В Python стандартный метод для разделения строки – это использование метода split(). Однако, если необходимо разделить строку по нескольким разделителям, стандартных решений недостаточно. В таких случаях на помощь приходят регулярные выражения, которые обеспечивают гибкость и точность при обработке строк с множественными разделителями.
Для работы с регулярными выражениями в Python используется модуль re, который позволяет указать несколько символов-разделителей в одном выражении. С помощью метода re.split() можно легко разделить строку по нескольким символам или паттернам. Например, для разделения строки по пробелам, запятым и точкам можно использовать регулярное выражение, которое описывает все эти символы одновременно.
Важным моментом является правильная настройка регулярного выражения, чтобы оно корректно обрабатывало все нужные разделители и не разделяло строку неверным образом. При этом стоит учитывать, что re.split() возвращает список, в котором будут только те части строки, которые находятся между разделителями.
Использование регулярных выражений для разделения строки
Регулярные выражения в Python предоставляют мощный инструмент для разделения строки по нескольким разделителям, включая символы, пробелы и более сложные паттерны. Для этого используется функция re.split(), которая позволяет задать один или несколько разделителей в виде регулярного выражения.
Пример базового использования:
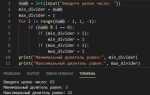
import re
text = "яблоко, груша; апельсин. банан"
result = re.split(r'[;,.]\s*', text)
print(result)
В данном примере строка будет разделена по запятой, точке с запятой и точке, а пробелы после этих символов игнорируются благодаря конструкции \s*.
Если необходимо разделить строку по нескольким возможным символам (например, пробел, табуляция, запятая или точка), регулярные выражения позволяют указать их через квадратные скобки. С помощью этого подхода можно одновременно использовать несколько символов-разделителей.
Пример для нескольких разделителей:
text = "яблоко груша\tапельсин, банан"
result = re.split(r'[ \t,]', text)
print(result)
В этом примере строка разделится по пробелам, табуляциям и запятым.
Для сложных случаев, когда требуется разделить строку по паттерну, включающему более одного символа или специальные условия, регулярные выражения предоставляют гибкость. Например, можно разделить строку по нескольким последовательным пробелам или по любым символам, за исключением букв и цифр:
text = "яблоко груша апельсин"
result = re.split(r'\s{2,}', text)
print(result)
Здесь используется регулярное выражение \s{2,}, которое разделяет строку по двум и более пробелам подряд.
Для более сложных случаев, например, при необходимости исключить разделители, находящиеся в кавычках, можно воспользоваться негативным просмотром или группировками, но эти подходы требуют тщательной настройки выражения в зависимости от контекста задачи.
Регулярные выражения – это гибкий и мощный способ работы с текстовыми данными. Однако стоит помнить, что сложные паттерны могут повлиять на производительность, особенно при работе с большими объемами данных, поэтому важно правильно выбирать и оптимизировать выражения для каждого случая.
Разделение строки с несколькими разделителями через re.split()
Для разделения строки по нескольким разделителям в Python можно воспользоваться функцией re.split() из модуля re. Она позволяет задать регулярное выражение, которое будет учитывать несколько разделителей одновременно.
Пример использования:
import re
text = "apple,banana;orange|grape"
result = re.split(r'[;,|]', text)
print(result)
В этом примере строка делится по запятой, точке с запятой и вертикальной черте. Результат:
['apple', 'banana', 'orange', 'grape']Чтобы разделить строку по большему количеству символов-разделителей, необходимо указать их в регулярном выражении в квадратных скобках. Это создаст один шаблон для поиска всех разделителей.
Особенности использования re.split():
re.split()позволяет разделить строку на основе любых символов или сочетаний символов, определённых в регулярном выражении.- Если требуется исключить пустые строки после разделения, можно использовать флаг
re.split(r'\s*,\s*', text), который удаляет пробелы по бокам. - При использовании регулярных выражений для разделителей, важно правильно экранировать специальные символы, такие как точки (.), звездочки (*) и другие.
Пример, где разделители – пробел и запятая:
text = "apple, banana orange,grape"
result = re.split(r'[ ,]', text)
print(result)
Результат:
['apple', 'banana', 'orange', 'grape']Такой подход позволяет гибко настраивать разделение строк по любым нужным символам или их комбинациям.
Как обрабатывать пробелы и спецсимволы при разделении строки
При разделении строки в Python важно учитывать не только обычные символы-разделители, но и пробелы, табуляции и другие спецсимволы. Это помогает избежать ошибок при обработке данных, особенно если в строках встречаются нестандартные разделители.
Для работы с пробелами и спецсимволами можно использовать модуль re (регулярные выражения). Он предоставляет возможность задать несколько разделителей одновременно.
Обработка пробелов
Пробелы часто используются в качестве разделителей, но важно учитывать их количество. Если пробелы идут подряд, стандартный метод split() сработает, но иногда нужно игнорировать лишние пробелы.
- Для удаления лишних пробелов между словами используйте регулярные выражения, например:
re.split(r'\s+', строка), что разделит строку по одному или нескольким пробелам. - Чтобы удалить ведущие и завершающие пробелы перед разделением, можно воспользоваться методом
strip():строка.strip().split().
Обработка спецсимволов
Для работы с другими символами, такими как табуляции, переводы строки или запятые, регулярные выражения позволяют задать их в качестве разделителей. Например:
- Разделение строки по пробелам и запятым:
re.split(r'[ ,]+', строка). - Если необходимо учесть символы табуляции и переводы строки, можно использовать регулярное выражение:
re.split(r'[\s,]+', строка).
Учёт нескольких разделителей
Для сложных случаев, когда разделители могут быть как пробелами, так и другими спецсимволами (например, запятые или точки с запятой), можно использовать регулярные выражения с несколькими символами:
- Разделение строки по пробелам, запятым и точкам с запятой:
re.split(r'[ ,;]+', строка). - Если необходимо учитывать любой из множества спецсимволов, можно воспользоваться набором символов:
re.split(r'[\s,;]+', строка).
Рекомендации
- Используйте
re.split()с регулярными выражениями для гибкости в обработке различных типов разделителей. - Если спецсимволы могут быть как разделителями, так и частью данных, обязательно экранируйте их, чтобы избежать нежелательных ошибок.
- Тщательно тестируйте регулярные выражения, чтобы убедиться, что они корректно обрабатывают все возможные варианты строк.
Оптимизация разделения строки для больших объемов данных
Для оптимизации также стоит учитывать использование методов str.split() и str.partition(), которые являются более быстрыми для простых случаев, где не требуется сложная логика разделения. Метод str.split() эффективен при разделении строки по одному разделителю, но с несколькими возможными разделителями, можно комбинировать его с регулярными выражениями.
Для обработки больших данных с множественными разделителями рекомендуется использовать библиотеку pandas с методом pandas.Series.str.split(), который позволяет работать с большими массивами строк более эффективно благодаря встроенной оптимизации и возможностям обработки данных в пакетах.
Не стоит забывать об оптимизации работы с памятью. Вместо того, чтобы сразу делить строку на несколько частей, можно рассматривать возможность работы с потоками данных и разделения строк по мере необходимости. Это подход снижает использование памяти, особенно при обработке файлов в реальном времени, и позволяет избежать проблем с производительностью при обработке миллионов строк.
Ещё одной рекомендацией является использование многозадачности (параллельных вычислений) для обработки больших данных. Библиотеки, такие как concurrent.futures, позволяют разделять задачу на несколько потоков, что ускоряет обработку данных, разбивая задачу на независимые части.
Преимущества использования библиотеки re для сложных разделителей

Библиотека re в Python позволяет эффективно работать с регулярными выражениями, что значительно расширяет возможности разделения строк по нескольким, а порой и нестандартным, разделителям. Это особенно полезно при необходимости разделить строку по комбинации символов, шаблонов или даже при обработке строк с динамическими разделителями.
Одним из главных преимуществ использования re является возможность задать сложные шаблоны для разделителей. В отличие от стандартных методов строк, которые ограничены одним символом или фиксированным набором символов, регулярные выражения позволяют учитывать более сложные условия, например, пробелы, знаки препинания, или же их сочетания.
Кроме того, re.split() поддерживает использование групп в регулярных выражениях. Это значит, что можно не только разделить строку, но и сохранить части строки, которые были использованы в качестве разделителей. Это особенно полезно, если важно сохранить контекст или дополнительные данные, которые служат разделителями.
Еще одним важным аспектом является возможность учитывать вариации разделителей. Например, re позволяет легко разделять строку по множеству символов, игнорируя различия в регистрах или пробелах между символами, что невозможно сделать стандартными средствами Python без написания дополнительного кода.
С помощью регулярных выражений также можно избежать дополнительных проверок на наличие разделителей перед выполнением операции. Библиотека re позволяет задать шаблон, который сразу охватывает все возможные варианты разделителей, что сокращает количество операций и повышает производительность.
Таким образом, использование re для работы с сложными разделителями не только упрощает код, но и делает его гибким и масштабируемым для обработки разнообразных данных.
Как избежать пустых элементов в списке после разделения строки

При разделении строки в Python методом split() могут возникать пустые элементы в результате наличия лишних разделителей или пробелов. Чтобы избежать этого, можно воспользоваться несколькими подходами.
Использование метода split() с аргументом: при указании конкретного разделителя, например, пробела, можно исключить лишние пустые строки. Пример:
text = "Пример строк с пробелами"
result = text.split() # разделит по пробелам, исключив пустые строки
print(result) # ['Пример', 'строк', 'с', 'пробелами']
Использование регулярных выражений: для более сложных случаев, например, разделения строки по нескольким символам (запятая, точка, пробел и т.д.), можно применить модуль re. Регулярное выражение \s* позволяет убрать лишние пробелы. Пример:
import re
text = "Пример,, строки, с пробелами, и,, запятыми"
result = re.split(r'\s*,\s*', text) # разделит по запятой, удаляя пустые элементы
print(result) # ['Пример', 'строки', 'с пробелами', 'и', 'запятыми']
Использование метода filter(): для удаления пустых элементов из результата разделения можно применить функцию filter() в сочетании с условием, проверяющим, что строка не пуста:
text = "a,,b,,,c"
result = list(filter(None, text.split(','))) # удалит пустые строки
print(result) # ['a', 'b', 'c']
Вариант с заменой пустых строк: можно предварительно обработать строку с помощью метода replace(), чтобы избавиться от ненужных пробелов или символов:
text = "Пример , строк,, с,, пробелами"
text = text.replace(" ,", ",").replace(",,", ",") # уберет лишние запятые
result = text.split(",")
print(result) # ['Пример', 'строк', 'с', 'пробелами']
Эти методы позволят эффективно избежать появления пустых элементов при разделении строки в Python.
Как обработать строку с переменным количеством разделителей
Когда строка содержит несколько разделителей, важно учитывать их вариативность и количество. В Python для этого удобно использовать регулярные выражения, что позволяет эффективно разделить строку по нескольким символам сразу. Библиотека re предоставляет мощные средства для таких задач.
Для начала можно создать регулярное выражение, которое будет соответствовать одному или нескольким разделителям. Например, если нужно разделить строку по пробелу, запятой или точке с запятой, регулярное выражение будет выглядеть так: r'[ ,;]'. В нем перечислены все возможные разделители, и регулярное выражение разделяет строку по любому из них.
Для применения регулярных выражений используется функция re.split(). Рассмотрим пример:
import re
text = "яблоко, банан; апельсин, груша"
result = re.split(r'[ ,;]', text)
print(result)Этот код разделит строку по пробелам, запятым и точкам с запятой, создав список: ['яблоко', 'банан', 'апельсин', 'груша'].
Если разделители могут быть в переменном количестве подряд, регулярное выражение автоматически справится с этим. Например, два пробела или несколько запятых будут восприняты как один разделитель:
text = "яблоко банан,, апельсин ; ;груша"
result = re.split(r'[ ,;]+', text)
print(result)Результат: ['яблоко', 'банан', 'апельсин', 'груша']. Важно заметить, что символ + в регулярном выражении указывает на то, что один или более разделителей будет трактоваться как единый, что полезно для обработки переменного количества пробелов или запятых.
Для более сложных случаев, когда требуется обработать строку с разными разделителями и фильтровать пустые элементы, можно использовать дополнительные проверки или функции. Например, можно добавить фильтрацию пустых строк:
result = [word for word in re.split(r'[ ,;]+', text) if word]
print(result)Это гарантирует, что в результат попадут только непустые слова.
Работа с разделителями разных типов (например, пробелы, запятые и точки)
В Python для разделения строки по различным типам разделителей удобно использовать регулярные выражения, которые позволяют гибко управлять процессом разделения. Модуль re предоставляет функцию re.split(), которая позволяет делить строку по нескольким разделителям одновременно.
Чтобы разделить строку по пробелам, запятым и точкам, можно использовать регулярное выражение, которое включает все эти символы. Например, регулярное выражение r'[ ,.]' означает «пробел, запятая или точка». Таким образом, строка будет разделена по любому из этих символов.
Пример:
import re
text = "Привет, мир. Как дела?"
result = re.split(r'[ ,.]', text)
print(result)
Этот код вернет список: ['Привет', 'мир', 'Как', 'дела', ''].
Регулярные выражения позволяют более точно контролировать, как происходят разделения. Например, если нужно исключить пустые строки из результата, можно использовать модификацию регулярного выражения, добавив + после символов, чтобы игнорировать последовательности разделителей.
Пример с исключением пустых строк:
result = re.split(r'[ ,.]+', text)
print(result)
Результат будет: ['Привет', 'мир', 'Как', 'дела'].
Также можно использовать встроенные методы строки, такие как str.split(), для разделения строки по одному конкретному символу, например, по пробелу:
text = "Привет мир Как дела"
result = text.split(' ')
print(result)
Этот код вернет: ['Привет', 'мир', 'Как', 'дела'].
Если вам нужно разделить строку по нескольким конкретным символам, можно использовать цикл, который будет вызывать split() для каждого разделителя.