

Для работы с текстовыми данными в Python часто требуется считывать строки из файлов или консоли. В случае, когда необходимо получить две отдельных строки, подход будет зависеть от того, откуда эти данные поступают. Рассмотрим основные способы и их особенности для эффективного чтения строк в Python.
Чтение строк с консоли – стандартный способ получения данных от пользователя. В Python для этого используется функция input(). Она позволяет получить одну строку и сохраняет её в переменной. Если задача заключается в считывании двух строк, можно вызвать input() дважды и сохранить каждую строку в отдельной переменной:
line1 = input("Введите первую строку: ")
line2 = input("Введите вторую строку: ")Этот способ прост и хорошо работает для интерактивных программ. Однако при большом объеме данных или необходимости автоматической обработки предпочтительнее использовать другие методы.
Чтение строк из файла – более распространенный метод для работы с данными. Для чтения двух строк из файла можно воспользоваться функцией readline(), которая возвращает одну строку за раз. Пример:
with open('example.txt', 'r') as file:
line1 = file.readline().strip()
line2 = file.readline().strip()Здесь readline() считывает строку, а метод strip() удаляет лишние символы перевода строки в конце строки. Этот способ удобен, когда строки необходимо читать поочередно из файла.
Чтение нескольких строк за один раз также может быть полезным, если нужно получить несколько строк в памяти для дальнейшей обработки. В таком случае используется метод readlines(), который возвращает список строк:
with open('example.txt', 'r') as file:
lines = file.readlines()
line1 = lines[0].strip()
line2 = lines[1].strip()Метод readlines() удобен, когда строки небольшие и количество данных ограничено. Однако при больших файлах его стоит использовать с осторожностью, так как он загружает все строки в память.
Как считать две строки с клавиатуры с помощью input()
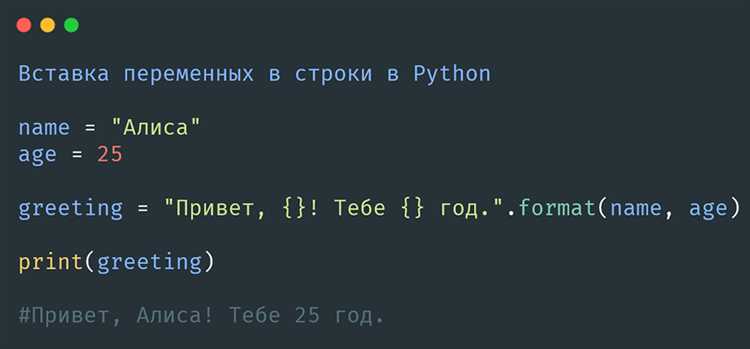
В Python для чтения данных с клавиатуры используется функция input(). Для считывания двух строк, необходимо вызвать input() дважды. Каждый вызов функции возвращает строку, введённую пользователем, и присваивает её переменной.
Пример простого кода для считывания двух строк:
str1 = input("Введите первую строку: ")
str2 = input("Введите вторую строку: ")
В данном примере пользователю будет предложено ввести две строки. После ввода каждая строка сохраняется в соответствующую переменную str1 и str2.
Если нужно обработать строки сразу после их ввода, можно использовать конструкцию, которая выполняет операцию сразу после ввода:
str1 = input("Введите первую строку: ").strip()
str2 = input("Введите вторую строку: ").strip()
Здесь метод strip() удаляет лишние пробелы с начала и конца строки. Это полезно, если важно работать только с содержимым без дополнительных пробелов.
Если необходимо одновременно считывать обе строки в одной строке кода, можно использовать распаковку кортежа:
str1, str2 = input("Введите две строки через пробел: ").split()
Этот способ позволяет разделить введённые данные по пробелу, но будьте внимательны: split() разделяет строку на части, и если пользователь введёт больше двух слов, возникнет ошибка. Чтобы избежать этого, можно заранее обработать ввод с проверкой на корректность:
try:
str1, str2 = input("Введите две строки через пробел: ").split()
except ValueError:
print("Ошибка: введите ровно две строки!")
Этот код гарантирует, что программа корректно обработает только два введённых значения, и при вводе большего или меньшего количества данных предупредит пользователя.
Чтение строк из файла и их обработка
В Python для работы с файлами используется встроенная функция open(), которая открывает файл и возвращает файловый объект. Чтобы прочитать строки из файла, применяют методы read(), readline() или readlines(). Каждый из этих методов подходит для разных сценариев обработки данных.
Если необходимо извлечь весь текст файла в одну строку, можно использовать read(). Этот метод возвращает содержимое файла в виде одной строки. Например:
with open('file.txt', 'r') as file:
content = file.read()
print(content)Метод readline() читает файл построчно, возвращая одну строку за раз. Его удобно использовать, если нужно обрабатывать строки по мере их чтения:
with open('file.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip()) # .strip() удаляет лишние пробелы
line = file.readline()Для чтения всех строк в файл и их последующей обработки часто используют метод readlines(). Он возвращает список строк, и каждый элемент этого списка является отдельной строкой из файла:
with open('file.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line.strip())Для обработки строк после их чтения полезно использовать цикл for с методом strip() для удаления лишних символов (например, символа новой строки). Это особенно важно при работе с большими текстовыми файлами, чтобы избежать ошибок при обработке данных.
Если требуется обработать только две конкретные строки, можно применить индексацию или методы seek() и tell() для точного позиционирования в файле. Например, чтобы получить первые две строки, можно использовать следующий код:
with open('file.txt', 'r') as file:
first_line = file.readline().strip()
second_line = file.readline().strip()
print(first_line, second_line)Когда файл содержит большие объемы данных, для повышения производительности имеет смысл использовать буферизацию. В этом случае можно открыть файл в бинарном режиме или применить метод iter() для чтения строк в цикле, что позволит работать с данными по частям.
Обработка ошибок при чтении также является важной частью работы с файлами. Например, если файл не существует или возникли проблемы с доступом, можно использовать конструкцию try-except, чтобы обработать исключения:
try:
with open('file.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")
except IOError:
Использование split() для разделения строк на элементы
Основной синтаксис:
строка.split(разделитель, макс_разделов)
разделитель – символ или строка, по которым будет выполнено разделение. Если не указан, по умолчанию используется пробел.макс_разделов – необязательный параметр, определяющий максимальное количество разделений. Если не указан, строка разделяется на все возможные части.
Примеры:
- Разделение строки по пробелам:
строка = "Привет мир"
результат = строка.split()
print(результат)
Результат: ['Привет', 'мир']
- Разделение строки по запятой:
строка = "яблоко,банан,киви"
результат = строка.split(',')
print(результат)
Результат: ['яблоко', 'банан', 'киви']
- Использование параметра
макс_разделов:
строка = "один два три четыре пять"
результат = строка.split(' ', 2)
print(результат)
Результат: ['один', 'два', 'три четыре пять']
Если разделитель не найден, метод вернет исходную строку в виде одного элемента списка:
строка = "Привет"
результат = строка.split(',')
print(результат)
Результат: ['Привет']
Для работы с несколькими пробелами в строке можно использовать split() без указания разделителя, что автоматически удалит лишние пробелы:
строка = "Привет мир"
результат = строка.split()
print(результат)
Результат: ['Привет', 'мир']
Метод split() часто используется для парсинга строк в текстах, обработке ввода пользователя и других задачах, где необходимо разбить строку на более мелкие части для дальнейшей обработки.
Прочтение строк с учетом их форматирования
Для работы с форматированием строк в Python важно понимать, как интерпретируются символы новой строки, пробелы и табуляции при чтении данных. Чтение строк с учетом их форматирования позволяет сохранить точную структуру текста, включая отступы и переносы строк, что может быть критически важно при обработке данных, таких как конфигурационные файлы или код.
Чтение строк с сохранением форматирования можно осуществить с помощью стандартной функции open(). При чтении файла построчно с использованием метода readlines() сохраняются все символы новой строки, включая отступы и пробелы в начале строки.
Пример:
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(repr(line)) # Используем repr для отображения всех символов
В данном примере символы новой строки будут видны, благодаря функции repr(). Этот метод полезен, если необходимо точно увидеть, как текст был прочитан, включая пробелы и переносы строк.
Удаление лишних пробелов можно осуществить с помощью метода strip(). Он удаляет ведущие и завершающие пробелы, включая символы новой строки, но оставляет форматирование внутри строки:
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line.strip()) # Убираем лишние пробелы в начале и конце строки
Если же требуется сохранить отступы в каждой строке, но убрать только лишние пробелы в начале строки, можно воспользоваться методом lstrip():
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line.lstrip()) # Убираем пробелы только в начале строки
Работа с текстом, содержащим табуляции, требует особого подхода. В некоторых случаях табуляция может быть важной для форматирования данных, например, при чтении отформатированных текстовых или CSV файлов. Для сохранения табуляций в строках необходимо учитывать, что стандартный метод readlines() сохраняет их как есть. Однако если требуется заменить табуляцию на пробелы, можно воспользоваться методом replace():
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line.replace('\t', ' ')) # Заменяем табуляции на 4 пробела
Таким образом, для работы с форматированием строк в Python важно правильно управлять символами новой строки, пробелами и табуляциями в зависимости от задачи. Учитывая особенности чтения данных, можно точно контролировать форматирование, что облегчает дальнейшую обработку текста.
Как обработать пустые строки при чтении данных
При чтении строк из файла или с ввода часто встречаются пустые строки. Если их не обработать, программа может работать некорректно или генерировать ошибки. Рассмотрим, как можно эффективно справляться с пустыми строками в Python.
1. Использование условных операторов для проверки строк
Когда строка не содержит символов (она пустая или состоит только из пробелов), можно пропустить её или обработать по особому сценарию. Для проверки строки на пустоту используется конструкция if not line.strip():, которая удаляет все пробелы и проверяет, является ли строка пустой.
Пример:
with open("data.txt", "r") as file:
for line in file:
if not line.strip():
continue # Пропускаем пустые строки
# Обработка непустой строки
2. Использование метода strip()
Метод strip() удаляет пробелы и символы новой строки с краёв строки. Это полезно для игнорирования строк, которые могут содержать только пробелы или табуляции, но при этом не являются пустыми по сути.
Пример:
line = input("Введите данные: ").strip()
if not line:
print("Введена пустая строка.")
else:
print(f"Введенные данные: {line}")
3. Обработка данных при чтении нескольких строк
Если необходимо считать несколько строк, и пустые строки могут быть частью ввода, лучше всего предусмотреть их обработку перед основной логикой работы с данными. Например, при чтении списка строк можно воспользоваться фильтрацией:
lines = [line.strip() for line in open("data.txt") if line.strip()]
# lines содержит только непустые строки
4. Сообщения об ошибках и обработка исключений
Иногда пустые строки могут быть причиной ошибок при обработке данных. В таких случаях важно не только проверять строку на пустоту, но и сообщать пользователю об ошибке или корректно обрабатывать её в рамках программы. Например:
line = input("Введите число: ").strip()
if not line.isdigit():
print("Ошибка: введена пустая строка или нечисловое значение.")
else:
print(f"Введенное число: {line}")
Таким образом, правильная обработка пустых строк помогает избежать ошибок и гарантирует, что программа будет работать корректно даже в случае, когда данные отсутствуют или представлены только пробелами.
Чтение строк с учетом пробелов в начале и конце
Когда программа на Python читает строку, стандартное поведение не учитывает пробелы в начале и в конце строки. Однако, иногда важно сохранить эти пробелы для корректной обработки данных. Рассмотрим, как можно читать строки с учетом пробелов.
Для чтения строки с сохранением пробелов в начале и в конце, можно использовать функцию input(). Важно понимать, что эта функция не удаляет пробелы, она просто считывает строку как есть. Пример:
user_input = input("Введите текст: ")
print(f"Считанная строка: '{user_input}'")
Если необходимо учитывать пробелы при считывании нескольких строк, можно организовать цикл для ввода данных. Например:
lines = []
for _ in range(2):
line = input("Введите строку: ")
lines.append(line)
print("Введенные строки:")
for line in lines:
print(f"'{line}'")
Чтобы избежать ошибок при дальнейшей обработке строк с пробелами, важно помнить, что input() сохраняет пробелы в строках. Если нужно убрать пробелы в начале и в конце, можно использовать метод strip(), но это уже будет отличаться от исходной задачи.
Для чтения строк с учетом пробелов важно точно понимать, когда они должны быть сохранены, а когда могут быть удалены, и корректно обрабатывать данные в зависимости от этого.
Чтение строк с использованием функции readline()
Функция readline() в Python используется для чтения одной строки из файла или потока. Она возвращает строку, считанную до символа новой строки, включая сам символ, если он присутствует. При каждом вызове функция продвигает указатель на следующую строку файла. Важно учитывать, что если в файле не осталось строк, readline() вернёт пустую строку.
Пример использования readline() для чтения двух строк:
with open('example.txt', 'r') as file:
line1 = file.readline()
line2 = file.readline()
Если файл содержит менее двух строк, то переменные line1 и line2 будут содержать строку и пустую строку соответственно. Этот способ удобен, если нужно точно контролировать процесс чтения строк, например, для обработки отдельных строк в файле.
Функция readline() полезна при работе с большими файлами, так как позволяет считывать данные построчно, не загружая весь файл в память. Однако она имеет один недостаток: если нужно читать все строки, вызовы readline() потребуют дополнительных операций с памятью и временем, по сравнению с методом readlines(), который сразу возвращает все строки в виде списка.
Рекомендуется всегда использовать конструкцию with при открытии файлов, чтобы обеспечить их автоматическое закрытие после завершения работы, независимо от того, возникли ли ошибки в процессе выполнения программы.
Использование try-except для обработки ошибок при чтении строк
При работе с пользовательским вводом в Python важно учитывать возможные ошибки, которые могут возникнуть. Один из эффективных способов обработки ошибок – использование блока try-except. Это позволяет избежать необработанных исключений, которые могут привести к сбою программы.
Если мы читаем строку с помощью функции input(), существует несколько типов ошибок, которые могут возникнуть, например, если пользователь вводит недопустимый символ или если при чтении данных возникают другие проблемы (например, потеря соединения с внешним источником). Чтобы предотвратить завершение программы из-за таких ошибок, можно обернуть код в блок try-except.
Пример простого использования:
try:
line1 = input("Введите первую строку: ")
line2 = input("Введите вторую строку: ")
except KeyboardInterrupt:
print("\nОшибка: Ввод был прерван пользователем.")
except EOFError:
print("\nОшибка: Достигнут конец ввода.")
except Exception as e:
print(f"Произошла ошибка: {e}")
В этом примере предусмотрены обработчики для стандартных ошибок: KeyboardInterrupt (прерывание ввода) и EOFError (достигнут конец ввода). Также используется универсальный обработчик исключений для любых других ошибок, которые могут возникнуть.
Если пользователь прервет процесс ввода с помощью Ctrl+C, программа выведет сообщение и продолжит выполнение, а не завершится с ошибкой. Важно помнить, что блок try-except следует использовать только для тех исключений, которые могут реально возникнуть, иначе код может скрыть важные проблемы.
Такой подход делает код более устойчивым и уменьшает вероятность непредсказуемого поведения программы при вводе данных.
Вопрос-ответ:
Как можно прочитать две строки из файла в Python?
В Python для чтения строк из файла можно использовать встроенную функцию `open()`, которая открывает файл для работы. Чтобы прочитать две строки, можно воспользоваться методом `readline()`, который возвращает одну строку за раз. Пример кода:
Можно ли прочитать несколько строк за один раз в Python?
Да, в Python можно читать несколько строк за один раз с помощью метода `readlines()`, который возвращает все строки файла в виде списка. Чтобы прочитать только две строки, можно указать нужное количество элементов в списке. Пример:
Что делать, если файл слишком большой и я хочу читать только две строки без загрузки всего содержимого в память?
Если файл большой, лучше избегать загрузки его целиком в память. Для этого можно использовать метод `readline()`, который читает строки одну за другой. Таким образом, память будет использоваться только для хранения двух строк, а не всего содержимого файла. Вот пример:
Какая разница между методами `readline()` и `readlines()` в Python?
Методы `readline()` и `readlines()` используются для чтения строк из файла, но между ними есть различия. Метод `readline()` читает только одну строку за раз и возвращает её как строку, включая символ новой строки (`\n`). Метод `readlines()`, в свою очередь, читает все строки из файла и возвращает их в виде списка строк. Каждый элемент списка будет строкой из файла, включая символ новой строки в конце. Например:
Как прочитать первую и вторую строки из файла без использования срезов в Python?
Если необходимо прочитать только первую и вторую строки, можно просто вызвать `readline()` дважды. Это позволит избежать использования срезов. Пример:





