Задача разбиения строки на отдельные слова является одной из базовых при работе с текстом в Python. Важно понимать, что в Python для этого существует несколько способов, каждый из которых имеет свои особенности и применимость в разных ситуациях. Одним из самых популярных и простых методов является использование метода split(), который делит строку по пробелам или любому другому разделителю.
Метод split() по умолчанию разделяет строку по пробелам, удаляя лишние пробелы в начале и в конце строки. Однако бывают случаи, когда требуется более сложная обработка, например, разделение по нескольким типам разделителей или сохранение некоторых символов, которые могут быть важными для анализа текста. Для таких случаев Python предоставляет регулярные выражения через модуль re, что дает дополнительную гибкость.
Когда нужно обрабатывать текст с учетом специальных символов или разделителей (например, запятых, точек или пробелов разных типов), рекомендуется использовать регулярные выражения. Модуль re позволяет задать более сложные шаблоны для разбиения строки, включая точную настройку на символы, которые будут разделителями.
Не менее важным аспектом является обработка строк с различными кодировками. Когда строки поступают из разных источников, важно заранее удостовериться в их правильной кодировке, чтобы избежать неожиданных ошибок при разбиении. Метод split() работает корректно с текстами в большинстве стандартных кодировок, однако в случаях с нестандартными наборами символов стоит использовать метод encode() для приведения строки к нужной кодировке.
Как разделить строку на слова с помощью метода split()

Основной синтаксис метода следующий:
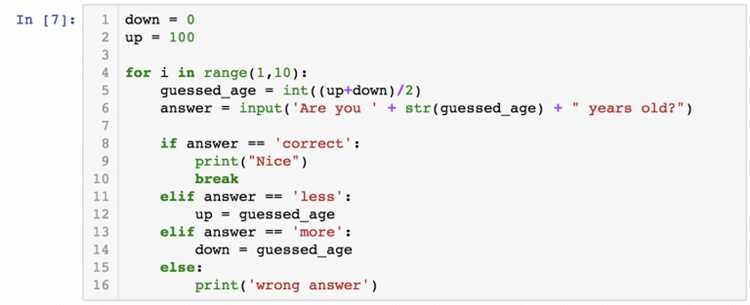
string.split(separator, maxsplit)- separator – разделитель, по которому строка будет разделена. Если не указан, используется пробел.
- maxsplit – максимальное количество разделений. Если не задано, будет разделена вся строка.
Примеры использования метода:
- Простой пример: Разделим строку по пробелу:
- Указание собственного разделителя: Разделим строку по запятой:
- Ограничение количества разделений: Разделим строку на два слова:
text = "Python это просто"
words = text.split()
print(words) # ['Python', 'это', 'просто']text = "яблоко,банан,груша"
words = text.split(',')
print(words) # ['яблоко', 'банан', 'груша']text = "один два три четыре"
words = text.split(' ', 2)
print(words) # ['один', 'два', 'три четыре']Некоторые важные моменты:
- Если строка состоит из нескольких пробелов подряд,
split()автоматически игнорирует их. Например, строка" python пример "будет разделена как['python', 'пример']. - Метод не изменяет исходную строку, а возвращает новый список слов.
- Если строка пуста, результатом будет пустой список:
'' .split() == [].
Метод split() является мощным инструментом для обработки текста и может быть настроен под различные задачи. Главное – правильно выбрать разделитель в зависимости от структуры данных в строке.
Использование регулярных выражений для разбиения строки
Для разбиения строки на слова с помощью регулярных выражений в Python используется модуль re. Это позволяет гибко обрабатывать текст, извлекая слова по сложным шаблонам, включая исключения или специфические разделители.
Для простого разбиения строки на слова с учетом различных разделителей (пробелов, табуляций, знаков препинания) можно использовать регулярное выражение, которое находит последовательности символов, состоящих только из букв и цифр. Пример:
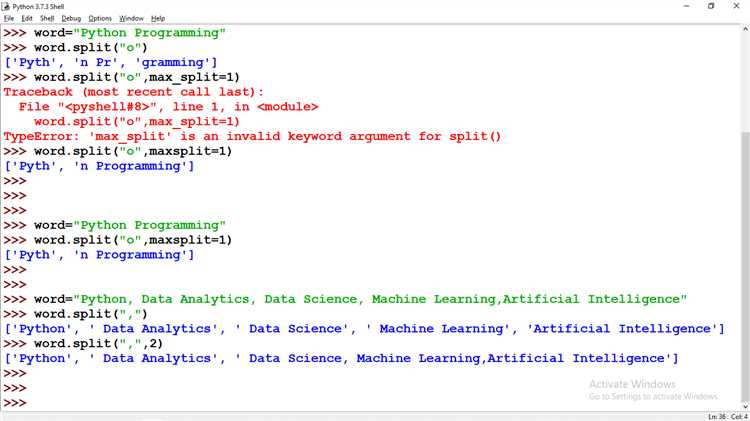
import re
text = "Пример текста, который нужно разбить!"
words = re.findall(r'\w+', text)
print(words)В этом примере регулярное выражение \w+ находит все последовательности, состоящие из букв, цифр и подчеркиваний. Это удобный способ для извлечения слов без учета знаков препинания.
Если необходимо разделить строку по определенному набору символов (например, пробелы и запятые), можно использовать следующий шаблон:
text = "Этот, пример, текста."
words = re.split(r'[ ,]+', text)
print(words)Здесь выражение [ ,]+ ищет один или более пробелов или запятых, что позволяет эффективно разбивать строку на слова. Символ + означает «один или более», что исключает пустые строки в результате.
Для более сложных случаев, например, при необходимости учитывать различные виды пробелов или другие разделители, можно использовать расширенные регулярные выражения. Важно помнить, что регулярные выражения являются мощным инструментом, но их использование должно быть обоснованным, чтобы не перегружать код излишней сложностью.
Обработка строк с несколькими пробелами при разбиении

Когда строка содержит несколько пробелов подряд, стандартные методы разбиения, такие как split(), могут не дать ожидаемых результатов. По умолчанию метод split() делит строку по любому пробельному символу, игнорируя лишние пробелы. Однако иногда требуется точнее контролировать, как обрабатываются несколько пробелов подряд.
Для правильной обработки лишних пробелов рекомендуется использовать параметр split() без аргументов. Этот подход автоматически удаляет пустые строки, возникающие из-за нескольких пробелов. Например:
text = "Это пример строки"
words = text.split()
print(words) # Выведет: ['Это', 'пример', 'строки']
Если необходимо оставить определённое количество пробелов между словами, можно воспользоваться регулярными выражениями с помощью модуля re. Метод re.split() позволяет настроить разделение строки с учётом нужных пробелов. Например, для разделения строки по одному или нескольким пробелам:
import re
text = "Это пример строки"
words = re.split(r'\s+', text)
print(words) # Выведет: ['Это', 'пример', 'строки']
В случае, когда нужно учитывать именно количество пробелов между словами (например, сохранить их для дальнейшего анализа), можно использовать такие подходы, как разделение строки на основе конкретного количества пробелов, что достигается с помощью регулярных выражений или применения метода split(' ') (для двух пробелов) или других аналогичных методов.
Таким образом, выбор метода зависит от задачи. Если нужно просто разделить строку по любому количеству пробелов и избавиться от лишних пробелов, лучше использовать split() без аргументов. В случае, если важно учитывать количество пробелов или требуются более сложные правила разбиения, стоит использовать re.split() с регулярными выражениями.
Разбиение строки по символам, отличным от пробела
Для разбиения строки на части, разделенные символами, отличными от пробела, можно использовать регулярные выражения. Это подход позволяет гибко контролировать процесс и учитывать различные символы-разделители, такие как знаки препинания, цифры или другие спецсимволы.
Основной инструмент для этой задачи – модуль re, предоставляющий мощные средства для работы с регулярными выражениями. Рассмотрим, как его можно использовать для разбиения строки по символам, отличным от пробела.
Пример: допустим, есть строка, содержащая текст, разделённый различными знаками, и нужно разбить её на слова, игнорируя пробелы и знаки препинания. Для этого можно воспользоваться регулярным выражением, которое будет искать все последовательности символов, отличных от пробела и других неалфавитных символов.
import re
text = "Привет, мир! Как дела?"
result = re.findall(r'\S+', text)
print(result)В данном примере регулярное выражение \S+ находит все последовательности символов, которые не являются пробелами. Это разбиение удобно, когда нужно получить чистые слова, игнорируя знаки препинания и другие разделители.
Если задача заключается в более сложном разбиении, например, исключая только определённые символы, можно уточнить регулярное выражение. Например, если нужно исключить только знаки препинания, можно использовать выражение r'[^ ,.!?]+’, которое будет искать все последовательности символов, не являющихся пробелом, запятой, точкой или восклицательным знаком.
result = re.findall(r'[^ ,.!?]+', text)
print(result)Регулярные выражения позволяют легко адаптировать разбиение под различные требования, такие как учёт специфических символов-разделителей или игнорирование различных типов пробелов. Использование re.findall даёт возможность быстро извлечь нужные элементы, значительно упрощая работу с текстом.
Для более сложных задач, например, если нужно учитывать символы нового абзаца или специальные символы в других кодировках, регулярные выражения можно дополнить соответствующими флагами или модификациями.
Как игнорировать пустые строки при разбиении
При разбиении строки на слова с помощью метода split(), пустые строки могут оказаться в результате, если исходная строка содержит лишние пробелы. Чтобы избежать этого, можно использовать несколько подходов.
Первый способ – это передать аргумент в метод split(). Если в качестве разделителя указать пробел, то последовательные пробелы приведут к появлению пустых элементов в списке. Чтобы избежать этого, можно воспользоваться аргументом None, который автоматически удаляет все пустые строки:
text = " Привет мир "
words = text.split() # результат: ['Привет', 'мир']Этот метод эффективно исключает все лишние пробелы, разделяя строку по любым пробелам, включая последовательности пробелов и табуляции.
Второй подход – использование регулярных выражений через модуль re. Это может быть полезно, если нужно более точно контролировать, как обрабатываются пробелы, например, игнорируя только те, что расположены в начале или в конце строки:
import re
text = " Привет мир "
words = re.findall(r'\S+', text) # результат: ['Привет', 'мир']Здесь \S+ находит все последовательности символов, не являющиеся пробелами, что позволяет исключить пустые строки и лишние пробелы.
При разбиении строки важно учитывать, что метод split() по умолчанию убирает лишние пробелы на концах строки, но в некоторых случаях использование регулярных выражений или дополнительных фильтров может дать лучший контроль над процессом.
Рекомендация: для большинства случаев достаточно использовать метод split() без аргументов. Однако если в данных присутствуют специфические разделители или требуется более сложная фильтрация, стоит обратиться к регулярным выражениям.
Преобразование строки в список слов с учетом знаков препинания
Один из простых способов – использовать регулярное выражение, которое будет захватывать как слова, так и знаки препинания отдельно. Например, для извлечения всех слов и знаков препинания можно применить следующее регулярное выражение: \w+|[^\w\s]. Это выражение ищет последовательности символов, состоящие из букв и цифр (\w+), а также любые символы, которые не являются словами или пробелами ([^\w\s]), включая знаки препинания.
Пример реализации:
import re
text = "Привет, мир! Как дела?"
result = re.findall(r'\w+|[^\w\s]', text)
print(result)Результатом работы этого кода будет список: ['Привет', ',', 'мир', '!', 'Как', 'дела', '?'], где каждый знак препинания сохраняется в отдельном элементе списка. Это позволяет точно контролировать разделение на слова, а также правильно обрабатывать знаки препинания, которые могут быть важными для дальнейшей обработки текста.
Если задача стоит в том, чтобы игнорировать знаки препинания, можно ограничиться использованием простого метода split(), который будет разделять строку по пробелам. Однако такой подход не даст точного разделения с учетом знаков препинания:
text = "Привет, мир! Как дела?"
result = text.split()
print(result)Результат: ['Привет,', 'мир!', 'Как', 'дела?']. В данном случае, знаки препинания остаются внутри слов, что может быть нежелательным в некоторых задачах обработки текста.
Для более точного разделения можно использовать дополнительные методы, такие как удаление знаков препинания с помощью re.sub(), чтобы оставить только слова. Например:
text = "Привет, мир! Как дела?"
text_clean = re.sub(r'[^\w\s]', '', text)
result = text_clean.split()
print(result)Результат: ['Привет', 'мир', 'Как', 'дела'], где знаки препинания были удалены, и слова разделены корректно.
Использование регулярных выражений – это мощный инструмент для более точной и гибкой обработки текста, особенно если нужно учитывать или исключать знаки препинания. Каждый конкретный случай требует выбора подходящего метода в зависимости от специфики задачи.
Разбиение строки на слова с учётом регистра
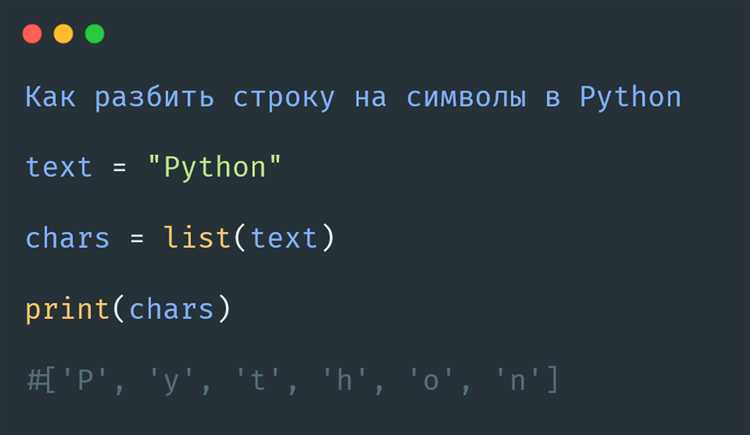
Когда требуется разделить строку на слова в Python, необходимо учитывать, как регистр символов влияет на разбиение. Например, строка «Python python» может быть интерпретирована по-разному в зависимости от того, какой подход применяется для учёта регистра.
Для простого разбиения строки на слова с учётом регистра можно воспользоваться методом split(). Этот метод разделяет строку по пробелам и сохраняет исходный регистр каждого слова. Например:
text = "Hello hello" words = text.split() print(words)
В результате получится список: ['Hello', 'hello'], где различие в регистре сохраняется.
Если же важно обработать строку, где различие в регистре играет роль, можно применить дополнительные функции для уточнения логики разделения. Например, использование регулярных выражений с учётом регистра может быть полезно для более сложных случаев, таких как выделение слов, начинающихся с заглавной буквы:
import re text = "Python python Java" words = re.findall(r'\b[A-Za-z]+\b', text) print(words)
Этот код найдет все слова, состоящие из букв латинского алфавита, с учётом их регистра. Результат: ['Python', 'python', 'Java'].
Для более сложных вариантов разбиения строки, например, для выделения слов в предложениях с разным форматом, можно использовать метод re.split(), который позволяет задать несколько разделителей. Например:
import re text = "Python, hello! Java?" words = re.split(r'\W+', text) print(words)
Здесь \W+ позволяет разделить строку по всем неалфавитным символам (запятые, пробелы, знаки препинания). Полученный результат: ['Python', 'hello', 'Java'].
Важно помнить, что при учёте регистра строка «Python» и «python» будут рассматриваться как разные слова. В случае, если нужно привести все слова к одному регистру перед разбиением, это можно сделать с помощью методов lower() или upper(), однако такой подход изменит исходный вид строк.