Курсоры в SQL – это механизм, который позволяет работать с набором данных построчно. Несмотря на наличие альтернативных методов обработки данных, таких как обычные запросы SELECT, курсоры обладают рядом особенностей, которые делают их незаменимыми в определённых сценариях. Особенно это важно, когда нужно выполнить сложную логику на уровне каждой строки данных, например, в случае с циклическими операциями или при работе с большим объемом данных, где обычные операции могут быть неэффективны.
Одним из ключевых преимуществ курсоров является возможность сохранения состояния между итерациями. Например, при обработке данных из сложных или нестандартных источников, где требуется выполнять несколько шагов для каждой строки, использование курсора позволяет эффективно организовать этот процесс. В отличие от обычных SELECT-запросов, которые возвращают весь результат сразу, курсор позволяет поочерёдно извлекать и обрабатывать строки, минимизируя нагрузку на систему в случае с большими данными.
В то же время, несмотря на свою гибкость, курсоры требуют осторожности при применении. Их использование может существенно замедлить выполнение операций в случае неправильного обращения. Это связано с тем, что курсоры часто требуют больших затрат на память и могут увеличить время выполнения, если не управлять их состоянием должным образом. Поэтому важно выбирать курсоры, когда другие методы обработки данных оказываются менее эффективными или невозможными.
Важно помнить: курсоры следует использовать в тех случаях, когда нужно обрабатывать данные в последовательности или применять сложную логику, которую нельзя выразить в одном SQL-запросе. Для других задач, таких как массовые обновления или выборки, гораздо предпочтительнее использовать обычные запросы SQL, так как они быстрее и проще в реализации.
Практический совет: прежде чем решиться на использование курсора, оцените возможные альтернативы, такие как JOIN или агрегатные функции, которые могут решить задачу более эффективно с точки зрения производительности. Курсоры должны оставаться инструментом для специфичных случаев, когда нет других путей для оптимизации обработки данных.
Как курсор помогает при обработке большого объема данных

Когда речь идет о больших объемах данных, прямое выполнение запросов может привести к перегрузке памяти или значительному замедлению работы базы данных. В таких случаях использование курсора позволяет эффективно разделить процесс на более мелкие части, которые обрабатываются поочередно, минимизируя нагрузку на систему.
Вот несколько способов, как курсор помогает в обработке большого объема данных:
- Пошаговая обработка данных: Курсор позволяет перебирать строки данных одну за другой, выполняя необходимые операции, что снижает вероятность ошибок и позволяет оптимизировать производительность.
- Гибкость в обработке данных: Курсор дает возможность выполнять сложные логические проверки или операции, которые сложно реализовать в одном запросе, например, циклические вычисления или обработку данных с условными операциями.
- Снижение нагрузки на память: Вместо того, чтобы загружать все данные в память сразу, курсор загружает только одну строку за раз, что позволяет эффективно работать с большими наборами данных, не перегружая систему.
- Отложенная обработка: Курсор помогает отложить выполнение тяжелых операций, делая их более управляемыми и менее ресурсоемкими.
Важно помнить, что использование курсоров в SQL может быть медленным процессом, так как они требуют большего времени на выполнение по сравнению с обычными запросами. Поэтому курсоры стоит использовать только в тех случаях, когда их преимущества очевидны, например, при необходимости выполнять операции на больших объемах данных с сохранением гибкости обработки.
Также следует учитывать, что использование курсоров не всегда является оптимальным решением. В случае, если задачу можно решить через оконные функции или более сложные агрегатные запросы, такие подходы могут быть значительно быстрее, чем использование курсора.
Использование курсора для последовательного доступа к строкам в SQL

Курсор в SQL позволяет эффективно работать с набором данных, выполняя построчную обработку информации. Это особенно полезно в случаях, когда необходимо обработать результаты запроса поочередно, и стандартные SQL-операции не могут обеспечить требуемую гибкость.
Один из ключевых аспектов использования курсора – это возможность обработки строк в последовательности, что важно, когда операция требует выполнения на каждой строке данных отдельного набора действий. Например, в случае комплексных вычислений, которые нельзя выполнить с помощью простых агрегатных функций или объединений.
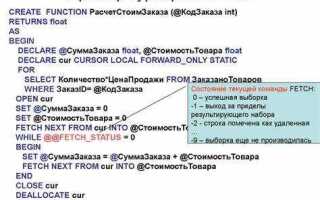
Чтобы использовать курсор, необходимо создать его с помощью команды DECLARE, а затем открыть с помощью OPEN. Курсор будет выполнять итерации по строкам результата запроса с помощью оператора FETCH. Для каждого извлеченного значения можно выполнить необходимые действия, например, обновить данные или выполнить дополнительные вычисления.
Пример создания и использования курсора для обработки строк:
DECLARE my_cursor CURSOR FOR SELECT column_name FROM table_name; OPEN my_cursor; FETCH NEXT FROM my_cursor INTO @variable; WHILE @@FETCH_STATUS = 0 BEGIN -- Выполнение операций с текущей строкой FETCH NEXT FROM my_cursor INTO @variable; END; CLOSE my_cursor; DEALLOCATE my_cursor;
Курсор оптимален в ситуациях, когда необходим доступ к данным в последовательности, и когда не возможно заранее предсказать количество операций или их сложность. Однако, важно учитывать, что курсоры могут негативно сказываться на производительности в случае работы с большими объемами данных, так как они обрабатывают каждую строку по очереди.
Для повышения эффективности можно использовать «тихие» курсоры или курсоры с ограничением на количество извлекаемых строк. Эти методы позволяют снизить нагрузку на сервер, особенно при работе с большими объемами данных.
Не рекомендуется использовать курсоры в случаях, когда возможно применение SQL-операторов, таких как JOIN, GROUP BY, или UPDATE с условием. Эти подходы обеспечивают более высокую производительность и позволяют выполнить операцию за меньшее количество запросов к базе данных.
Применение курсора для выполнения построчных вычислений
Курсор в SQL используется для обработки данных построчно, что особенно полезно в случае, когда необходимо выполнить сложные вычисления или операции, которые не могут быть выполнены стандартными SQL-запросами. Это подходит для ситуаций, когда каждый элемент набора данных зависит от предыдущего или когда требуется выполнение специфичных действий для каждой строки отдельно.
Пример: при вычислении итоговых значений для каждой строки, основанных на данных из других таблиц или сложных алгоритмах. Например, для расчета скидок, изменения цен в зависимости от условий или выполнения преобразований, которые нельзя выразить через простые агрегатные функции.
Для реализации этого подхода курсор используется для последовательного перебора строк в выборке. На каждой итерации курсор позволяет выполнить вычисления и обновить соответствующие данные. Такой метод дает точный контроль над процессом обработки и позволяет легко учитывать изменения в бизнес-логике на уровне каждой строки данных.
Пример использования курсора для вычисления скидки:
Допустим, необходимо применить индивидуальную скидку к каждому заказу в зависимости от суммы заказа. Для этого создается курсор, который перебирает заказы, вычисляет нужный коэффициент скидки и обновляет таблицу с заказами.
При этом важно учитывать, что использование курсоров может быть менее эффективным по сравнению с массовыми обновлениями через SQL-запросы. Каждый проход курсора требует обращения к данным, что увеличивает время выполнения операции, особенно для больших наборов данных.
Рекомендации: если для выполнения вычислений возможно использовать стандартные SQL-функции, лучше избегать курсоров. Однако если вычисления сложные, многократные и зависят от состояния предыдущих строк, использование курсора оправдано. Важно также помнить, что курсоры требуют внимательного управления ресурсами – их нужно явно закрывать после завершения работы, чтобы избежать утечек памяти.
Риски и ограничения при работе с курсорами в SQL

Курсоры в SQL предназначены для построчной обработки данных, но их использование связано с несколькими рисками и ограничениями. Эти проблемы могут существенно повлиять на производительность системы и сложность обслуживания кода.
1. Производительность
Курсоры обрабатывают данные построчно, что приводит к значительным накладным расходам. В отличие от стандартных операций SELECT, которые возвращают все строки за один раз, курсор обрабатывает каждую строку по очереди, что увеличивает время выполнения запросов. Это особенно заметно при работе с большими объемами данных, где возможна нагрузка на процессор и память сервера.
2. Блокировки и параллелизм
При работе с курсорами часто возникают проблемы с блокировками. Использование курсора может привести к длительным транзакциям, которые удерживают блокировки на строках или таблицах, что снижает общую производительность системы. Особенно это заметно при многопользовательской работе с базой данных, где блокировки могут вызывать задержки и снижать параллельность выполнения запросов.
3. Использование ресурсов
Курсоры могут значительно увеличивать потребление ресурсов, таких как память и процессорное время. При открытии курсора сохраняется состояние на сервере для каждой строки, что может привести к переполнению памяти в случае обработки большого объема данных. Это также может повлиять на стабильность работы базы данных, особенно при работе с ограниченными ресурсами.
4. Сложность управления транзакциями
Курсоры часто используются внутри транзакций, что увеличивает их сложность. Невозможность эффективно контролировать завершение транзакции может привести к нежелательным блокировкам и ошибкам. Также курсоры могут оставлять неявные изменения данных, которые усложняют отладку и диагностику ошибок в коде.
5. Трудности с масштабируемостью
При проектировании систем, которые должны обрабатывать большие объемы данных с использованием курсоров, возникает проблема масштабируемости. Курсоры плохо масштабируются на распределенных системах и могут стать узким местом при увеличении нагрузки на сервер. Для крупных проектов более подходящими являются операции, использующие наборы данных и позволяют обрабатывать их пакетами.
6. Ограничения на типы данных
Некоторые типы данных, такие как большие бинарные объекты или текстовые данные, могут не поддерживаться курсорами в определенных СУБД. Это ограничивает использование курсоров для обработки определенных типов информации и требует дополнительных преобразований данных, что увеличивает сложность кода.
Рекомендации:
Использование курсоров рекомендуется минимизировать, заменяя их на более эффективные подходы, такие как использование агрегатных функций или операций с пакетами данных. Если курсор неизбежен, необходимо тщательно следить за его производительностью, блокировками и ресурсами. Регулярная оптимизация запросов и тщательное управление транзакциями помогут избежать большинства рисков при работе с курсорами.
Как правильно закрывать курсор для предотвращения утечек памяти

Для предотвращения утечек памяти важно правильно закрывать курсор после его использования. Курсор в SQL управляет доступом к строкам результата запроса, и если его не закрывать, он продолжает удерживать ресурсы системы, что может привести к замедлению работы базы данных и даже к её сбоям.
Закрытие курсора требует выполнения команды FETCH для извлечения всех данных или явного завершения цикла обработки. После этого необходимо вызвать команду CLOSE, чтобы освободить все ресурсы, связанные с курсором. Важно помнить, что не закрытый курсор продолжает использовать память, что может привести к перегрузке системы.
Рекомендуется использовать конструкцию TRY...CATCH для обработки ошибок, чтобы курсор был закрыт корректно даже в случае сбоя в процессе выполнения запроса. В этом случае курсор будет закрыт независимо от того, возникли ли ошибки во время работы.
Кроме того, курсоры должны быть закрыты внутри блока BEGIN...END, чтобы гарантировать, что ресурс будет освобождён после завершения операции. Закрытие курсора сразу после использования также снижает вероятность того, что другие процессы будут зависеть от его состояния.
Для повышения эффективности можно использовать DEALLOCATE после закрытия курсора. Это действие освобождает не только сам курсор, но и связанные с ним параметры, что дополнительно снижает нагрузку на систему и предотвращает утечку памяти.
В большинстве случаев рекомендуется использовать курсоры с ограниченным временем жизни. Это поможет избежать долговременного удержания ресурсов, особенно в случае с большими объёмами данных.
Когда стоит предпочесть курсор другим методам обработки данных в SQL
Курсоры в SQL могут быть полезными в случаях, когда требуется обработка данных построчно, а не целыми наборами. Это актуально, если необходимо выполнять сложные операции, которые не могут быть выполнены простыми SQL-запросами. Например, когда нужно последовательно обрабатывать и изменять данные на основе значений, полученных в предыдущих шагах, курсор позволяет управлять каждым шагом обработки. Это полезно, если логика обработки данных включает в себя выполнение условий, которые зависят от текущего состояния данных.
Другим случаем, когда курсор становится предпочтительным, является работа с данными, которые должны быть обработаны в транзакциях, требующих явного контроля над выполнением. Например, если требуется обеспечить строгую последовательность операций с гарантированным возвратом к предыдущему состоянию при ошибке, курсор с явным управлением транзакциями позволит лучше контролировать процесс, в отличие от массовых операций.
Курсоры также могут быть полезны в ситуациях, где требуется оптимизация работы с большими объемами данных, если такие данные нельзя обработать за один запрос без риска перегрузки памяти. Курсор позволяет обработать данные порциями, что минимизирует нагрузку на систему.
Важно помнить, что курсор следует использовать, когда другие методы, такие как объединения, агрегации или оконные функции, не дают нужного результата или становятся слишком сложными для реализации. Однако стоит избегать использования курсоров, если существует возможность обработки данных с использованием более эффективных подходов, таких как пакетные операции или запросы с подзапросами, так как курсор может значительно снизить производительность, особенно на больших объемах данных.
Вопрос-ответ:
Что такое курсор в SQL и зачем он нужен?
Курсор в SQL — это механизм, который позволяет обрабатывать строки результата запроса одну за другой. Он нужен, когда необходимо выполнить операцию с каждым элементом набора данных поочередно. Например, это может быть полезно для обработки строк с использованием логики, которой нельзя выполнить через стандартные SQL-запросы, такие как циклы или сложные вычисления на уровне каждой строки.
В каких случаях лучше использовать курсор, а не обычный SQL-запрос?
Курсор имеет смысл использовать, когда нужно выполнить операции, которые невозможно или крайне сложно выразить в одном SQL-запросе. Например, если требуется обработать строки поочередно с условием для каждой, или когда операция требует изменения состояния внешних переменных или вызывает другие побочные эффекты, которые не могут быть учтены в простом SQL-запросе.
Какие недостатки могут быть у использования курсора в SQL?
Использование курсоров может негативно сказаться на производительности, так как они обрабатывают строки по одной, что замедляет выполнение операций на больших объемах данных. Также курсоры занимают ресурсы сервера, что может привести к дополнительной нагрузке и снижению общей скорости работы базы данных. В большинстве случаев предпочтительнее использовать стандартные SQL-запросы с агрегатными функциями или операциями над множеством строк одновременно.
Можно ли использовать курсоры для обработки данных в реальном времени, например, для мониторинга изменений?
Курсоры обычно не предназначены для мониторинга изменений в реальном времени, так как они не отслеживают обновления в базе данных в режиме онлайн. Для таких задач лучше использовать механизмы триггеров или системы, поддерживающие отслеживание изменений. Однако курсоры могут быть полезны для обработки уже полученных данных или для выполнения операций в определенный момент времени, когда постоянное отслеживание изменений не требуется.
Есть ли альтернативы курсорам в SQL для обработки данных?
Да, для многих задач можно использовать альтернативы курсорам. Например, можно воспользоваться операциями обработки данных с использованием стандартных SQL-операторов, таких как JOIN, WHERE, GROUP BY или агрегатные функции. Эти методы часто более эффективны с точки зрения производительности, так как они работают с целыми наборами данных одновременно. Также можно использовать оконные функции или встроенные процедуры, которые обеспечивают гибкость без использования курсоров.
Зачем использовать курсор в SQL для обработки данных?
Курсоры в SQL нужны для обработки строк данных по одной. Это позволяет выполнить более сложные операции, которые не могут быть легко выполнены с использованием обычных SQL-запросов, например, обновление или вставка значений с учетом условий, которые зависят от других строк. Курсор может быть полезен, когда требуется пошагово обрабатывать записи или при выполнении действий, которые нельзя выразить в виде одного запроса. Однако, использование курсора может негативно повлиять на производительность, особенно при работе с большим объемом данных, поэтому важно внимательно подходить к выбору подхода для решения задачи.