

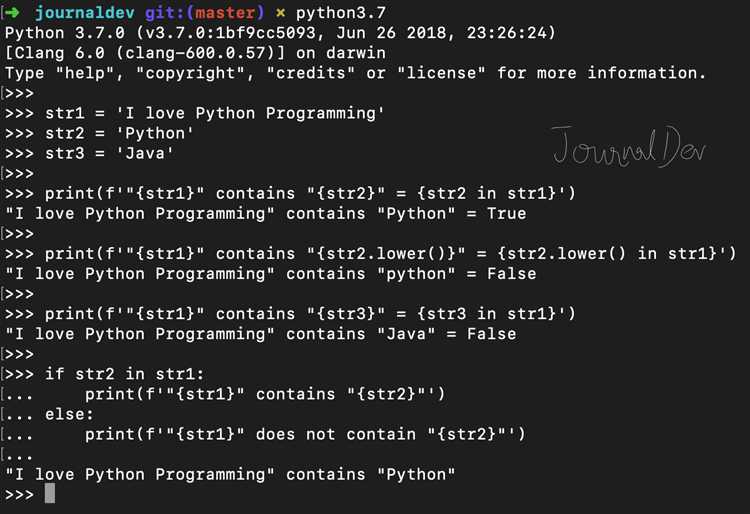
Поиск слова в строке – одна из самых частых операций при анализе текстовых данных. В Python эта задача может быть решена несколькими способами, каждый из которых имеет свои преимущества в зависимости от контекста. Например, метод in обеспечивает читаемость и лаконичность, но не позволяет выполнять регистронезависимый поиск без дополнительных преобразований.
Если требуется игнорировать регистр символов, стоит использовать str.lower() или str.casefold() перед сравнением. Второй вариант предпочтительнее для обработки текстов на разных языках, включая символы Юникода, так как обеспечивает более корректное приведение регистра, чем lower().
Для точного соответствия целому слову (а не его части) нужно учитывать границы слов. Здесь пригодятся регулярные выражения из модуля re. Выражение вида r’\bслово\b’ гарантирует, что совпадение произойдёт только при наличии полного слова, а не его части в составе другого слова.
Анализ большого количества строк требует внимания к производительности. При множественных проверках в списке слов следует рассмотреть использование set для ускорения поиска, а при работе с большими текстами – использование функций генераторов и библиотеки re.finditer() вместо re.findall(), чтобы избежать избыточного потребления памяти.
Как проверить наличие слова с учётом регистра
В Python для проверки наличия слова с учётом регистра применяется оператор in. Он возвращает True, если точное совпадение найдено, включая регистр символов.
Пример:
текст = "Пример строки с ключевым Словом"
слово = "Слово"
if слово in текст:
print("Слово найдено")Если требуется строгая проверка с учётом регистра, не используйте .lower() или .upper(), так как они нормализуют регистр. Вместо этого, убедитесь, что искомое слово соответствует точному написанию в тексте.
Также можно применять регулярные выражения с флагом re.NOFLAG (то есть без re.IGNORECASE), чтобы сохранить чувствительность к регистру:
import re
текст = "Пример строки с ключевым Словом"
шаблон = r"\bСлово\b"
if re.search(шаблон, текст):
print("Слово найдено")Для точного соответствия необходимо использовать границы слова \b, чтобы исключить частичные совпадения вроде «словообразование».
Итог: при проверке чувствительности к регистру не модифицируйте текст, избегайте флагов, игнорирующих регистр, и точно формулируйте шаблоны.
Как игнорировать регистр при проверке слова в строке

При проверке наличия слова в строке на Python важно учитывать, что стандартное сравнение строк чувствительно к регистру. Это означает, что слово «Python» не будет равно «python» или «PYTHON». Чтобы игнорировать регистр, можно преобразовать все строки в один формат перед сравнением. Для этого используется метод lower() или upper().
Пример с использованием lower():
строка = "Программирование на Python"
слово = "python"
если слово.lower() в строка.lower():
print("Слово найдено")
Метод lower() преобразует все символы строки в нижний регистр, что позволяет безопасно сравнивать строки независимо от их начального формата. Аналогично можно использовать метод upper(), который преобразует все символы в верхний регистр.
Для поиска слова в строке, игнорируя регистр, также можно использовать регулярные выражения. Для этого применяют флаг re.IGNORECASE. Например:
import re
строка = "Программирование на Python"
слово = "python"
если re.search(слово, строка, re.IGNORECASE):
print("Слово найдено")
Использование регулярных выражений может быть полезным, если необходимо искать не только конкретное слово, но и более сложные паттерны. Этот способ эффективен, когда нужно игнорировать регистр и учитывать более гибкие условия поиска.
Еще один способ – это использование метода casefold(), который является более универсальным и подходит для сравнения строк на разных языках. casefold() делает строку нечувствительной к регистру и более устойчивой к различным символам (например, буквы с диакритическими знаками). Пример:
строка = "Программирование на Python"
слово = "python"
если слово.casefold() в строка.casefold():
print("Слово найдено")
Метод casefold() рекомендуется использовать, если нужно работать с текстами, содержащими символы других языков, так как он предлагает более широкий подход по сравнению с lower() или upper().
Проверка точного совпадения слова без частичных вхождений
Для проверки точного совпадения слова в строке на Python важно использовать методы, которые исключают частичные вхождения, такие как проверка наличия подстроки. В стандартной библиотеке Python есть несколько вариантов для реализации этой задачи, с которыми следует ознакомиться для достижения наиболее точного результата.
Первый и один из самых прямых способов – использование метода re.match() из модуля re (регулярные выражения). Этот метод позволяет искать точные совпадения с учетом начала строки. Например, выражение re.match(r'\bслово\b', строка) будет искать точное слово «слово» в строке, избегая частичных совпадений вроде «словообразование» или «словарь». Регулярное выражение \b указывает на границу слова, что и гарантирует точность совпадения.
Другим способом является использование метода split(), который делит строку на слова и проверяет наличие точного совпадения. В этом случае код будет выглядеть так:
words = строка.split() if "слово" in words:
Этот метод эффективен, если нужно просто проверить наличие слова среди других слов в строке. Однако стоит учитывать, что он не будет работать корректно, если слово встречается внутри другого слова, например, в «словообразовании». Для таких случаев лучше использовать регулярные выражения.
Если важно, чтобы слово было на определенной позиции в строке, можно воспользоваться методом startswith() или endswith(). Эти методы позволяют проверить, начинается или заканчивается ли строка на нужное слово. Для примера:
if строка.startswith("слово"):
print("Строка начинается с 'слово'")
Метод startswith() будет полезен, если требуется точно проверить первое слово в строке, исключая случайные вхождения в середине текста.
При использовании этих методов важно помнить о возможных пробелах и знаках препинания, которые могут искажать результат. Для точности можно использовать методы предварительной обработки строки, такие как strip() для удаления лишних пробелов или re.sub() для замены знаков препинания перед поиском.
Использование регулярных выражений для поиска слова
Регулярные выражения (regex) в Python – мощный инструмент для поиска и манипуляции строками. Для поиска конкретного слова в строке регулярные выражения позволяют создавать гибкие и эффективные запросы, которые могут учитывать различные вариации текста.
Основной модуль для работы с регулярными выражениями в Python – это re. С его помощью можно быстро искать слова в строках, даже если они имеют разные формы или окружены другими символами.
Простейшая форма поиска слова с использованием регулярного выражения:
import re
text = "Это пример строки, в которой мы ищем слово."
pattern = r"\bслово\b"
result = re.search(pattern, text)
if result:
print("Слово найдено!")
else:
print("Слово не найдено.") В данном примере используется конструкция \b, которая обозначает границу слова. Это важно, чтобы избежать частичных совпадений, например, с «словообразование».
Регулярные выражения могут быть настроены для поиска с учётом разных условий:
re.IGNORECASE– поиск без учёта регистра;re.findall()– для нахождения всех совпадений;re.sub()– для замены найденных слов;\w+– для поиска любых буквенно-цифровых слов;\s+– для работы с пробелами и другими разделителями.
Пример поиска всех вхождений слова «слово» в строке с учётом регистра:
import re
text = "Слово в строке, слово в другом месте."
pattern = r"\bслово\b"
result = re.findall(pattern, text, flags=re.IGNORECASE)
print(result) # ['Слово', 'слово'] При необходимости, можно использовать более сложные паттерны для поиска слов с различными окончаниями или внутри других символов. Например, регулярное выражение \bслово\w*\b найдет все слова, начинающиеся с «слово», включая их вариации, такие как «словосочетание».
Для работы с большими текстами или строками, содержащими множество вариантов слова, регулярные выражения обеспечивают значительное ускорение поиска по сравнению с простыми методами, такими как использование in.
Однако важно помнить, что регулярные выражения могут быть сложными для восприятия и требуют внимательности при составлении паттернов. Необходимо точно понимать, какие символы используются для создания границ и сопоставлений, чтобы избежать неожиданных результатов.
Поиск слова в списке строк
Для поиска слова в списке строк в Python чаще всего используется цикл и метод in. Рассмотрим, как можно эффективно выполнять такой поиск.
Предположим, у нас есть список строк, и нужно проверить наличие конкретного слова в этих строках. Один из способов – это перебрать каждую строку в списке и применить оператор in для поиска слова.
strings = ["Привет, мир", "Как дела?", "Python – это здорово"]
word = "Python"
for string in strings:
if word in string:
print(f'Слово "{word}" найдено в строке: "{string}"')
- Использование генераторов: Генераторы позволяют создавать более компактный и быстрый код, не создавая лишних списков.
found = (string for string in strings if word in string)
for match in found:
print(f'Слово "{word}" найдено в строке: "{match}"')
- Поиск с учетом регистра: Если необходимо искать слово без учёта регистра, можно привести все строки к одному регистру с помощью метода
lower().
word = "python"
for string in strings:
if word.lower() in string.lower():
print(f'Слово "{word}" найдено в строке: "{string}"')
Этот подход удобен для случаев, когда нужно учитывать слова, состоящие из разных регистров.
- Использование регулярных выражений: Если поиск должен быть более гибким (например, учитывать слова с вариациями или шаблоны), можно воспользоваться модулем
re.
import re
pattern = re.compile(r'\b' + re.escape(word) + r'\b', re.IGNORECASE)
for string in strings:
if pattern.search(string):
print(f'Слово "{word}" найдено в строке: "{string}"')
Метод с регулярными выражениями предоставляет возможность искать слово как целое, игнорируя его части, что полезно для сложных запросов.
Для более быстрого поиска в случае больших наборов данных можно рассмотреть использование структур данных, таких как множества или словари, которые обеспечат более быстрый доступ к элементам, но это требует другой структуры хранения данных.
Что делать, если строка содержит пунктуацию или спецсимволы

Когда строка содержит пунктуацию или спецсимволы, задача поиска слова в ней усложняется. Спецсимволы могут быть не видны на первый взгляд или даже игнорироваться при стандартных методах поиска. Для решения этой проблемы стоит учитывать несколько подходов.
Первое, что нужно сделать – это очистить строку от ненужных символов, если это возможно. В Python для этого удобно использовать регулярные выражения с модулем re. Например, для удаления всех пунктуационных знаков и пробелов можно использовать следующий код:
import re
text = "Привет, мир!"
cleaned_text = re.sub(r'[^\w\s]', '', text) # Удаляет все символы, кроме букв и пробелов
Этот подход полезен, когда важно оставить только слова, без учета символов, таких как запятые, точки или кавычки.
Если же нужно учитывать пунктуацию и спецсимволы в процессе поиска, можно использовать другой метод. Например, при помощи регулярных выражений искать слово с учетом всех символов, включая спецсимволы, можно так:
pattern = r'Привет,?'
result = re.search(pattern, text)
if result:
print("Слово найдено!")
else:
print("Слово не найдено.")
Таким образом, регулярные выражения позволяют гибко настроить поиск и адаптировать его под конкретные требования задачи.
Если нужно искать точное совпадение с учетом всех символов, то можно воспользоваться стандартным методом in, но с предварительной очисткой строки от пробелов и спецсимволов. Важно помнить, что для поиска слов без учета регистра стоит использовать метод lower():
text = "Привет, мир!"
word = "привет"
if word.lower() in text.lower():
print("Слово найдено.")
else:
print("Слово не найдено.")
Этот способ удобен, если точность поиска важнее, чем наличие символов, отделяющих слова в строке.
Вопрос-ответ:
Как проверить наличие слова в строке на Python?
Для проверки наличия слова в строке на Python можно использовать оператор `in`. Например, если нужно узнать, содержится ли слово "Python" в строке `text`, можно написать так: `if "Python" in text:`. Это вернёт `True`, если слово найдено, и `False`, если нет.
Какие способы проверки наличия слова в строке существуют на Python?
Кроме использования оператора `in`, можно применить метод строки `find()`, который возвращает индекс первого вхождения подстроки в строку или `-1`, если подстрока не найдена. Например: `text.find("Python")`. Также можно использовать метод `index()`, который работает аналогично, но выбрасывает исключение, если подстрока не найдена: `text.index("Python")`.





