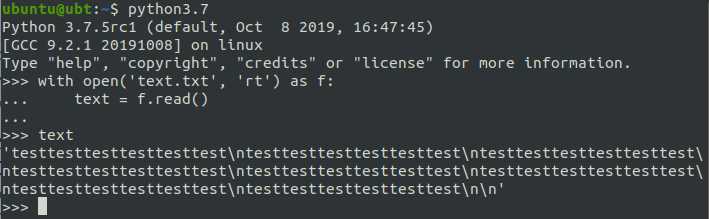
Первый шаг – это импортирование библиотеки:
import csvДля чтения данных из CSV файла, нужно открыть его с помощью встроенной функции open. Затем создается объект csv.reader, который преобразует содержимое файла в последовательность строк.
with open('data.csv', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)В данном примере:
newline=''– это параметр, который обеспечивает правильное чтение строк, исключая ошибки из-за лишних пустых строк.encoding='utf-8'– указывает кодировку файла для корректной обработки символов.
После создания объекта csv.reader можно проходить по строкам CSV файла. Каждая строка представляется как список значений, где каждый элемент соответствует отдельной ячейке CSV файла.
Если файл содержит заголовки, их можно пропустить с помощью метода next, чтобы начать чтение с первой строки данных:
with open('data.csv', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
next(reader) # Пропуск заголовков
for row in reader:
print(row)При необходимости можно преобразовать данные в более удобный формат, например, в словарь, используя csv.DictReader. В этом случае ключи словаря будут соответствовать заголовкам столбцов:
with open('data.csv', newline='', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
print(row)Важно учитывать, что библиотека csv предполагает наличие разделителей (по умолчанию – запятая). Если ваш файл использует другой символ (например, точку с запятой), можно указать параметр delimiter:
with open('data.csv', newline='', encoding='utf-8') as file:
reader = csv.reader(file, delimiter=';')
for row in reader:
print(row)Для более сложных файлов можно настроить дополнительные параметры, такие как quotechar (символ для экранирования значений) или skipinitialspace (игнорирование пробелов после разделителей).
При обработке больших файлов или необходимости оптимизации производительности стоит учитывать, что чтение CSV с использованием библиотеки csv – это эффективный способ работы с данными, особенно когда данные хранятся в виде простых таблиц без вложенных структур.
Чтение данных из JSON файлов с использованием модуля json
Модуль json в Python предоставляет простые и эффективные способы работы с JSON (JavaScript Object Notation) файлами. Он позволяет легко читать и записывать данные в формате JSON, который широко используется для обмена данными между сервером и клиентом.
Для чтения данных из JSON файла используется функция json.load(). Эта функция открывает файл, читает его содержимое и преобразует JSON-данные в соответствующие объекты Python, такие как словари, списки, строки и числа.
Пример чтения JSON данных из файла:
import json
# Открытие файла и чтение данных
with open('data.json', 'r', encoding='utf-8') as file:
data = json.load(file)
print(data)В данном примере open() открывает файл в режиме чтения с указанием кодировки UTF-8 для правильной обработки символов. Далее с помощью json.load(file) содержимое файла преобразуется в Python-объект.
Если JSON-файл содержит ошибку в формате, Python выдаст исключение json.JSONDecodeError. Для обработки таких ошибок можно использовать конструкцию try-except:
import json
try:
with open('data.json', 'r', encoding='utf-8') as file:
data = json.load(file)
except json.JSONDecodeError as e:
print(f"Ошибка при декодировании JSON: {e}")Этот способ поможет избежать аварийных завершений программы при поврежденных или некорректных файлах.
Чтение JSON из строки вместо файла выполняется с помощью функции json.loads(), которая преобразует строку JSON в объект Python. Пример:
import json
json_string = '{"name": "Иван", "age": 30}'
data = json.loads(json_string)
print(data)В отличие от json.load(), которая работает с файлами, json.loads() принимает строку в качестве аргумента и возвращает объект Python.
Использование модуля json для работы с JSON файлами в Python позволяет эффективно обмениваться данными в формате, удобном для большинства веб-сервисов и API.
Обработка ошибок при чтении файлов в Python
Для обработки ошибок в Python используется механизм исключений. Когда возникает ошибка, программа возбуждает исключение, которое можно перехватить и обработать с помощью конструкции try-except.
Основные типы ошибок при чтении файлов:
- FileNotFoundError – ошибка, возникающая, когда файл не существует по указанному пути.
- PermissionError – ошибка, если у программы нет прав для чтения файла.
- IsADirectoryError – ошибка, если указан путь к директории, а не к файлу.
- UnicodeDecodeError – ошибка при попытке чтения файла с неверной кодировкой.
Пример базовой обработки ошибок при открытии файла:
try:
with open('file.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден")
except PermissionError:
print("Нет прав для чтения файла")
except Exception as e:
print(f"Произошла ошибка: {e}")В этом примере программа попытается открыть файл file.txt для чтения. В случае возникновения одной из перечисленных ошибок будет выведено соответствующее сообщение.
Дополнительно стоит учитывать следующее:
- Используйте
withдля работы с файлами. Этот метод автоматически закроет файл после завершения работы, даже если возникнет ошибка. - Если вам нужно обработать несколько типов ошибок, можете указать их в отдельных
exceptблоках, как показано в примере выше. - Для диагностики ошибок используйте объект исключения, например,
as e, чтобы получить подробную информацию о проблеме. - Если файл содержит текст в определенной кодировке, укажите параметр
encodingпри открытии, чтобы избежать ошибок декодирования.
Пример с указанием кодировки:
try:
with open('file.txt', 'r', encoding='utf-8') as file:
content = file.read()
except UnicodeDecodeError:
print("Ошибка декодирования файла")
При соблюдении этих рекомендаций ваша программа будет готова к безопасному и стабильному чтению файлов, а обработка ошибок позволит избежать сбоев в работе.
Вопрос-ответ:
Как в Python открыть и прочитать данные из текстового файла?
Для того чтобы открыть и прочитать данные из текстового файла в Python, используется встроенная функция `open()`. Например, чтобы открыть файл на чтение, достаточно написать `with open(‘имя_файла.txt’, ‘r’) as file:`, где `’r’` — это режим чтения. Внутри блока `with` можно применить метод `read()`, чтобы прочитать содержимое файла целиком, или `readline()` для построчного чтения. Важно помнить, что использование контекстного менеджера `with` позволяет автоматически закрывать файл после завершения работы с ним.
Какие существуют способы работы с большими файлами в Python?
Когда работаешь с большими файлами, важно не загружать весь файл в память сразу. Вместо этого можно читать его построчно. Для этого идеально подходит использование функции `open()` в режиме чтения и метода `readline()` или перебора строк с помощью цикла `for`. Это позволяет эффективно обрабатывать большие файлы, не загружая их целиком в память. Также, если нужно выполнить обработку больших объемов данных, можно использовать буферизацию с помощью параметра `buffering` в `open()` или использовать библиотеки вроде `pandas`, которые предоставляют более сложные средства для работы с большими данными.
Как в Python записывать данные в файл?
Для записи в файл в Python используется функция `open()`, но с режимом записи — `’w’`, `’a’` или `’x’`. Например, чтобы создать новый файл или перезаписать существующий, можно использовать `’w’`: `with open(‘имя_файла.txt’, ‘w’) as file:`, а затем использовать метод `write()` для записи строки в файл. Если нужно дописать данные в конец существующего файла, следует выбрать режим `’a’`. Важно помнить, что режим `’w’` перезапишет файл, а `’a’` добавит информацию в конец файла.
Как в Python работать с файлами в формате CSV?
Для работы с файлами CSV в Python удобно использовать модуль `csv`. Для чтения CSV-файла можно использовать функцию `csv.reader()`. Пример: `with open(‘файл.csv’, ‘r’) as file: reader = csv.reader(file)`, затем можно пройтись по строкам файла с помощью цикла. Если нужно записывать данные в CSV-файл, применяется `csv.writer()`. Например, `with open(‘файл.csv’, ‘w’, newline=») as file: writer = csv.writer(file)` — это создаст новый CSV-файл, в который можно записывать строки данных. Для более сложных операций с CSV-файлами можно использовать библиотеку `pandas`, которая позволяет работать с данными в виде таблицы.