Распознавание объектов на изображениях – одна из ключевых задач компьютерного зрения. С помощью Python можно быстро и эффективно использовать существующие библиотеки и инструменты для разработки таких решений. Важнейшими инструментами для решения этой задачи являются библиотеки, такие как OpenCV, TensorFlow и PyTorch, которые предоставляют необходимые функции для обработки изображений и работы с нейронными сетями.
Первым шагом является предобработка данных: изображения должны быть приведены к единому размеру, нормализованы и часто преобразованы в оттенки серого для упрощения задачи. Для дальнейшей работы используется конволюционные нейронные сети (CNN), которые показывают отличные результаты при распознавании объектов. Например, с помощью библиотеки TensorFlow можно легко создать модель для классификации объектов на изображениях, обучив её на большом наборе данных.
Для начала работы с изображениями в Python стоит ознакомиться с библиотеками OpenCV и Pillow, которые предоставляют удобные инструменты для загрузки, изменения и отображения изображений. Используя OpenCV, можно реализовать не только распознавание объектов, но и обработку изображений в реальном времени, что полезно для таких приложений, как видеонаблюдение или робототехника.
Для эффективного распознавания объектов необходимо использовать готовые модели, такие как YOLO или Mask R-CNN, которые предоставляют высокую точность и скорость. Эти модели можно загрузить и применить с минимальными усилиями, что делает их идеальными для большинства практических задач.
Подготовка данных для распознавания объектов
Для успешного распознавания объектов на изображениях необходимо правильно подготовить данные. Этот этап критичен, поскольку качество данных напрямую влияет на точность работы моделей машинного обучения. Рассмотрим ключевые шаги подготовки данных.
1. Сбор данных – на первом этапе важно собрать достаточное количество изображений с разнообразными объектами, которые будут распознаваться. Важно, чтобы изображения содержали различные углы, освещение, масштаб и фоны. Если собираются данные для специфической задачи, например, распознавания автомобилей, изображения должны включать разные модели, цвета и условия съемки.
2. Разметка данных – каждое изображение должно быть размечено, то есть указано, какие объекты на нем присутствуют и где они находятся. Для этого обычно используют координаты ограничивающих рамок (bounding boxes). Такие инструменты, как LabelImg или RectLabel, могут помочь в ручной разметке изображений. На этапе разметки важно быть внимательным, чтобы не ошибиться в позиционировании рамок, так как это сильно влияет на обучение модели.
3. Аугментация данных – чтобы повысить разнообразие обучающих данных и уменьшить переобучение модели, применяют аугментацию. Это может включать случайные повороты, изменения масштаба, отражения или добавление шумов. Для этого в Python используют библиотеки, такие как Albumentations или TensorFlow Image API. Аугментация данных помогает создать более универсальную модель, способную распознавать объекты в разных условиях.
4. Нормализация и стандартизация – изображения, перед тем как поступить в модель, часто требуют нормализации. Это позволяет привести значения пикселей в определенный диапазон (обычно от 0 до 1 или от -1 до 1), что ускоряет обучение и повышает стабильность работы модели. В большинстве случаев используется простая нормализация, где значения пикселей делятся на 255, чтобы привести их к диапазону от 0 до 1.
5. Разделение данных на тренировочные, валидационные и тестовые наборы – правильное разделение данных является важной частью подготовки. Обычно данные делятся в пропорции 70/15/15, где 70% – это тренировка, 15% – валидация, 15% – тестирование. Важно, чтобы распределение было случайным и охватывало все классы объектов, чтобы избежать перекоса в обучении.
6. Балансировка данных – если один класс объектов сильно преобладает над другими, модель может быть смещена в сторону более частого класса. Для решения этой проблемы применяют методы балансировки, такие как генерация дополнительных данных для редких классов или использование взвешенных потерь при обучении.
После выполнения этих шагов данные будут готовы для передачи в модель машинного обучения. Подготовка данных требует внимательности и тщательности, поскольку ошибки на этом этапе могут существенно снизить качество конечного результата.
Использование библиотеки OpenCV для обработки изображений
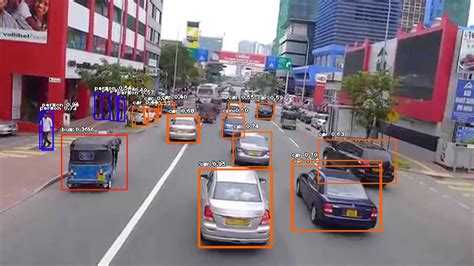
Для начала работы с OpenCV необходимо установить саму библиотеку. Это можно сделать через pip:
pip install opencv-pythonПосле установки библиотеку можно импортировать в проект:
import cv2Основные возможности OpenCV включают:
- Чтение и запись изображений: с помощью функции
cv2.imread()можно загрузить изображение, аcv2.imwrite()– сохранить обработанный файл. - Геометрические преобразования: такие как изменение размера, поворот и обрезка с помощью функций
cv2.resize(),cv2.rotate()иcv2.crop(). - Фильтрация изображений: применение различных фильтров, таких как размытие или детектирование краев, например, с помощью
cv2.GaussianBlur()илиcv2.Canny(). - Распознавание объектов: в OpenCV есть инструменты для поиска лиц, автомобилей, текстов и других объектов на изображениях с использованием каскадных классификаторов или сверточных нейронных сетей.
Пример простого кода для чтения изображения и его отображения:
image = cv2.imread('image.jpg')
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()Для работы с цветами OpenCV использует модель BGR (синий, зеленый, красный), а не RGB, что важно учитывать при манипуляциях с изображениями. Например, чтобы перевести изображение в оттенки серого, можно использовать:
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)Для обнаружения краев в изображении используется метод Канни. Пример:
edges = cv2.Canny(gray_image, 100, 200)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()Для распознавания объектов часто используют предварительно обученные классификаторы, такие как каскад Хаара для детектирования лиц. Вот пример использования классификатора для нахождения лиц:
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
faces = face_cascade.detectMultiScale(gray_image, 1.1, 4)
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow('Detected Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()OpenCV активно используется в реальных приложениях для распознавания объектов, видеонаблюдения и медицинской визуализации. Для сложных задач рекомендуется интегрировать OpenCV с библиотеками глубокого обучения, такими как TensorFlow или PyTorch, чтобы улучшить точность распознавания.
Основное преимущество OpenCV – это оптимизация под работу с большими объемами данных и высокая скорость обработки изображений, что делает ее незаменимой в задачах реального времени, таких как распознавание лиц или анализ видео.
Обучение нейросети для классификации объектов на изображениях
Обучение нейросети для классификации объектов на изображениях начинается с подготовки данных. Важно, чтобы набор данных был разнообразным и включал изображения, соответствующие всем категориям, которые требуется распознать. Для улучшения точности нейросети рекомендуется использовать такие подходы, как увеличение данных (data augmentation), что включает в себя методы, как повороты, масштабирование, зеркалирование и изменение яркости изображений. Это помогает нейросети быть более устойчивой к различным условиям, в которых может быть сделано изображение.
После подготовки данных, следующим шагом является выбор архитектуры нейросети. Наиболее популярными для задач классификации изображений являются сверточные нейросети (CNN). Эти сети эффективны благодаря своей способности выделять важные особенности на изображениях, такие как края, текстуры и формы. В качестве основы часто используется архитектура, например, ResNet, VGG или Inception, которые уже продемонстрировали хорошие результаты в области компьютерного зрения.
После выбора архитектуры необходимо настроить параметры обучения. Одним из важнейших факторов является выбор функции потерь. Для задач классификации на изображениях часто используется кросс-энтропийная функция потерь. Она хорошо подходит для многоклассовых задач, так как учитывает вероятность принадлежности объекта к каждому из классов.
Также важным моментом является выбор оптимизатора. Наиболее популярными являются Adam и SGD (стохастический градиентный спуск). Adam часто дает лучшие результаты в задачах классификации изображений благодаря адаптивной корректировке скорости обучения для каждого параметра модели. Важно следить за динамикой изменения функции потерь и точности на обучающей и валидационной выборках, чтобы избежать переобучения модели.
Во время обучения следует регулярно проверять модель на валидационных данных, чтобы корректировать гиперпараметры и предотвращать переобучение. Один из эффективных методов борьбы с переобучением – это использование регуляризации, например, dropout, который случайным образом отключает некоторые нейроны во время тренировки, чтобы модель не зависела от конкретных признаков.
После завершения обучения важно протестировать модель на тестовых данных, которые она не видела ранее. Этот этап позволяет убедиться, что нейросеть обобщает информацию, а не запоминает лишь конкретные данные. На основе результатов тестирования можно решать, нужно ли дообучение модели или ее оптимизация для улучшения точности классификации.
Применение моделей на базе TensorFlow или PyTorch для распознавания объектов
Модели глубокого обучения, такие как те, что основаны на TensorFlow или PyTorch, активно используются для распознавания объектов на изображениях. Эти библиотеки предоставляют готовые инструменты и архитектуры, которые позволяют быстро приступить к решению задач компьютерного зрения с высокой точностью.
TensorFlow предлагает несколько популярных моделей для распознавания объектов, включая YOLO и EfficientDet. Эти модели могут быть использованы для работы с изображениями, классификации объектов и даже сегментации. Важной особенностью TensorFlow является поддержка Keras, что значительно упрощает построение и обучение моделей. TensorFlow также имеет библиотеки, такие как TensorFlow Lite, для использования в мобильных приложениях, а TensorFlow.js позволяет запускать модели непосредственно в браузере.
В PyTorch существует набор инструментов, которые помогают в распознавании объектов, таких как библиотека Detectron2 от Facebook AI Research, которая предоставляет готовые модели для задач обнаружения объектов. В отличие от TensorFlow, PyTorch обладает динамичной вычислительной графикой, что упрощает отладку и экспериментирование с моделями. Модели, такие как Faster R-CNN или Mask R-CNN, широко используются для детекции и сегментации объектов в реальном времени.
Одним из ключевых факторов при выборе между TensorFlow и PyTorch является требуемая производительность и предпочтения в работе с данными. TensorFlow отличается высокой производительностью на устройствах с GPU и поддерживает распределённое обучение, что делает его хорошим выбором для промышленного использования и крупных моделей. PyTorch, в свою очередь, часто предпочитают исследователи за его гибкость и простоту работы при обучении и тестировании моделей, что ускоряет процесс прототипирования.
Для улучшения точности распознавания объектов можно использовать предварительно обученные модели, доступные в обеих библиотеках. Эти модели, обученные на больших датасетах, таких как COCO или ImageNet, способны значительно сократить время, необходимое для тренировки модели с нуля. Однако для специфических задач может потребоваться дообучение моделей с использованием собственных данных.
Использование таких инструментов, как TensorFlow Hub или TorchVision, значительно ускоряет процесс внедрения и адаптации моделей к новым условиям. Они позволяют интегрировать готовые слои и компоненты в существующие модели, что ускоряет разработку и снижает количество вычислительных ресурсов.
Настройка и использование предварительно обученных моделей для быстрого распознавания
Для начала необходимо выбрать подходящую модель. Наиболее популярными и доступными являются модели из библиотек TensorFlow, PyTorch, а также OpenCV с интеграцией таких моделей как YOLO, MobileNet, ResNet.
1. Установка и настройка
Чтобы начать работу с предварительно обученными моделями, необходимо установить необходимые библиотеки.
- Для TensorFlow:
pip install tensorflow - Для PyTorch:
pip install torch torchvision - Для OpenCV (если используется):
pip install opencv-python
После установки библиотек нужно загрузить модель. Рассмотрим, как это можно сделать для TensorFlow и PyTorch:
- Для TensorFlow загрузка модели происходит через метод
tf.keras.applications, например, для MobileNetV2:model = tf.keras.applications.MobileNetV2(weights="imagenet"). - Для PyTorch загрузка модели выполняется через
torchvision.models, например, для ResNet50:model = torchvision.models.resnet50(pretrained=True).
2. Подготовка данных
Для распознавания объектов на изображении необходимо правильно подготовить входные данные. Прежде всего, нужно выполнить несколько операций:
- Изменить размер изображения, так как большинство моделей ожидает определенные размеры (например, 224×224 для MobileNet).
- Нормализовать пиксели изображения, подгоняя их под диапазон значений, на котором обучалась модель (например, для модели ResNet это [0, 1] или [-1, 1]).
- Преобразовать изображение в формат тензора, который будет передан в модель.
Пример кода для подготовки изображения в TensorFlow:
import tensorflow as tf
from tensorflow.keras.preprocessing import image
import numpy as np
img_path = 'image.jpg' # путь к изображению
img = image.load_img(img_path, target_size=(224, 224)) # загрузка изображения
img_array = image.img_to_array(img) # преобразование в массив
img_array = np.expand_dims(img_array, axis=0) # добавление измерения для батча
img_array = tf.keras.applications.mobilenet_v2.preprocess_input(img_array) # нормализация
3. Использование модели для распознавания
После подготовки данных можно приступать к распознаванию объектов. Перед тем как делать предсказания, важно зафиксировать, что модель работает в режиме оценки (evaluation mode), чтобы отключить компоненты, специфичные для обучения (например, dropout).
- Для TensorFlow использование модели для предсказания:
predictions = model.predict(img_array). - Для PyTorch: передача изображения в модель через:
output = model(input_tensor).
Затем необходимо интерпретировать результат предсказания. Например, для модели MobileNetV2 в TensorFlow результат будет в виде массива вероятностей для каждого из классов ImageNet. Для того чтобы получить название объекта, нужно воспользоваться индексом с наибольшей вероятностью.
predicted_class = tf.keras.applications.mobilenet_v2.decode_predictions(predictions, top=1)[0][0][1]
print(f"Предсказанный класс: {predicted_class}")
4. Тонкая настройка и улучшение результатов
Для улучшения результатов распознавания можно использовать несколько подходов:
- Файн-тюнинг модели на небольшом наборе данных, близком к вашей задаче.
- Использование более сложных моделей, таких как EfficientNet, которые обеспечивают лучшее качество при меньших вычислительных затратах.
- Для некоторых задач может быть полезно объединение нескольких моделей с помощью ансамблей для повышения точности.
Файн-тюнинг обычно включает в себя размораживание нескольких последних слоев модели и обучение их на вашем наборе данных с использованием небольшого learning rate, чтобы избежать переобучения.
5. Заключение

Использование предварительно обученных моделей позволяет сэкономить время и ресурсы, особенно если задача распознавания объектов хорошо соответствует стандартным моделям, обученным на ImageNet или подобным датасетам. Основной задачей остается правильная настройка данных и интерпретация результатов, что является важным шагом для успешного применения модели в реальных условиях.
Вопрос-ответ:
Что такое распознавание объектов на изображении и как это работает?
Распознавание объектов на изображении — это процесс, при котором компьютер анализирует изображение, чтобы определить, какие объекты на нем присутствуют. Основой этого процесса является использование моделей машинного обучения, которые обучаются на большом количестве размеченных изображений. Для выполнения этой задачи часто применяются нейронные сети, такие как сверточные нейронные сети (CNN), которые могут выделять характерные особенности объектов, например, края, текстуры или формы. В Python для реализации таких алгоритмов можно использовать библиотеки, например, TensorFlow или PyTorch.
Какие библиотеки Python чаще всего используются для распознавания объектов на изображениях?
Среди самых популярных библиотек для распознавания объектов на изображениях в Python выделяются TensorFlow, PyTorch и OpenCV. TensorFlow и PyTorch предоставляют мощные инструменты для создания и обучения нейронных сетей, которые способны распознавать объекты на изображениях. OpenCV, в свою очередь, является универсальной библиотекой для обработки изображений и видео, которая включает в себя набор алгоритмов для распознавания лиц, объектов и других задач компьютерного зрения. Каждая из этих библиотек имеет свои особенности и преимущества в зависимости от конкретных требований проекта.
Можно ли распознавать объекты на изображениях в реальном времени с помощью Python?
Да, распознавание объектов на изображениях в реальном времени вполне возможно с помощью Python. Для этого требуется оптимизация алгоритмов, поскольку обработка изображений в реальном времени требует высокой скорости. Библиотеки, такие как OpenCV, позволяют захватывать видео с камер и сразу же обрабатывать каждый кадр. Также можно использовать предобученные модели нейронных сетей, например, на базе TensorFlow или PyTorch, чтобы быстро и точно распознавать объекты, минимизируя задержки в обработке. Однако для этого могут понадобиться мощные вычислительные ресурсы, особенно если речь идет о сложных моделях или видеопотоке с высокой частотой кадров.
Что такое сверточные нейронные сети (CNN) и как они помогают в распознавании объектов?
Сверточные нейронные сети (CNN) — это тип нейронных сетей, специально разработанный для обработки изображений. Они применяют операции свертки для выявления признаков в изображениях, таких как границы, текстуры и формы объектов. Эти признаки затем объединяются для создания более сложных представлений, что позволяет сети распознавать даже самые мелкие детали. CNN используются для распознавания объектов, потому что они способны эффективно работать с пространственными данными, такими как пиксели на изображении. Применение сверточных нейронных сетей в Python можно реализовать с помощью TensorFlow или PyTorch, где есть встроенные компоненты для работы с CNN.
Как обучить модель для распознавания объектов на изображениях?
Обучение модели для распознавания объектов включает несколько шагов. Во-первых, нужно собрать и подготовить набор данных, состоящий из изображений с метками, то есть указанием, какие объекты изображены. Далее, необходимо выбрать модель, например, сверточную нейронную сеть, и настроить ее параметры. После этого модель обучается на выбранном наборе данных, используя методы оптимизации, такие как градиентный спуск, для минимизации ошибки. В Python для этого используют библиотеки, такие как TensorFlow или PyTorch, которые предоставляют инструменты для создания, обучения и тестирования моделей. После обучения модель можно протестировать на новых изображениях, чтобы проверить, насколько хорошо она распознает объекты.
Как распознавать объекты на изображении с помощью Python?
Для распознавания объектов на изображении с помощью Python обычно используют библиотеку OpenCV или более специализированные инструменты, такие как TensorFlow и PyTorch. Одна из распространённых техник — это использование сверточных нейронных сетей (CNN). Процесс начинается с загрузки изображения, его предварительной обработки, такой как изменение размера, нормализация и конвертация в нужный формат. Затем модель обучается на заранее размеченных данных, чтобы распознавать различные объекты. Важно подобрать правильную модель для вашей задачи, так как одна и та же модель может быть эффективной для одного типа объектов и менее продуктивной для других.
Какие библиотеки Python лучше всего подходят для распознавания объектов на изображениях?
Для распознавания объектов на изображениях Python предлагает несколько популярных библиотек. OpenCV — одна из самых известных, она предоставляет функции для обработки изображений, включая детекцию объектов с помощью алгоритмов, таких как Haar каскады. Однако, для более точного и сложного распознавания предпочтительнее использовать такие фреймворки, как TensorFlow или PyTorch. Эти библиотеки поддерживают глубокие нейронные сети, что позволяет обучать модели для сложных задач, таких как распознавание объектов на изображениях. В дополнение к этим инструментам, можно использовать библиотеки, такие как Keras для упрощённого взаимодействия с моделями глубокого обучения, а также scikit-image для базовых операций с изображениями.