Работа с XML-файлами в Python может быть необходимостью при обработке данных из различных источников, таких как веб-сервисы, конфигурационные файлы или данные, полученные из старых систем. Понимание того, как эффективно парсить XML в Python, помогает автоматизировать процессы и значительно ускоряет анализ данных.
Для разбора XML в Python существует несколько инструментов, но самым популярным и простым в использовании является модуль xml.etree.ElementTree, который входит в стандартную библиотеку. Этот модуль предоставляет необходимые функции для загрузки, поиска и манипуляции данными в XML-документе. С помощью нескольких строк кода можно загрузить файл и извлечь нужные элементы.
Основные этапы парсинга XML файла включают: чтение файла с помощью функции ElementTree.parse(), навигацию по дереву элементов с использованием методов поиска, таких как find() и findall(), а также извлечение данных из атрибутов или текстовых узлов. Важно понимать, как работать с именованными пространствами, если XML использует их, и учитывать особенности работы с большими файлами, чтобы не исчерпать память.
Для того чтобы эффективно работать с XML в Python, важно следовать нескольким простым рекомендациям:
- Используйте ElementTree для стандартных операций с небольшими файлами.
- Для работы с большими XML-файлами используйте iterparse(), чтобы читать данные по частям.
- При необходимости обработки XML в более сложных форматах, таких как с именованными пространствами, ознакомьтесь с использованием lxml.
Как установить необходимые библиотеки для работы с XML в Python
1. xml.etree.ElementTree – встроенная библиотека Python. Она не требует установки, так как является частью стандартной библиотеки Python. Для работы с XML достаточно импортировать её с помощью:
import xml.etree.ElementTree as ET
Эта библиотека подходит для большинства задач, но имеет ограниченные возможности по сравнению с более мощными альтернативами.
2. lxml – более производительная и функциональная библиотека для работы с XML и HTML. Она поддерживает XPath и XSLT, что делает её идеальным выбором для сложных задач. Чтобы установить `lxml`, используйте команду:
pip install lxml
Перед установкой убедитесь, что у вас есть компилятор C, так как библиотека требует его для сборки. Если у вас возникнут проблемы с установкой на Windows, можно использовать предварительно скомпилированные колеса (wheels), скачав их с официального сайта или с ресурса Gohlke Python libs.
3. minidom – библиотека, также входящая в стандартную библиотеку Python, но её возможности несколько ограничены. Для использования достаточно выполнить импорт:
from xml.dom import minidom
Она более проста в использовании для небольших файлов и задач, где не требуются сложные операции с XML-деревом.
Для большинства случаев, если вам не нужны сложные операции с данными или высокая производительность, достаточно использовать стандартную библиотеку `xml.etree.ElementTree`. Однако для более сложных и требовательных приложений рекомендуется установить `lxml`.
Как загрузить и открыть XML файл для парсинга
Для начала работы с XML файлом необходимо его загрузить и открыть. В Python для этого часто используется встроенная библиотека `xml.etree.ElementTree`. Она позволяет легко загружать XML данные как из файлов, так и из строковых представлений.
Чтобы открыть XML файл, используйте функцию `ElementTree.parse()`, которая принимает путь к файлу и возвращает объект дерева. Пример загрузки файла:
import xml.etree.ElementTree as ET
tree = ET.parse('file.xml')
root = tree.getroot()
Здесь `file.xml` – путь к XML файлу, а метод `getroot()` позволяет получить корневой элемент XML документа.
Если XML файл содержится в строковом формате, его можно загрузить с помощью функции `ET.fromstring()`. Например:
xml_data = '''- 1
- 2
После загрузки файла или строки важно убедиться в правильности структуры XML. Если файл повреждён или имеет неверный формат, `ElementTree` выбросит исключение, которое можно обработать с помощью конструкции `try-except`.
try:
tree = ET.parse('file.xml')
except ET.ParseError as e:
print(f"Ошибка парсинга: {e}")
Для работы с XML файлами на диске не забудьте указать правильный путь к файлу. Если файл находится в другом каталоге, используйте абсолютный или относительный путь к нему.
Как извлечь данные из XML с помощью библиотеки ElementTree
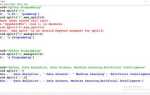
Библиотека ElementTree в Python предоставляет удобный способ для работы с XML-документами. Она позволяет парсить XML, искать нужные элементы и извлекать данные из них. Рассмотрим, как извлекать информацию из XML с помощью ElementTree на примере простого документа.
Для начала необходимо импортировать библиотеку и загрузить XML-документ. Самый простой способ – использовать функцию ET.parse(), которая принимает путь к файлу и возвращает объект дерева, с которым можно работать.
import xml.etree.ElementTree as ET
tree = ET.parse('file.xml')
root = tree.getroot()Теперь у вас есть объект root, который представляет корневой элемент XML. Все дальнейшие действия будут происходить относительно этого объекта.
Чтобы извлечь данные, можно использовать методы поиска элементов. Например, метод find() находит первый подходящий элемент, а findall() – все подходящие элементы.
element = root.find('название_тега')
elements = root.findall('название_тега')Метод find() возвращает первый найденный элемент, в то время как findall() возвращает список всех элементов с указанным тегом. Если элемент не найден, find() вернёт None, а findall() – пустой список.
Чтобы извлечь данные из элемента, можно обратиться к его атрибутам или тексту. Атрибуты элементов хранятся в словаре, к которому можно обратиться с помощью метода attrib. Текстовое содержимое элемента можно получить с помощью свойства text.
text = element.text
attribute = element.attrib['атрибут']Если элемент содержит вложенные теги, их можно извлечь, используя методы find() или findall() для каждого уровня вложенности.
Для работы с атрибутами важно помнить, что если атрибут не существует, возникнет ошибка. Чтобы избежать этого, можно использовать метод get(), который возвращает значение атрибута или None, если атрибут отсутствует.
attribute = element.get('атрибут')При необходимости извлечения данных из сложных или крупных XML-файлов стоит учитывать производительность. Библиотека ElementTree позволяет эффективно обходить элементы с помощью методов поиска и не требует загрузки всего документа в память, что важно при работе с большими файлами.
Как работать с аттрибутами и тегами в XML файле
При работе с XML-файлами важно научиться извлекать и манипулировать как текстовыми данными внутри тегов, так и значениями атрибутов. В Python для этого чаще всего используется библиотека ElementTree, которая предоставляет удобные методы для парсинга и навигации по XML-структуре.
Рассмотрим, как работать с тегами и аттрибутами, используя ElementTree для этих целей.
Чтение и доступ к тегам
Чтобы получить доступ к тегам, необходимо сначала загрузить XML-файл с помощью метода ElementTree.parse(), а затем получить корневой элемент с помощью getroot().
import xml.etree.ElementTree as ET
tree = ET.parse('example.xml')
root = tree.getroot()
Теперь, чтобы извлечь данные из тегов, можно использовать методы, такие как find() и findall().
find(tag)– возвращает первый элемент с указанным тегом, если он существует, илиNone, если такого тега нет.findall(tag)– возвращает список всех элементов с указанным тегом.
Пример извлечения значений тегов:
# Поиск первого элемента с тегом 'item'
item = root.find('item')
if item is not None:
print(item.text)
Работа с аттрибутами
Атрибуты в XML элементах можно получить через словарь, используя метод attrib.
# Доступ к аттрибутам тега 'item'
item = root.find('item')
if item is not None:
print(item.attrib['id']) # Доступ к аттрибуту 'id'
Если аттрибут отсутствует, будет вызвано исключение KeyError. Чтобы избежать этого, можно использовать метод get(), который возвращает None, если аттрибут не найден:
# Безопасный доступ к аттрибуту
item_id = item.attrib.get('id', 'default_value') # 'default_value', если аттрибут отсутствует
Поиск элементов по аттрибутам

Можно также искать элементы с определёнными значениями аттрибутов, используя метод findall() в сочетании с условием поиска.
# Поиск всех элементов с аттрибутом 'id' равным '123'
items = root.findall(".//item[@id='123']")
for item in items:
print(item.text)
Здесь используется выражение XPath, которое позволяет эффективно фильтровать элементы по значению аттрибута.
Изменение значений тегов и аттрибутов
Если нужно изменить значения тегов или аттрибутов, это можно сделать напрямую через объект элемента:
# Изменение текста в теге 'item'
item = root.find('item')
if item is not None:
item.text = 'Новое значение'
# Изменение аттрибута 'id'
item.attrib['id'] = '456'
После изменения необходимо сохранить изменения в XML-файл с помощью метода tree.write():
tree.write('modified_example.xml')
Удаление тегов и аттрибутов
Для удаления тегов используется метод remove():
# Удаление элемента 'item' root.remove(item)
Чтобы удалить аттрибут, можно воспользоваться методом del:
# Удаление аттрибута 'id' del item.attrib['id']
Такое удаление изменяет исходный объект в памяти, но не записывает изменения в файл до явного вызова tree.write().
Рекомендации
- Используйте безопасные методы, такие как
get(), чтобы избежать ошибок при отсутствии аттрибутов. - Для фильтрации элементов по аттрибутам всегда используйте XPath-выражения, чтобы ускорить поиск.
- Не забывайте сохранять изменения после редактирования XML, чтобы обновления вступили в силу.
Как использовать XPath для выборки данных из XML
XPath позволяет извлекать данные из XML-документов с использованием выражений, которые указывают на конкретные элементы или атрибуты. Этот инструмент очень полезен, когда необходимо работать с большими или сложными XML-структурами. В Python для работы с XPath используется библиотека lxml, которая поддерживает полный спектр возможностей XPath.
Основной синтаксис XPath включает в себя пути, которые могут быть абсолютными (начинающимися с корня) или относительными. Пример абсолютного пути: /root/element, где /root – это корень документа, а /element – элемент внутри корня. Относительный путь, например, //element, позволяет искать элементы на любом уровне документа.
Для использования XPath в Python необходимо сначала импортировать модуль lxml.etree. Вот пример кода для извлечения данных из XML:
from lxml import etree
# Пример XML
xml = '''
Python Basics
John Doe
Advanced Python
Jane Smith
'''
# Парсим XML
tree = etree.fromstring(xml)
# Используем XPath для выборки названий книг
titles = tree.xpath('//book/title/text()')
print(titles) # Выведет: ['Python Basics', 'Advanced Python']
Для выбора данных из атрибутов, можно использовать синтаксис @атрибут. Например, если у элемента есть атрибут id, XPath запрос будет выглядеть так: //element[@id="123"].
XPath поддерживает разнообразные операторы для фильтрации данных. Например, and и or позволяют комбинировать условия, а text() – фильтровать элементы по их текстовому содержимому. Для поиска всех элементов с текстом "Python Basics" можно использовать такой запрос: //title[text()="Python Basics"].
Важно помнить, что XPath выражения чувствительны к регистру. Таким образом, //title и //Title будут обозначать разные элементы. Также стоит учитывать, что в случае поиска по атрибутам и тексту не учитываются пробелы в начале и конце строк, что делает выборку более точной.
Для более сложных запросов можно использовать функции XPath, такие как contains() для поиска подстрок или position() для выбора элементов по порядку. Например, для выбора второго book элемента из документа используйте запрос: //book[position()=2].
Использование XPath в Python с библиотекой lxml даёт гибкость и высокую производительность при работе с XML данными, что особенно полезно при обработке больших файлов или необходимости выполнения сложных фильтраций.
Как обработать ошибки при парсинге XML файла
При парсинге XML файлов с помощью Python могут возникать различные ошибки. Чтобы эффективно их обработать, важно использовать правильные инструменты и подходы для диагностики и устранения проблем. Рассмотрим основные способы работы с ошибками в процессе парсинга.
Python предоставляет несколько библиотек для работы с XML, таких как xml.etree.ElementTree, lxml, и minidom. Все они могут генерировать ошибки, которые нужно перехватывать и обрабатывать.
1. Использование блоков try-except
Для обработки ошибок при парсинге используйте блоки try-except. Это позволяет поймать ошибки, возникающие при разборе XML, и вывести полезную информацию о проблеме.
try:
tree = ET.parse('file.xml')
root = tree.getroot()
except ET.ParseError as e:
print(f"Ошибка при парсинге XML: {e}")
except FileNotFoundError:
print("Файл не найден.")
В этом примере ET.ParseError ловит ошибки, связанные с некорректным XML, а FileNotFoundError – проблемы с доступом к файлу.
2. Проверка на корректность структуры XML
Перед тем как начинать разбор XML, можно проверить его структуру с помощью внешних инструментов, например, с помощью DTD или схемы XML (XSD). Но для быстрого анализа в Python используйте встроенные проверки.
- Для проверки синтаксиса файла используйте
lxml.etree.XMLSchema, который может быть использован для валидации XML-документа по схеме. - При парсинге с помощью
xml.etree.ElementTree, если файл некорректен, будет сгенерировано исключениеParseError, которое следует обрабатывать.
3. Логирование ошибок

Для улучшения диагностики и отслеживания ошибок используйте логирование. Это особенно полезно для больших файлов или автоматических систем, где важно отслеживать не только ошибки, но и предупреждения.
import logging
import xml.etree.ElementTree as ET
logging.basicConfig(filename='parser_errors.log', level=logging.ERROR)
try:
tree = ET.parse('file.xml')
except ET.ParseError as e:
logging.error(f"Ошибка парсинга: {e}")
С помощью модуля logging можно записывать ошибки в лог-файл, что поможет позже проанализировать возможные проблемы и улучшить обработку ошибок.
4. Использование альтернативных библиотек для более строгой проверки
Если стандартные библиотеки Python не обеспечивают достаточной гибкости, рассмотрите использование библиотеки lxml, которая поддерживает более строгие проверки и может быть полезна для обработки больших XML файлов или сложных структур.
- Библиотека
lxmlпредоставляет методlxml.etree.XMLParser, который позволяет настроить более детализированную обработку ошибок. - Также можно использовать функцию
lxml.etree.fromstring, которая позволяет передать параметрrecover=True, чтобы игнорировать некоторые ошибки в XML и продолжить разбор.
5. Проверка кодировки
Некорректная кодировка может стать причиной ошибок при парсинге XML. Убедитесь, что файл имеет правильную кодировку, и при необходимости укажите её при чтении файла.
with open('file.xml', encoding='utf-8') as f:
tree = ET.parse(f)
Если кодировка файла неизвестна или может быть изменена, используйте параметр encoding для явного указания кодировки при открытии файла.
6. Ожидание ошибок и возврат на предыдущие шаги
Иногда ошибка при парсинге может быть связана с неполным или поврежденным файлом. В таких случаях полезно сделать несколько попыток парсинга, обрабатывая ошибки и пытаясь исправить их, например, удалив или заменив поврежденные строки.
Для реализации таких методов можно использовать цикл с ограничением на количество попыток парсинга. Это уменьшит риск падений программы из-за случайных или временных ошибок в файле.
Вопрос-ответ:
Что такое XML в контексте парсинга?
XML (Extensible Markup Language) — это формат разметки, используемый для хранения и передачи данных. В отличие от HTML, XML не ограничивает структуру данных, предоставляя возможность создавать теги по своему усмотрению. При парсинге XML в Python важнейшей задачей является извлечение данных из элементов и атрибутов XML документа. Это возможно с помощью различных библиотек, таких как `xml.etree.ElementTree`, `lxml` или `BeautifulSoup`. Важно понимать, что парсинг XML позволяет работать с данными в структурированном виде, что облегчает их анализ и обработку.