В Python переменная – это именованная ссылка на объект в памяти. Сохраняя переменную, вы фактически назначаете значение, которое может быть использовано и изменено в программе. Этот процесс не требует сложных конструкций, но важно понимать, как правильно работать с переменными, чтобы избежать ошибок и оптимизировать использование памяти.
Для создания и сохранения переменной достаточно присвоить ей значение. В Python не нужно заранее объявлять тип переменной, как это требуется в некоторых других языках программирования. Python автоматически определяет тип на основе присваиваемого значения. Например, если переменной присваивается число, Python определит ее как integer, а если строку – как string.
Важно помнить, что переменные в Python могут быть изменяемыми и неизменяемыми. Если вы работаете с изменяемым типом, таким как list или dict, то при изменении содержимого переменной реальное изменение происходит в том месте памяти, на которое ссылается переменная. Если переменная ссылается на неизменяемый объект, например, строку или кортеж, то при изменении создается новый объект в памяти.
Для эффективного сохранения данных в программе важно учитывать область видимости переменной. Переменные, определенные внутри функций, имеют локальную область видимости, и они не доступны за пределами этой функции. В то время как переменные, определенные на уровне модуля, будут доступны по всему коду, если они не скрыты локальными переменными в функциях.
Использование оператора присваивания для сохранения значения
Оператор присваивания (=) в Python используется для сохранения значения в переменную. Это основной способ работы с данными в языке, поскольку каждый результат вычислений или ввода данных нужно как-то сохранить для дальнейшего использования.
Пример базового присваивания:
x = 10В этом примере переменная x получает значение 10. Далее это значение может быть использовано в различных операциях, например:
y = x + 5 # y будет равно 15Присваивание выполняется справа налево. Значение или выражение, находящееся справа от оператора =, вычисляется, а результат присваивается переменной слева.
Существует несколько особенностей использования оператора присваивания:
- Переменная может хранить любые типы данных: числа, строки, списки, кортежи, словари, и даже функции.
- В Python переменные динамически типизируются, то есть тип переменной не фиксируется заранее. Например, после присваивания строкового значения переменная может быть переопределена числовым значением:
name = "Alice"
name = 25Также возможно использование множественного присваивания, когда нескольким переменным одновременно присваиваются одинаковые значения:
a = b = c = 0После этого все три переменные a, b и c будут равны 0.
В случае с коллекциями (списки, словари и т.д.) присваивание будет работать по ссылке, что важно учитывать при изменении содержимого коллекций:
list1 = [1, 2, 3]
list2 = list1
list2[0] = 10
print(list1) # [10, 2, 3]Если требуется избежать изменения оригинального объекта, необходимо использовать метод копирования:
list1 = [1, 2, 3]
list2 = list1.copy()
list2[0] = 10
print(list1) # [1, 2, 3]Важно понимать, что присваивание – это не копирование данных, а создание ссылки на объект в памяти. Это следует учитывать при работе с большими данными, например, при работе с большими списками или словарями.
Хранение данных в списках и словарях
Списки – это упорядоченные коллекции объектов. Они могут содержать элементы различных типов и изменяться после создания. Например, список может быть использован для хранения последовательности значений, таких как числа, строки или даже другие списки. Это делает их удобными для случаев, когда нужно работать с упорядоченными данными или выполнять операции, связанные с индексами элементов.
Пример создания списка:
my_list = [1, 2, 3, "Python", [4, 5]]
Добавление элемента в список можно выполнить с помощью метода append():
my_list.append("New item")
Доступ к элементам списка осуществляется через индексы. Например, my_list[0] вернёт первый элемент:
print(my_list[0]) # 1
Словари представляют собой неупорядоченные коллекции пар «ключ-значение». Они полезны, когда необходимо ассоциировать определённые данные с уникальными ключами, например, хранение информации о пользователях по их идентификаторам.
Пример создания словаря:
my_dict = {"name": "Alice", "age": 30, "city": "New York"}
Чтобы получить значение, ассоциированное с ключом, используется синтаксис с квадратными скобками:
print(my_dict["name"]) # Alice
Добавление новой пары «ключ-значение» в словарь можно выполнить через прямое присваивание:
my_dict["email"] = "alice@example.com"
Списки и словари играют ключевую роль в обработке данных, и каждый из этих типов данных имеет свои особенности в использовании. Списки полезны, когда важно сохранить порядок данных, а словари – когда нужно быстро искать и извлекать данные по ключу.
Сохранение состояния между сессиями с помощью файлов
Для сохранения состояния переменных между сессиями в Python можно использовать файловую систему. Этот способ позволяет сохранить данные, которые могут быть использованы при повторном запуске программы, без необходимости в базе данных. Для этого чаще всего применяют стандартные форматы, такие как текстовые файлы, JSON или pickle.
Текстовые файлы представляют собой самый простой способ сохранения данных. Для записи состояния в файл достаточно использовать встроенную функцию open() с режимом записи, например:
with open('state.txt', 'w') as file:
file.write(str(переменная))В данном примере переменная конвертируется в строку перед записью. Для загрузки данных из файла используется тот же метод, но с режимом чтения (‘r’):
with open('state.txt', 'r') as file:
data = file.read()Однако при использовании текстовых файлов важно учитывать, что сложные объекты, такие как списки или словари, потребуют дополнительных усилий для сохранения и загрузки. В таких случаях более подходящим вариантом будет использование формата JSON.
JSON представляет собой легковесный формат для обмена данными. Он удобен для хранения структурированных данных (например, списков или словарей). Для работы с JSON в Python используется модуль json. Пример записи в файл:
import json
data = {'ключ': 'значение'}
with open('state.json', 'w') as file:
json.dump(data, file)Для чтения данных из JSON файла используется метод json.load():
with open('state.json', 'r') as file:
data = json.load(file)JSON позволяет легко сохранять и загружать более сложные структуры данных, такие как вложенные списки и словари, с минимальными усилиями.
Если требуется сохранить более сложные объекты Python, такие как экземпляры классов, лучше использовать pickle. Этот модуль сериализует объекты Python в байтовый поток, который можно сохранить в файл. Пример сохранения объекта с помощью pickle:
import pickle
data = {'ключ': 'значение'}
with open('state.pkl', 'wb') as file:
pickle.dump(data, file)Для загрузки данных из pickle-файла:
with open('state.pkl', 'rb') as file:
data = pickle.load(file)Однако использование pickle связано с рисками безопасности, особенно если данные поступают из ненадежных источников. Поэтому рекомендуется избегать загрузки данных с использованием pickle из неизвестных или непроверенных источников.
Для большинства случаев сохранения состояния между сессиями оптимальным выбором является формат JSON, так как он сочетает простоту и универсальность. Однако для более сложных структур данных, когда необходимо сохранить и восстановить именно объекты Python, удобно использовать pickle. В любом случае, выбор метода зависит от сложности данных и специфики задачи.
Как сохранить переменные в модуле или классе

В Python переменные могут быть сохранены в модулях и классах для того, чтобы обеспечить доступ к данным на разных уровнях программы. Существует несколько способов организации переменных в этих контекстах, каждый из которых имеет свои особенности и области применения.
Модульные переменные – это переменные, объявленные на уровне модуля. Они становятся доступными для других файлов, если тот модуль импортирован. Чтобы сохранить переменную в модуле, достаточно просто присвоить значение переменной в теле модуля, и она будет доступна везде, где импортирован данный модуль.
Пример:
# module.py my_variable = 42
В другом файле вы можете импортировать переменную и работать с ней:
# main.py from module import my_variable print(my_variable) # Выведет 42
Переменные, определённые таким образом, являются глобальными в рамках модуля, но остаются приватными для других файлов, если их не экспортировать явно. Это может быть полезно для настройки параметров или хранения конфигурационных данных, доступных только внутри одного модуля.
Переменные в классе используются для сохранения данных, которые принадлежат конкретному объекту (экземпляру класса). Они определяются внутри метода __init__() и получают значения при создании объекта. Такой подход гарантирует, что каждый объект будет иметь свои собственные данные.
Пример:
class MyClass: def __init__(self, value): self.my_variable = value
Теперь, создавая объект класса, можно установить значение переменной:
obj = MyClass(10) print(obj.my_variable) # Выведет 10
Кроме того, можно использовать классные переменные (переменные, которые принадлежат классу, а не его экземплярам). Они определяются вне методов и общи для всех экземпляров класса. Такие переменные полезны, когда необходимо иметь общие данные для всех объектов данного класса.
Пример:
class MyClass: class_variable = 100 def __init__(self, value): self.instance_variable = value
Переменная class_variable будет общей для всех объектов класса, а instance_variable – индивидуальной для каждого экземпляра.
При работе с переменными внутри классов важно помнить, что использование классных переменных может привести к нежелательным изменениям данных, если они изменяются через экземпляры класса. Для предотвращения этого, можно применять методы для работы с такими данными, ограничивая прямой доступ.
Применение глобальных переменных для сохранения данных
Глобальные переменные в Python представляют собой такие переменные, которые доступны в любой части программы, включая функции и модули. Это позволяет использовать их для хранения данных, которые должны быть доступны на протяжении всего выполнения программы.
Однако, использование глобальных переменных требует осмотрительности, так как оно может повлиять на читаемость кода и создать проблемы с его поддержкой. Рассмотрим несколько важных аспектов при применении глобальных переменных для сохранения данных.
Когда использовать глобальные переменные

- Передача данных между функциями: Когда необходимо передать данные между различными функциями, глобальные переменные позволяют избежать необходимости явного возвращения значений.
- Долгосрочное хранение состояния: Для сохранения состояния программы на протяжении всего её выполнения глобальные переменные могут быть удобным вариантом. Это может быть полезно, например, для хранения конфигурации или настроек.
Основные принципы работы с глобальными переменными
- Объявление: Чтобы создать глобальную переменную, нужно объявить её вне всех функций. Пример:
global_var = 10
- Изменение значений: Для изменения глобальной переменной внутри функции нужно использовать ключевое слово
global:def change_value():
global global_var
global_var = 20 - Чтение значений: Для чтения значений глобальных переменных не нужно использовать ключевое слово
global, достаточно просто ссылаться на переменную:print(global_var)
Преимущества использования глобальных переменных
- Удобство при работе с состоянием программы: Для больших программ, где нужно хранить информацию, доступную в разных частях, использование глобальных переменных может упростить код.
- Экономия времени: Глобальные переменные устраняют необходимость повторного вычисления значений или их передачи через параметры.
Минусы и риски
- Низкая читаемость: Программу с множеством глобальных переменных сложнее понять и поддерживать. Изменение состояния в одной части программы может неожиданно повлиять на другие части.
- Конфликты имен: Если несколько функций используют одно имя глобальной переменной, это может привести к ошибкам или неправильному поведению программы.
- Трудности с тестированием: Глобальные переменные усложняют написание тестов, так как они могут быть изменены из разных мест программы.
Рекомендации
- Используйте глобальные переменные только в тех случаях, когда другие методы (например, параметры функций или возвращаемые значения) не обеспечивают удобства.
- Для работы с глобальными переменными внутри функций используйте ключевое слово
global, чтобы избежать путаницы с локальными переменными. - Рассматривайте возможность использования классов и объектов для хранения данных, если это позволяет лучше организовать структуру программы.
- Следите за именами глобальных переменных, чтобы избежать конфликтов и путаницы в коде.
Использование базы данных для долговременного хранения значений
Для долговременного хранения значений в Python часто используется база данных. Это особенно важно, когда требуется сохранять данные между сессиями программы или передавать информацию между различными частями приложения. В зависимости от задачи можно выбрать как реляционные, так и нереляционные базы данных.
Одним из самых распространённых вариантов является использование SQLite, встроенной базы данных, которая не требует установки и конфигурации. Для её использования достаточно подключить библиотеку sqlite3, которая входит в стандартную библиотеку Python.
Пример сохранения и извлечения данных в SQLite:
import sqlite3
# Подключение к базе данных
conn = sqlite3.connect('my_database.db')
cursor = conn.cursor()
# Создание таблицы, если она не существует
cursor.execute('''CREATE TABLE IF NOT EXISTS variables (id INTEGER PRIMARY KEY, value TEXT)''')
# Вставка данных
cursor.execute('''INSERT INTO variables (value) VALUES (?)''', ('some_value',))
# Сохранение изменений
conn.commit()
# Извлечение данных
cursor.execute('''SELECT value FROM variables WHERE id = 1''')
data = cursor.fetchone()
print(data[0])
# Закрытие соединения
conn.close()
Если необходимо работать с более сложными данными, такими как коллекции или большие объёмы информации, можно выбрать NoSQL базы данных, например, MongoDB. Для работы с MongoDB в Python используется библиотека pymongo.
Пример взаимодействия с MongoDB:
from pymongo import MongoClient
# Подключение к серверу MongoDB
client = MongoClient('mongodb://localhost:27017/')
db = client['my_database']
collection = db['variables']
# Вставка данных
collection.insert_one({'value': 'some_value'})
# Извлечение данных
document = collection.find_one({'value': 'some_value'})
print(document['value'])
Для небольших проектов, где не требуется высокая нагрузка на базу данных, SQLite может быть оптимальным решением, так как он не требует установки и настройки. MongoDB лучше подходит для масштабируемых приложений, где важна гибкость схемы данных.
Важно помнить, что при использовании базы данных необходимо обрабатывать исключения и ошибки подключения, чтобы избежать потери данных и обеспечить корректную работу приложения в случае сбоев.
Как сохранить переменную в JSON или Pickle форматах
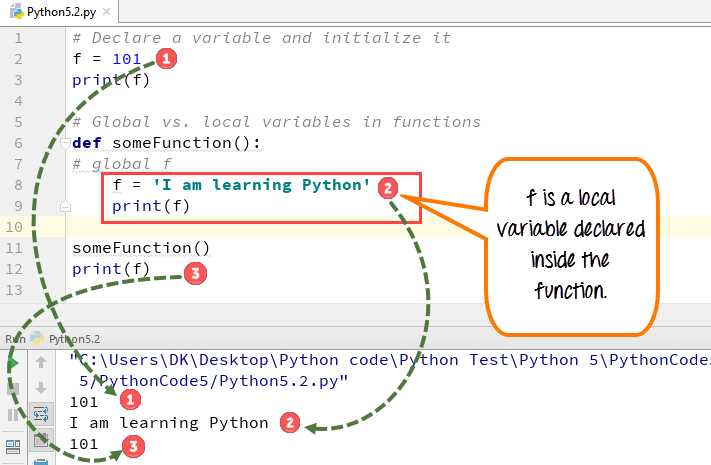
Чтобы сохранить переменную в формате JSON, следует использовать встроенный модуль json. Преимущество этого подхода – совместимость с другими языками программирования. Сохранить объект в JSON можно с помощью функции json.dump() для записи в файл или json.dumps() для преобразования в строку.
import json
data = {'name': 'Alice', 'age': 30}
with open('data.json', 'w') as file:
json.dump(data, file)
Этот код создает файл data.json, в котором содержится сериализованный объект. Важно помнить, что JSON поддерживает только базовые типы данных, такие как строки, числа, списки и словари. Комплексные объекты Python, например, экземпляры классов, не могут быть сохранены в этом формате без предварительной обработки.
Для сохранения объектов Python в их оригинальном виде без потери информации используется формат Pickle. Этот формат подходит для работы с любыми объектами, поддерживаемыми Python, включая функции и классы. Чтобы сохранить переменную с помощью Pickle, нужно использовать модуль pickle.
import pickle
data = {'name': 'Alice', 'age': 30}
with open('data.pkl', 'wb') as file:
pickle.dump(data, file)
В данном примере объект сохраняется в файл data.pkl в бинарном виде. Использование Pickle безопасно только для собственных данных, поскольку при загрузке сериализованного объекта можно выполнить произвольный код, что может быть уязвимостью при загрузке данных от ненадежных источников.
В общем случае, если ваша задача – обмениваться данными между разными языками или системами, используйте JSON. Если вам нужно сохранить сложные объекты Python, выбирайте Pickle, но будьте осторожны при его использовании в открытых или ненадежных средах.
Вопрос-ответ:
Как в Python сохранить значение переменной, чтобы оно не терялось при завершении работы программы?
В Python можно использовать несколько способов для сохранения данных. Один из самых простых — это запись информации в файл. Для этого открываем файл с помощью встроенной функции `open()`, затем записываем данные через методы `write()` или `writelines()`. Если нужно сохранить данные между сессиями программы, можно использовать библиотеку `pickle` для сериализации объектов или библиотеку `json` для сохранения данных в формате JSON. Также существует возможность работы с базами данных, например, с использованием SQLite.
Какие типы данных в Python можно сохранять в файл?
В Python можно сохранять различные типы данных, такие как строки, числа, списки, кортежи, множества, словари и объекты. Для простых данных, таких как строки и числа, можно использовать стандартные текстовые файлы. Для более сложных объектов (например, экземпляров классов) удобно применять библиотеки для сериализации, например, `pickle` или `json`. Эти библиотеки позволяют записывать и считывать объекты в удобном для человека формате, что делает работу с данными удобной и гибкой.
Что такое сериализация данных в Python и как ее применить?
Сериализация в Python — это процесс преобразования объектов (например, словарей, списков или других структур) в формат, который можно записать в файл или передать по сети. Для сериализации в Python чаще всего используют библиотеку `pickle`. Чтобы сериализовать объект, нужно вызвать функцию `pickle.dump()`, которая записывает объект в файл. Для восстановления объекта из файла используется функция `pickle.load()`. Еще один популярный формат сериализации — это JSON, который подходит для работы с текстовыми данными и используется с библиотекой `json`.
Можно ли сохранить данные, которые не являются стандартными типами Python, в файл?
Да, можно. В Python для сохранения нестандартных объектов (например, объектов пользовательских классов) нужно использовать библиотеку `pickle`, которая позволяет сериализовать практически любые объекты Python, включая сложные структуры. Для этого используется функция `pickle.dump()` для записи объекта в файл и `pickle.load()` для его восстановления. Важно помнить, что файлы, созданные с помощью `pickle`, могут быть небезопасными, если вы не уверены в источнике этих данных, так как они могут содержать вредоносный код.