Часто в программировании возникает задача обработки множества файлов в одной папке. В Python для этого существует несколько подходов, которые позволяют эффективно извлекать данные из файлов, используя стандартные библиотеки. Один из наиболее простых и удобных методов – использование модуля os или более современного pathlib. Эти инструменты позволяют не только читать файлы, но и управлять файловой системой, что делает их незаменимыми для автоматизации процессов.
Для начала рассмотрим, как с помощью модуля os прочитать все файлы в указанной директории. Функция os.listdir() возвращает список всех объектов (файлов и папок), находящихся в указанной папке. Чтобы обработать только файлы, необходимо дополнительно использовать проверку типа объекта с помощью os.path.isfile().
Альтернативный подход – использовать pathlib. Этот модуль был введён в Python 3.4 и предлагает более высокоуровневый интерфейс для работы с путями и файлами. Например, с помощью Path().glob() можно легко фильтровать файлы по расширению или имени. Главное преимущество pathlib – это возможность работать с путями в стиле операционной системы, независимо от того, используется ли Windows, Linux или macOS.
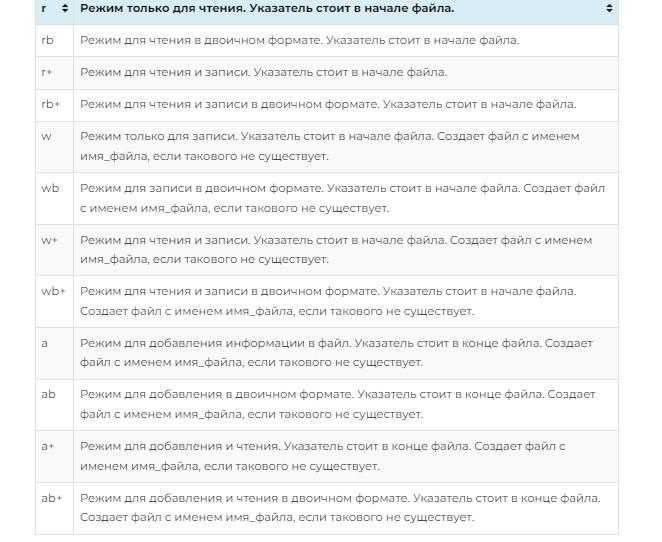
Важно отметить, что при работе с файлами стоит учитывать не только чтение данных, но и их корректное закрытие. Для этого идеально подойдёт использование with open(), что исключает возможность забыть закрыть файл после его обработки.
Получение списка файлов в директории с использованием os.listdir()
Функция os.listdir() позволяет получить список всех файлов и папок в указанной директории. Этот метод возвращает список строк, представляющих имена файлов и директорий, находящихся в указанной папке. С помощью os.listdir() можно легко получить доступ к содержимому любой папки на вашем компьютере.
Пример использования:
import os
путь_к_директории = '/путь/к/папке'
файлы = os.listdir(путь_к_директории)
print(файлы)В переменной файлы будет список всех элементов в папке, включая скрытые файлы (начинаются с точки). Для фильтрации только файлов, можно использовать дополнительные проверки.
Пример фильтрации только файлов:
import os
путь_к_директории = '/путь/к/папке'
файлы = [f for f in os.listdir(путь_к_директории) if os.path.isfile(os.path.join(путь_к_директории, f))]
print(файлы)Этот код создает список, включающий только файлы, исключая папки. os.path.isfile() проверяет, является ли элемент файлом.
Функция os.listdir() не сортирует элементы. Если требуется сортировка по имени, можно использовать встроенную функцию sorted().
Пример сортировки:
import os
путь_к_директории = '/путь/к/папке'
файлы = sorted(os.listdir(путь_к_директории))
print(файлы)В результате получится отсортированный по имени список файлов и директорий. Если необходимо сортировать по другой логике (например, по времени создания), придется использовать другие методы.
Фильтрация файлов по расширению с помощью pathlib
Чтобы фильтровать файлы по расширению, можно использовать метод Path.glob(), который поддерживает шаблоны для поиска файлов. Например, если нужно выбрать все текстовые файлы в каталоге, можно использовать следующий код:
from pathlib import Path
path = Path('/путь/к/папке')
text_files = path.glob('*.txt')
for file in text_files:
print(file)В этом примере glob('*.txt') ищет все файлы с расширением .txt в указанной папке. Шаблон может быть использован с другими расширениями, например, для поиска изображений можно использовать *.jpg.
Если нужно фильтровать файлы с несколькими расширениями, это можно сделать с помощью нескольких вызовов glob или использовать регулярные выражения. Для поиска файлов с расширениями .txt и .csv можно использовать такой код:
text_and_csv_files = path.glob('*.{txt,csv}')
for file in text_and_csv_files:
print(file)Таким образом, pathlib позволяет легко выбирать файлы по расширению с помощью удобных и гибких методов, которые позволяют точно и быстро фильтровать содержимое папок.
Чтение текстовых файлов с использованием open()
Пример открытия и чтения файла:
file = open('example.txt', 'r')
content = file.read()
file.close()В данном примере read() считывает весь текст в файл. Этот метод удобен для небольших файлов. Однако, если размер файла велик, лучше читать его построчно, чтобы избежать переполнения памяти.
Для построчного чтения можно использовать цикл с методом readline() или обрабатывать файл через контекстный менеджер. Например:
with open('example.txt', 'r') as file:
for line in file:
print(line.strip())В этом примере используется конструкция with, которая автоматически закрывает файл после завершения блока. Метод strip() удаляет лишние символы переноса строк, которые могут присутствовать в файле.
Если нужно прочитать все строки файла и сохранить их в список, можно использовать readlines():
with open('example.txt', 'r') as file:
lines = file.readlines()Этот метод возвращает список строк, где каждая строка – это элемент списка. Преимущество readlines() в том, что он сохраняет структуру файла, но также стоит помнить, что для больших файлов такой подход может быть неэффективным из-за потребности в памяти.
Важно помнить, что при работе с файлами всегда следует закрывать их, если не используется with, иначе могут возникнуть проблемы с доступом к файлу в будущем. С помощью with этот процесс автоматизируется.
Использование библиотеки os для обхода подкаталогов
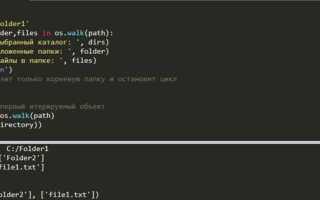
Функция os.walk() возвращает генератор, который создает кортежи, содержащие путь к текущей директории, список подкаталогов и список файлов. Это позволяет легко получить доступ ко всем файлам, независимо от глубины их вложенности.
Пример использования:
import os path = '/путь/к/директории' for dirpath, dirnames, filenames in os.walk(path): for filename in filenames: file_path = os.path.join(dirpath, filename) print(file_path)
В данном примере переменная dirpath будет содержать путь к текущему каталогу, dirnames – список подкаталогов, а filenames – список файлов в этом каталоге. Функция os.path.join() используется для корректного соединения путей.
Если необходимо обработать только файлы, то можно игнорировать подкаталоги, используя простой цикл по списку filenames.
Чтобы обрабатывать только файлы с определённым расширением, можно добавить проверку с помощью метода str.endswith(). Например, для обработки только текстовых файлов:
for dirpath, dirnames, filenames in os.walk(path):
for filename in filenames:
if filename.endswith('.txt'):
file_path = os.path.join(dirpath, filename)
print(file_path)
Также стоит помнить, что os.walk() обрабатывает все подкаталоги, включая скрытые (с точкой в начале имени), что может быть полезным или, наоборот, нежелательным, в зависимости от задачи. Для исключения скрытых каталогов можно отфильтровать их с помощью списка dirnames:
for dirpath, dirnames, filenames in os.walk(path):
dirnames[:] = [d for d in dirnames if not d.startswith('.')]
for filename in filenames:
file_path = os.path.join(dirpath, filename)
print(file_path)
Таким образом, использование os.walk() для обхода подкаталогов является удобным и эффективным методом работы с файловой системой в Python, предоставляя гибкость в обработке файлов и директорий различных типов.
Чтение данных из CSV-файлов с помощью модуля csv
Модуль csv в Python позволяет эффективно работать с данными в формате CSV. Для чтения файла достаточно использовать функцию csv.reader, которая считывает данные построчно. Пример кода для чтения CSV-файла:
import csv
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)В этом примере файл открывается с использованием контекстного менеджера with, что гарантирует закрытие файла после завершения работы. Опция newline='' необходима для корректного чтения файлов с разными символами новой строки.
Если CSV-файл имеет заголовки, то лучше использовать csv.DictReader, который позволяет читать строки как словари. Это упрощает работу с данными, так как каждый столбец можно обращаться по имени:
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
print(row['column_name'])Для обработки ошибок стоит использовать обработчик исключений. Например, если файл не существует, код может выбросить FileNotFoundError. Добавление обработки ошибок сделает программу более устойчивой:
try:
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)
except FileNotFoundError:
print("Файл не найден.") В случае необходимости пропустить строки с ошибками или пустые строки, можно добавить проверку перед их обработкой. Например:
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
if row: # пропустить пустые строки
print(row)Также для обработки больших файлов можно использовать дополнительные опции для чтения, такие как изменение разделителя с помощью параметра delimiter, если в файле используется не запятая, а другой символ:
with open('data.csv', mode='r', newline='', encoding='utf-8') as file:
reader = csv.reader(file, delimiter=';')
for row in reader:
print(row)Таким образом, модуль csv предоставляет простой и эффективный способ чтения данных из CSV-файлов, а дополнительные параметры позволяют гибко настроить процесс в зависимости от структуры данных.
Обработка ошибок при чтении файлов
При работе с файлами в Python важно предусмотреть возможные ошибки. Они могут возникать по разным причинам: неправильный путь к файлу, недостаточные права доступа, проблемы с кодировкой и другие. Чтобы избежать сбоев в работе программы, ошибки нужно обрабатывать правильно.
Основной механизм обработки ошибок в Python – это блоки try-except. Рассмотрим типичные ошибки и способы их обработки.
Типичные ошибки при чтении файлов
- FileNotFoundError – файл не найден по указанному пути.
- PermissionError – недостаточно прав для открытия файла.
- UnicodeDecodeError – ошибка при чтении файла с неверной кодировкой.
- IsADirectoryError – попытка открыть директорию как файл.
Рекомендации по обработке ошибок
- Используйте
try-exceptдля перехвата ошибок при работе с файлами. Это позволит избежать аварийного завершения программы и обеспечит возможность вывести понятное сообщение об ошибке. - Для уточнения типа ошибки укажите конкретное исключение в блоке
except. Например,except FileNotFoundError:позволяет точно обработать ошибку отсутствия файла. - Используйте блок
else, чтобы код выполнялся только в случае успешного открытия и чтения файла. Это предотвратит выполнение лишних операций при возникновении ошибок. - При необходимости откройте файл в режиме с корректной кодировкой, используя параметр
encoding. Пример:open('file.txt', 'r', encoding='utf-8').
Пример обработки ошибок
Пример чтения файла с обработкой типичных ошибок:
try:
with open('file.txt', 'r', encoding='utf-8') as f:
data = f.read()
except FileNotFoundError:
print("Файл не найден.")
except PermissionError:
print("Нет прав для доступа к файлу.")
except UnicodeDecodeError:
print("Ошибка кодировки файла.")
except IsADirectoryError:
print("Путь указывает на директорию, а не файл.")
else:
print("Файл успешно прочитан.")
Заключение

Правильная обработка ошибок при работе с файлами помогает повысить стабильность программы и сделать её более гибкой в условиях непредвиденных ситуаций. Регулярно проверяйте возможные ошибки и используйте соответствующие методы для их обработки.
Чтение бинарных файлов с использованием open() в режиме ‘rb’
Для работы с бинарными файлами в Python используется режим ‘rb’ при открытии файла через функцию open(). Этот режим указывает интерпретатору, что файл нужно читать в бинарном формате, а не как текстовый. Важно помнить, что в отличие от текстовых файлов, бинарные файлы содержат данные, которые могут быть представлены в любом формате – изображения, аудио, видео и другие.
Открытие файла в режиме ‘rb’ выглядит следующим образом:
file = open('путь_к_файлу', 'rb')
После этого файл можно читать с помощью методов read(), readline() или iter(). Основной метод для извлечения данных – read(). Он считывает заданное количество байтов или весь файл, если размер не ограничен. Например:
data = file.read(1024)
Этот код считывает первые 1024 байта файла. Если нужно считать весь файл, достаточно вызвать:
data = file.read()
Важно учитывать, что данные, полученные в бинарном формате, представляют собой последовательность байтов (тип данных bytes). Например, если файл содержит изображение в формате PNG, то данные, извлечённые из файла, будут представлены в виде байтового потока, который можно передавать в соответствующие библиотеки для обработки изображений.
Необходимо правильно закрывать файл после завершения работы с ним. Это можно сделать с использованием метода close() или через конструкцию with, которая автоматически закрывает файл:
with open('путь_к_файлу', 'rb') as file:
data = file.read()
Такой способ гарантирует, что файл будет закрыт даже в случае возникновения ошибки во время чтения данных.
При работе с большими файлами полезно использовать построчное чтение (с методом readline()) или читать файл порциями, например, с помощью цикла, чтобы избежать переполнения памяти:
with open('путь_к_файлу', 'rb') as file:
while chunk := file.read(1024):
# обработка порции данных
Чтение бинарных файлов в Python требует внимательности, особенно при работе с большим объёмом данных. Применение метода read() с ограничением на размер порции помогает эффективно управлять ресурсами и предотвращать излишнюю загрузку памяти.
Объединение данных из всех файлов в один с помощью Python
Для объединения данных из нескольких файлов в один в Python можно использовать несколько подходов в зависимости от типа данных и формата файлов. Рассмотрим процесс на примере текстовых файлов, а также CSV и JSON форматов.
Важнейшая задача – корректно обработать все файлы в папке, чтобы избежать ошибок при чтении. Для этого можно воспользоваться библиотеками os и glob, которые позволяют динамично искать файлы в директории.
1. Объединение текстовых файлов
Для объединения текстовых файлов можно открыть каждый файл и последовательно записать их содержимое в новый файл. Для этого используем стандартные средства Python:
import os
folder_path = 'path/to/folder'
output_file = 'merged.txt'
with open(output_file, 'w') as outfile:
for filename in os.listdir(folder_path):
if filename.endswith('.txt'):
with open(os.path.join(folder_path, filename), 'r') as infile:
outfile.write(infile.read() + '\n')
Этот код выполняет следующие действия:
- Проходит по всем файлам в указанной папке.
- Проверяет, что файл имеет расширение .txt.
- Читает данные из каждого файла и записывает их в новый файл с добавлением новой строки после каждого файла.
2. Объединение CSV файлов
Когда нужно объединить данные из нескольких CSV файлов, проще всего использовать библиотеку pandas, которая предоставляет мощные инструменты для работы с табличными данными:
import pandas as pd
import os
folder_path = 'path/to/folder'
output_file = 'merged.csv'
all_data = []
for filename in os.listdir(folder_path):
if filename.endswith('.csv'):
file_path = os.path.join(folder_path, filename)
data = pd.read_csv(file_path)
all_data.append(data)
merged_data = pd.concat(all_data, ignore_index=True)
merged_data.to_csv(output_file, index=False)
Что делает этот код:
- Читает каждый CSV файл в папке.
- Добавляет содержимое файла в список
all_data. - Объединяет все данные с помощью
pd.concat. - Сохраняет объединенные данные в новый CSV файл.
3. Объединение JSON файлов

Для работы с JSON файлами можно использовать стандартную библиотеку json. Объединение данных из нескольких JSON файлов аналогично предыдущим примерам:
import json
import os
folder_path = 'path/to/folder'
output_file = 'merged.json'
all_data = []
for filename in os.listdir(folder_path):
if filename.endswith('.json'):
file_path = os.path.join(folder_path, filename)
with open(file_path, 'r') as infile:
data = json.load(infile)
all_data.extend(data)
with open(output_file, 'w') as outfile:
json.dump(all_data, outfile, indent=4)
Что делает этот код:
- Загружает данные из каждого JSON файла в папке.
- Добавляет содержимое каждого файла в общий список
all_data. - Сохраняет объединенные данные в новый JSON файл.
Рекомендации
- Перед объединением данных всегда проверяйте формат файлов, чтобы избежать ошибок при чтении.
- Если файлы имеют разные структуры (например, разные колонки в CSV), используйте дополнительные проверки и трансформации данных перед объединением.
- Для больших файлов используйте подходы с обработкой данных по частям (например, читайте и записывайте данные блоками, а не все сразу в память).