

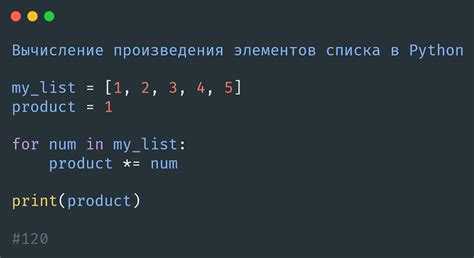
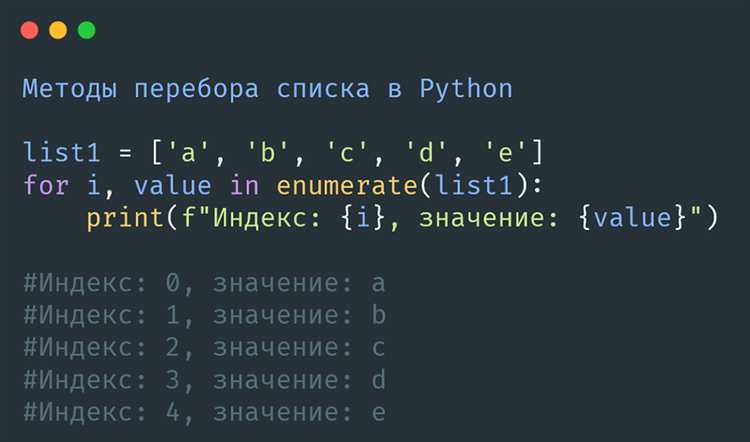
Работа со списками – одна из базовых задач в Python, и часто требуется удалить дубликаты, оставив только уникальные элементы. Эффективность этого процесса зависит от структуры данных, размера списка и требуемого порядка элементов.
Если порядок не важен, оптимальным решением будет использование структуры set. Преобразование списка в множество и обратно: unique_list = list(set(original_list)) – самый быстрый способ убрать повторения, но он не сохраняет порядок элементов.
Когда важно сохранить порядок, предпочтительнее использовать цикл с дополнительной структурой, например, set() для отслеживания уже добавленных значений: [x for x in original_list if not (x in seen or seen.add(x))], где seen = set(). Эта конструкция устраняет дубликаты без потери порядка и работает за линейное время.
Начиная с Python 3.7, встроенный dict сохраняет порядок добавления ключей. Это позволяет использовать: list(dict.fromkeys(original_list)) – лаконичное и читаемое решение с сохранением порядка и высокой скоростью выполнения.
При работе с вложенными структурами (списки внутри списков) или не-хешируемыми типами, такие как list или dict, подходы с использованием set не работают. В таких случаях необходимо сравнивать элементы вручную или использовать сериализацию, например, через json.dumps(), для приведения элементов к хешируемому виду.
Использование функции set() для удаления дубликатов
Функция set() преобразует список в множество, автоматически исключая все повторяющиеся элементы. Этот способ работает за время O(n), где n – количество элементов в исходном списке.
Пример:
список = [3, 1, 2, 3, 2, 4]
уникальные = list(set(список))
Результат: [1, 2, 3, 4] – порядок элементов может измениться, так как множество не сохраняет порядок. Чтобы сохранить порядок, комбинируйте set() с dict.fromkeys():
список = [3, 1, 2, 3, 2, 4]
уникальные = list(dict.fromkeys(список))
Результат: [3, 1, 2, 4] – дубликаты удалены, порядок сохранён.
Использование set() эффективно при работе с большими объемами данных, где не требуется сохранение порядка. Если важна последовательность, предпочтительнее dict.fromkeys().
Как сохранить порядок элементов при удалении повторений

При удалении дубликатов из списка важно не нарушить исходный порядок элементов. Для этого нельзя использовать множества напрямую, так как они не гарантируют порядок. Вместо этого следует применять структуры данных, сохраняющие порядок вставки.
- В Python 3.7+ стандартный
dictсохраняет порядок ключей. Это позволяет использовать словарь для фильтрации дубликатов. - Альтернатива – модуль
collections.OrderedDictдля совместимости с более ранними версиями Python.
def unique_preserve_order(seq):
return list(dict.fromkeys(seq))
Этот подход гарантирует:
- Удаление всех повторяющихся элементов.
- Сохранение первого вхождения каждого значения.
- Линейную сложность
O(n)по времени и памяти, гдеn– длина списка.
Пример:
данные = [4, 2, 4, 3, 2, 1]
результат = unique_preserve_order(данные)
# результат: [4, 2, 3, 1]
Не используйте цикл с проверкой if x not in result внутри for – это замедляет выполнение до O(n²) и непригодно для больших объёмов данных.
Если список содержит изменяемые объекты, например словари, используйте идентификаторы или сериализацию для определения уникальности, так как такие объекты не могут быть ключами словаря.
Удаление дубликатов с помощью цикла и условия
Чтобы удалить дубликаты из списка без использования встроенных структур, таких как set(), можно пройтись по элементам вручную и проверять, был ли элемент уже добавлен в результирующий список.
Реализация:
исходный_список = [1, 2, 2, 3, 4, 4, 5]
уникальные = []
for элемент in исходный_список:
if элемент not in уникальные:
уникальные.append(элемент)
Этот способ сохраняет порядок следования элементов. Проверка if элемент not in уникальные имеет линейную сложность, поэтому общая сложность алгоритма составляет O(n²), где n – количество элементов в исходном списке. Это допустимо для коротких списков, но неэффективно при больших объемах данных.
Оптимизация возможна через вспомогательное множество для хранения уже встреченных значений:
уникальные = []
встреченные = set()
for элемент in исходный_список:
if элемент not in встреченные:
уникальные.append(элемент)
встреченные.add(элемент)
Теперь проверка наличия элемента в встреченные выполняется за O(1), что снижает общую сложность до O(n) при сохранении порядка элементов.
Рекомендация: используйте второй вариант, если важна производительность и требуется сохранить порядок.
Применение библиотеки itertools для работы с уникальными значениями
Модуль itertools предоставляет эффективные итераторы, которые можно использовать для извлечения уникальных значений из последовательностей с учётом порядка и условия повторяемости.
- itertools.groupby() – группирует подряд идущие одинаковые элементы. Полезен только на отсортированных данных.
from itertools import groupby
data = ['a', 'a', 'b', 'b', 'c', 'a']
sorted_data = sorted(data)
unique = [key for key, _ in groupby(sorted_data)]
print(unique) # ['a', 'b', 'c']
Для корректной работы требуется предварительная сортировка, иначе повторяющиеся, но не подряд идущие элементы не будут сгруппированы.
- Комбинирование с map() и itemgetter позволяет выделять уникальные элементы по ключу в списке словарей.
from itertools import groupby
from operator import itemgetter
users = [
{'id': 1, 'name': 'Анна'},
{'id': 2, 'name': 'Иван'},
{'id': 1, 'name': 'Анна'}
]
users_sorted = sorted(users, key=itemgetter('id'))
unique_users = [next(g) for _, g in groupby(users_sorted, key=itemgetter('id'))]
print(unique_users)
Такой подход сохраняет первый встреченный элемент с уникальным ключом, устраняя дубликаты по определённому полю.
- Комбинации с set() неэффективны при необходимости сохранить порядок. Вместо этого используйте OrderedDict или groupby.
from itertools import groupby
data = [3, 1, 2, 3, 1, 4]
unique_ordered = []
for key, _ in groupby(sorted(data)):
unique_ordered.append(key)
print(unique_ordered) # [1, 2, 3, 4]
Если нужно сохранить исходный порядок без сортировки, используйте генератор и вспомогательный set:
def unique_everseen(iterable):
seen = set()
for item in iterable:
if item not in seen:
seen.add(item)
yield item
data = [3, 1, 2, 3, 1, 4]
print(list(unique_everseen(data))) # [3, 1, 2, 4]
Такой паттерн часто сочетается с itertools в потоковой обработке, особенно для больших объёмов данных.
Как использовать словари для удаления повторяющихся элементов
Словари в Python хранят пары ключ–значение, где каждый ключ уникален. Это свойство позволяет эффективно удалять дубликаты из списка, сохраняя порядок первых вхождений.
Для удаления повторов можно создать словарь, где элемент списка станет ключом, а значение – заглушкой, например None. Поскольку добавление ключа, который уже существует, не изменяет словарь, повторяющиеся элементы автоматически отбрасываются.
список = ['яблоко', 'банан', 'яблоко', 'вишня', 'банан']
уникальные = list(dict.fromkeys(список))
print(уникальные) # ['яблоко', 'банан', 'вишня']
Метод dict.fromkeys() создает словарь с ключами из исходного списка, не сохраняя повторы. Это решение быстрее, чем использование вложенных циклов или методов списка при больших объемах данных.
Если необходимо сохранить дополнительные сведения о каждом уникальном элементе (например, позиции или частоту), можно модифицировать словарь:
список = ['a', 'b', 'a', 'c', 'b']
позиции = {}
for индекс, элемент in enumerate(список):
if элемент not in позиции:
позиции[элемент] = индекс
print(позиции) # {'a': 0, 'b': 1, 'c': 3}
Этот подход позволяет одновременно устранить дубликаты и сохранить контекст появления уникальных значений.
Удаление дубликатов в списке строк с учётом регистра
В Python строки с разным регистром считаются различными, поэтому при удалении дубликатов важно сохранять различие между, например, «Пример» и «пример». Для этого нельзя использовать методы, игнорирующие регистр, такие как приведение к нижнему регистру.
Для точного удаления повторяющихся строк с учётом регистра рекомендуется использовать структуру данных set и цикл, сохраняющий порядок элементов. Это особенно актуально, если порядок элементов в списке важен:
def remove_duplicates_case_sensitive(strings):
seen = set()
result = []
for s in strings:
if s not in seen:
seen.add(s)
result.append(s)
return result
Этот подход исключает повторения без изменения исходного порядка и различает строки по регистру. Использование множества обеспечивает быстрые проверки на наличие элемента, а список сохраняет порядок добавления.
Пример использования:
input_list = ["Python", "python", "PYTHON", "Python"]
unique_list = remove_duplicates_case_sensitive(input_list)
print(unique_list) # ['Python', 'python', 'PYTHON']
Функция применима для любых строковых списков, где требуется точное соответствие символов с учётом регистра, включая логины, имена файлов или ключевые теги.
Удаление повторений в списке объектов с пользовательскими аттрибутами

Когда в Python необходимо удалить повторяющиеся объекты в списке, задача усложняется, если объекты содержат пользовательские атрибуты. По умолчанию Python не сравнивает объекты по их содержимому, а только по ссылке. Это значит, что даже если два объекта с одинаковыми аттрибутами, они будут рассматриваться как разные. Для решения этой задачи нужно явно указать, как сравнивать объекты.
Один из способов – переопределить метод __eq__ в классе объекта. Этот метод позволяет задать логику сравнения экземпляров, например, сравнивать их атрибуты. Кроме того, метод __hash__ должен быть также переопределен, чтобы объекты могли быть использованы в структурах данных, таких как множества или словари, где важно уникальность элементов.
Пример кода для переопределения методов:
class MyObject: def __init__(self, attribute): self.attribute = attribute def __eq__(self, other): return self.attribute == other.attribute def __hash__(self): return hash(self.attribute)
Теперь, создавая список объектов, можно легко удалить дубликаты с помощью преобразования его в множество. При этом объекты будут сравниваться по атрибутам, а не по ссылкам.
objects = [MyObject(1), MyObject(2), MyObject(1), MyObject(3)] unique_objects = list(set(objects))
Если нужно сохранить порядок элементов, можно использовать подход с фильтрацией через вспомогательное множество. Пример:
seen = set() unique_objects = [] for obj in objects: if obj not in seen: unique_objects.append(obj) seen.add(obj)
Этот метод гарантирует, что порядок объектов будет сохранен, при этом удалятся только дубликаты, основанные на пользовательских атрибутах.
Преимущества использования генераторов для удаления повторений
Генераторы в Python предоставляют эффективный и лаконичный способ удаления повторений из списка. В отличие от создания промежуточных коллекций, таких как множества или списки, генераторы позволяют работать с данными лениво, что снижает потребление памяти и улучшает производительность, особенно при обработке больших объемов данных.
Одним из ключевых преимуществ генераторов является то, что они не требуют полного хранения данных в памяти. Когда используется генератор, элементы обрабатываются по мере необходимости, что позволяет избежать дополнительной загрузки памяти, которая возникает при использовании обычных списков или других структур данных.
Для удаления повторений генераторы могут эффективно комбинировать итерации с проверкой на уникальность элементов. Вместо того чтобы предварительно создавать структуру данных для хранения уже встреченных значений, генератор делает это «на лету», проверяя каждое новое значение и пропуская повторяющиеся. Это особенно полезно при обработке больших потоков данных, где важна как экономия памяти, так и скорость выполнения.
Пример использования генератора для удаления повторений:
unique_items = (item for index, item in enumerate(input_list) if item not in input_list[:index])
Этот код позволяет итерировать по элементам списка, добавляя только уникальные элементы. Важно отметить, что использование генераторов позволяет избавиться от необходимости хранить дополнительные данные, такие как множество для проверки повторений, что делает решение более элегантным и экономным.
При работе с генераторами Python также автоматически оптимизирует выполнение кода, что делает их быстрыми и эффективными для обработки данных в реальном времени. Например, при обработке логов или чтении больших файлов с уникальными записями генератор обеспечит быстрый процесс удаления повторений без значительных затрат ресурсов.
Таким образом, использование генераторов для удаления повторений не только упрощает код, но и способствует повышению производительности программы, особенно при работе с большими объемами данных или в условиях ограниченных ресурсов.
Вопрос-ответ:
Как в Python сделать список уникальным, удалив повторяющиеся элементы?
Для того чтобы сделать список уникальным, можно воспользоваться функцией `set()`, которая автоматически удаляет все повторяющиеся элементы. Например, если у вас есть список: `my_list = [1, 2, 2, 3, 4, 4]`, то при применении `set(my_list)` получится `{1, 2, 3, 4}`. Однако стоит помнить, что результат будет типом данных `set`, который не сохраняет порядок элементов. Если нужно сохранить порядок, можно использовать другие подходы, например, с использованием цикла и проверки, встречался ли элемент ранее.





