Метод split() в Python используется для разбиения строки на части по заданному разделителю. Возвращаемое значение – список строк. Если не указать аргумент, строка разбивается по пробелам, включая символы табуляции и перевода строки. Метод не изменяет исходную строку, так как строки в Python неизменяемы.
Типичный вызов выглядит так: строка.split(разделитель, макс_разбиений). Второй аргумент – необязателен. Он ограничивает количество разбиений, после которых остаток строки сохраняется как последний элемент списка. Это особенно полезно при обработке логов, CSV без кавычек и структурированных текстов, где важен контроль количества элементов.
Метод split() не подходит для сложных случаев разбиения, например, с множественными символами-разделителями или шаблонами. Для таких задач рекомендуется использовать re.split() из модуля re. Однако в большинстве прикладных случаев split() остаётся простым и эффективным решением.
Как разделить строку по пробелу с помощью split()

Метод split() без аргументов разделяет строку по одному или нескольким пробелам. Последовательности пробелов автоматически считаются одним разделителем, а начальные и конечные пробелы игнорируются.
Пример:
текст = " Python split метод "
результат = текст.split()
print(результат)['Python', 'split', 'метод']Если необходимо сохранить пустые элементы, нужно явно указать разделитель – одиночный пробел:
текст = "один два три"
результат = текст.split(" ")
print(результат)Результат включает пустые строки между словами:
['один', '', 'два', '', '', 'три']Рекомендуется использовать split() без параметров, если не требуется фиксированный шаблон пробелов. Это особенно удобно при обработке пользовательского ввода или анализа текстов с непредсказуемым количеством пробелов.
Как использовать split() с пользовательским разделителем

Метод split() позволяет указать любой разделитель в виде строки. Это особенно полезно, когда данные имеют нестандартный формат, например, CSV с нестандартным разделителем или журналы с метками времени.
- Разделение по символу:
'a-b-c'.split('-')вернёт['a', 'b', 'c']. - Разделение по нескольким символам:
'2024::05::07'.split('::')→['2024', '05', '07']. - Случай, когда разделитель в начале или в конце:
'--item--'.split('--')даст['', 'item', ''].
Если указанный разделитель не найден, результат – список с одной строкой:
'example'.split('|')→['example']
Для разбора строк с пробелами и дополнительными символами можно использовать цепочку методов:
' a | b | c '.strip().split('|')→['a ', ' b ', ' c']- Для удаления пробелов по краям каждого элемента:
[s.strip() for s in ' a | b | c '.split('|')]
Если необходимо ограничить количество разбиений, используйте второй аргумент:
'a,b,c,d'.split(',', 2)→['a', 'b', 'c,d']
Не используйте split() с регулярными выражениями – он принимает только строку. Для более сложных схем разбиения используйте re.split() из модуля re.
Что произойдёт, если вызвать split() без аргументов
Метод split() без параметров разбивает строку по последовательностям пробельных символов: пробелам, табуляциям, переводам строк и другим, определяемым как whitespace в Unicode. При этом последовательные пробелы считаются одним разделителем, а начальные и конечные пробелы игнорируются.
Пример:
text = " Python is awesome\nand versatile\t!"
result = text.split()
print(result)
Результат:
['Python', 'is', 'awesome', 'and', 'versatile', '!']
Никаких пустых строк в списке не появляется, даже если между словами несколько пробелов. Это поведение выгодно при анализе текста, где точное количество пробелов не имеет значения.
Важно: split() без аргументов нельзя использовать для разделения по конкретному символу, например, запятой. В таких случаях необходимо явно указать разделитель: split(',').
Если строка состоит только из пробельных символов, результатом будет пустой список:
" \t\n ".split() # []
Для строк с единственным словом без пробелов метод вернёт список с этим словом:
"Python".split() # ['Python']
Рекомендуется использовать split() без параметров в задачах нормализации текста, когда нужно быстро разбить строку на слова без учёта лишних пробелов и символов переноса строки.
Как split() работает с несколькими подряд идущими разделителями

Метод split() по умолчанию разбивает строку по пробелам и удаляет все подряд идущие пробельные символы, включая табуляции и переводы строк. Например:
text = "один два\t\tтри\n\nчетыре"
result = text.split()
# ['один', 'два', 'три', 'четыре']
Если передан конкретный разделитель, например пробел (' '), split() не игнорирует повторяющиеся символы и вставляет пустые строки между ними:
text = "один два три"
result = text.split(' ')
# ['один', '', 'два', '', '', '', 'три']
Чтобы избавиться от лишних пустых строк, используйте фильтрацию:
parts = list(filter(None, text.split(' ')))
# ['один', 'два', 'три']
Для разделителей, отличных от пробела, поведение аналогичное. Пример с запятыми:
text = "яблоко,,груша,,,банан"
result = text.split(',')
# ['яблоко', '', 'груша', '', '', 'банан']
Для удаления пустых значений полезно использовать генераторное выражение:
[x for x in text.split(',') if x]
# ['яблоко', 'груша', 'банан']
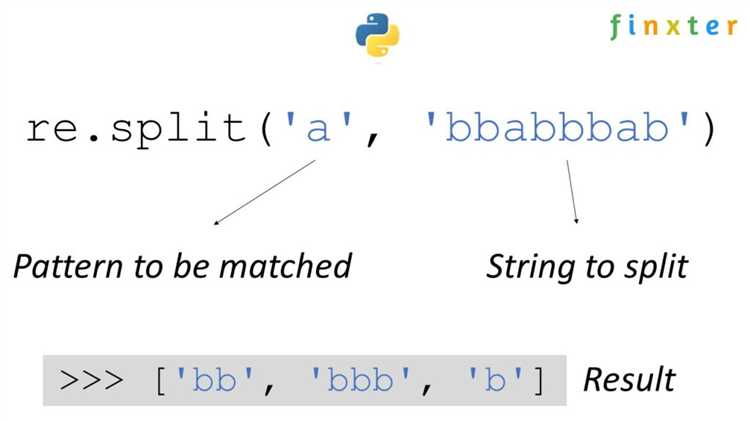
Если требуется разбивать по множеству разных символов, используйте re.split() из модуля re:
import re
text = "один;два,,три::четыре"
result = re.split(r'[;,:]+', text)
# ['один', 'два', 'три', 'четыре']
Ограничение количества разбиений с помощью второго аргумента split()

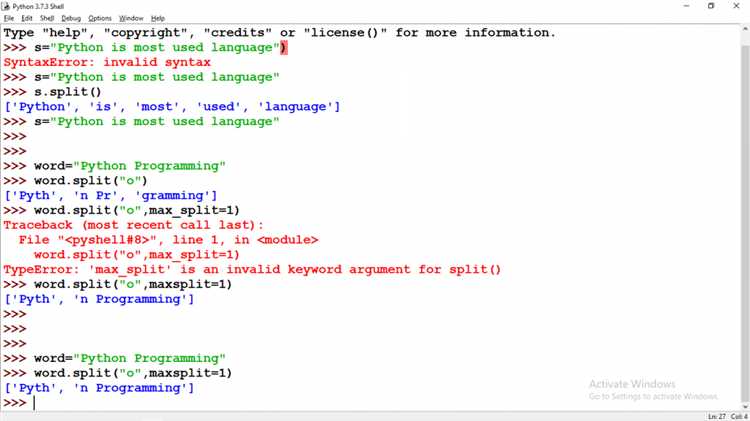
Метод split() принимает второй необязательный аргумент – maxsplit, который задаёт максимальное количество разбиений. После достижения этого количества остаток строки возвращается как последний элемент списка.
Пример: 'a,b,c,d'.split(',', 2) вернёт ['a', 'b', 'c,d']. Первыми двумя разделителями строка разбивается, остальная часть сохраняется без изменений.
Если указать maxsplit=0, результатом будет список с одним элементом – исходной строкой, даже если в ней присутствуют разделители.
Это полезно, когда важно сохранить часть строки в неизменном виде, например, при разборе логов: 'INFO 2025-05-07 Some message'.split(' ', 2) даёт ['INFO', '2025-05-07', 'Some message'].
Значение maxsplit должно быть неотрицательным целым числом. Если оно превышает фактическое количество возможных разбиений, метод ведёт себя как без ограничений.
Разбор типичных ошибок при использовании split() и способы их избежать
Еще одной распространенной проблемой является неправильная обработка пустых строк. Когда метод split() применяется к пустой строке, он возвращает пустой список, а не список с одним пустым элементом. Это может стать неожиданным в случае, когда предполагается, что список будет содержать хотя бы один элемент. Чтобы избежать таких ситуаций, всегда учитывайте возможность пустых строк в данных и обрабатывайте их заранее, проверяя, является ли строка пустой перед вызовом метода.
Некорректная работа с ограничением количества разделений (параметр maxsplit) также является частой ошибкой. Если значение maxsplit указано, то метод ограничит количество разбиений, и в результате могут остаться лишние данные в последнем элементе списка. Чтобы избежать этого, всегда внимательно рассчитывайте, сколько раз вам нужно выполнить разделение, и учитывайте, что остаток строки после достижения лимита будет содержать все остальные элементы.
Кроме того, при использовании split() с разделителями, которые являются многосимвольными строками, важно помнить, что метод будет делить строку только на точные вхождения разделителя. Ошибки могут возникать, если разделитель не совпадает с ожидаемым (например, пробел в конце строки или случайное изменение символа). В таких случаях следует использовать регулярные выражения через метод re.split(), который позволяет более гибко управлять разделителями.
Использование split() на строках с Unicode-символами или с символами разных кодировок может привести к некорректным результатам, если кодировка строки не была правильно определена. Важно всегда проверять и задавать кодировку при чтении данных, особенно если строки содержат специальные символы. В случае работы с различными кодировками рекомендуется использовать модуль chardet для определения кодировки или явно указывать ее при открытии файлов.
![Использование undefinedsplit()</code> на строках с Unicode-символами или с символами разных кодировок может привести к некорректным результатам, если кодировка строки не была правильно определена. Важно всегда проверять и задавать кодировку при чтении данных, особенно если строки содержат специальные символы. В случае работы с различными кодировками рекомендуется использовать модуль <code>chardet</code> для определения кодировки или явно указывать ее при открытии файлов.»></p>
<h2>Вопрос-ответ:</h2>
<h4>Что такое метод split в Python?</h4>
<p>Метод `split` в Python используется для разделения строки на подстроки. Он возвращает список, в котором элементы — это части исходной строки, разделённые по определённому символу или по пробелу по умолчанию. Этот метод можно применять для удобного извлечения данных из строки.</p>
<h4>Как работает метод split, если не указать разделитель?</h4>
<p>Если при вызове метода `split` не указать разделитель, то строка будет разделена по пробелам. При этом несколько пробелов подряд будут восприниматься как один разделитель, а лишние пробелы в начале и в конце строки будут проигнорированы.</p>
<h4>Можно ли использовать метод split с несколькими разделителями?</h4>
<p>Метод `split` по умолчанию не поддерживает несколько разделителей. Однако, если необходимо использовать несколько символов для разделения, можно применить регулярные выражения с модулем `re`. Например, с помощью функции `re.split` можно указать несколько символов для разделения строки.</p>
<h4>Какие аргументы принимает метод split в Python?</h4>
<p>Метод `split` принимает два аргумента: разделитель и максимальное количество разделений. Разделитель указывается для того, чтобы определить, по какому символу или подстроке будет происходить разделение. Если разделитель не указан, по умолчанию используется пробел. Аргумент `maxsplit` определяет, сколько раз будет выполнено разделение. Если `maxsplit` не указан, строка разделяется на максимальное количество частей.</p>
<h4>Приведите пример использования метода split с максимальным числом разделений.</h4>
<p>Допустим, у нас есть строка `»apple orange banana kiwi»`. Если мы вызовем метод `split(‘ ‘, 2)`, результатом будет список `[‘apple’, ‘orange’, ‘banana kiwi’]`. Здесь строка разделена на три части, при этом максимальное количество разделений — два. Оставшиеся слова оказываются в последнем элементе списка.</p>
<h4>Как работает метод split() в Python?</h4>
<p>Метод split() в Python используется для разделения строки на части, используя разделитель. По умолчанию разделителем является пробел. Метод возвращает список подстрок, которые образуются после разделения исходной строки. Например, строка `»яблоко банан апельсин».split()` вернет список: `[‘яблоко’, ‘банан’, ‘апельсин’]`. Если вы хотите использовать другой разделитель, нужно передать его в качестве аргумента метода. Например, `»яблоко,банан,апельсин».split(«,»)` вернет список: `[‘яблоко’, ‘банан’, ‘апельсин’]`.</p>
<!-- CONTENT END 1 -->
</div>
</article>
<div class=](/wp-content/images4/kak-rabotaet-split-python-12xmu0h2.jpg)
 (пока оценок нет)
(пока оценок нет)