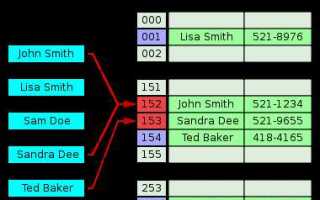
Хеш таблица – структура данных, обеспечивающая доступ к значениям по ключу за константное время в среднем случае. В Python встроенным аналогом хеш таблицы является тип dict, но для глубокого понимания важно реализовать эту структуру самостоятельно. Это позволяет контролировать механизм хеширования, разрешение коллизий и оценку производительности.
Минимальная реализация включает массив фиксированного размера, функцию хеширования и метод обработки коллизий. Хеш-функция преобразует ключ в индекс массива. Коллизии – ситуация, когда два ключа получают один и тот же индекс – неизбежны, особенно при увеличении числа элементов. Эффективный способ их разрешения – открытая адресация или цепочки.
Использование встроенной функции hash() не всегда безопасно при сериализации, поскольку она зависит от сессии. Для стабильных результатов предпочтительно использовать пользовательские хеш-функции, особенно если структура будет использоваться в кэшировании или файловом хранилище.
При проектировании важно контролировать коэффициент загрузки – отношение количества элементов к размеру массива. Если он превышает 0.7, эффективность резко снижается, и требуется рехеширование с увеличением массива. Такой подход позволяет поддерживать производительность независимо от объема данных.
Как вручную реализовать хеш таблицу с помощью списков и кортежей
Для создания простой хеш таблицы вручную используется список фиксированной длины, где каждая ячейка хранит кортежи вида (ключ, значение). Ключи преобразуются в индексы с помощью хеш-функции. В случае коллизий (совпадения индексов) применяется метод цепочек – в каждой ячейке хранится список кортежей.
Пример структуры:
table_size = 10
hash_table = [[] for _ in range(table_size)]Хеш-функция должна возвращать индекс в пределах длины таблицы. Простой вариант – остаток от деления хеша ключа:
def hash_func(key):
return hash(key) % table_sizeДобавление элемента выполняется с проверкой на наличие ключа. Если ключ уже существует, его значение обновляется:
def insert(key, value):
index = hash_func(key)
for i, (k, v) in enumerate(hash_table[index]):
if k == key:
hash_table[index][i] = (key, value)
return
hash_table[index].append((key, value))Поиск значения по ключу:
def get(key):
index = hash_func(key)
for k, v in hash_table[index]:
if k == key:
return v
return NoneУдаление ключа:
def remove(key):
index = hash_func(key)
for i, (k, _) in enumerate(hash_table[index]):
if k == key:
del hash_table[index][i]
returnЭтот подход демонстрирует основные принципы работы хеш таблиц: хеширование, разрешение коллизий и операции вставки, поиска и удаления без использования встроенных структур Python.
Что использовать в качестве ключей и как это влияет на хеш-функцию
Ключи в хеш-таблицах Python должны быть хешируемыми, то есть обладать неизменяемостью и реализовывать метод __hash__(). Типы, подходящие для использования в качестве ключей:
- Строки: один из самых распространённых вариантов. Обладают стабильной хеш-функцией и легко интерпретируются.
- Числа (int, float): быстро сравниваются и хешируются. Следует учитывать, что
1 == 1.0, но их хеш одинаковый – возможны коллизии при комбинировании типов. - Кортежи: допустимы только если содержат исключительно хешируемые элементы. Удобны для составных ключей.
Нельзя использовать изменяемые типы, такие как списки, словари и множества, поскольку они не реализуют __hash__() и могут измениться после вставки в хеш-таблицу, нарушив консистентность.
Выбор ключа влияет на:
- Производительность: числовые ключи обрабатываются быстрее строк; короткие строки – быстрее длинных.
- Распределение хешей: плохой выбор ключей (например, строки с повторяющимся префиксом) увеличивает количество коллизий. Это снижает эффективность доступа и вставки.
- Стабильность: начиная с Python 3.3, используется случайная соль при хешировании строк. Это защищает от атак, но делает хеши непредсказуемыми между запусками. Не полагайтесь на
hash()для сериализации или хранения.
Рекомендации:
- Используйте кортежи вместо строк, если ключ состоит из нескольких значений.
- Избегайте хеширования пользовательских объектов без явной реализации
__hash__()и__eq__(). - При необходимости пользовательских ключей – делайте их неизменяемыми (
@dataclass(frozen=True)).
Обработка коллизий: методы цепочек и открытой адресации
Коллизия возникает, когда два различных ключа хешируются в одну и ту же ячейку. Эффективная обработка коллизий критична для производительности хеш-таблицы. В Python стандартная реализация dict использует открытую адресацию, однако полезно понимать оба метода.
Метод цепочек (separate chaining) хранит в каждой ячейке массива список элементов с одинаковым хешем. Это позволяет избежать переполнения при большом количестве коллизий.
class HashTableChaining:
def __init__(self, size=10):
self.size = size
self.table = [[] for _ in range(size)]
def _hash(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self._hash(key)
for i, (k, _) in enumerate(self.table[index]):
if k == key:
self.table[index][i] = (key, value)
return
self.table[index].append((key, value))
def get(self, key):
index = self._hash(key)
for k, v in self.table[index]:
if k == key:
return v
raise KeyError(key)
Преимущества: простота реализации, стабильная производительность при малой загрузке. Недостатки: ухудшение времени поиска при увеличении числа элементов в цепочках.
Открытая адресация (open addressing) хранит все элементы внутри массива. При коллизии ищется следующая свободная ячейка по определённой стратегии: линейное, квадратичное или двойное хеширование.
class HashTableOpenAddressing:
def __init__(self, size=10):
self.size = size
self.table = [None] * size
def _hash(self, key, i=0):
return (hash(key) + i) % self.size # Линейное пробирование
def insert(self, key, value):
for i in range(self.size):
index = self._hash(key, i)
if self.table[index] is None or self.table[index][0] == key:
self.table[index] = (key, value)
return
raise OverflowError("Хеш-таблица переполнена")
def get(self, key):
for i in range(self.size):
index = self._hash(key, i)
if self.table[index] is None:
break
if self.table[index][0] == key:
return self.table[index][1]
raise KeyError(key)
Преимущества: экономия памяти, быстрая локализация данных. Недостатки: чувствительность к загрузке таблицы, требует своевременной реорганизации (рехеширования).
Рекомендации: при использовании цепочек – следить за длиной списков и увеличивать размер таблицы при превышении средней длины цепочки более 3–4. При открытой адресации – не допускать загрузки выше 70% и использовать простое рехеширование при вставке, если возникают частые коллизии.
Когда использовать встроенный словарь Python вместо собственной реализации

- Если требуется хранить до миллионов ключей без потери производительности –
dictиспользует хеш-функции с открытой адресацией и динамическое перераспределение памяти, обеспечивая постоянное время доступа в большинстве случаев. - Для работы с вложенными структурами и сериализацией –
dictсовместим с модулямиjson,pickleиmarshal, что упрощает интеграцию с другими системами. - В случае необходимости поддержки порядка вставки – начиная с Python 3.7,
dictсохраняет порядок элементов, что критично для кода, зависящего от предсказуемой итерации. - Если важна безопасность и корректность – встроенный словарь защищён от большинства распространённых ошибок, таких как коллизии, утечки памяти и неправильная очистка.
- Для многопоточных приложений, где блокировка не требуется на уровне каждой операции – стандартный
dictхорошо работает сthreading, особенно при преобладании операций чтения.
Собственную реализацию хеш-таблицы имеет смысл разрабатывать только при специфических требованиях: нестандартные правила разрешения коллизий, ограниченная среда (например, микроконтроллеры без CPython), жёсткие ограничения по памяти или необходимость полной прозрачности внутренней логики.
Добавление, удаление и поиск элементов в кастомной хеш таблице
Рассмотрим реализацию базовых операций в хеш-таблице с открытой адресацией. Для начала определим структуру таблицы. Используется массив фиксированного размера, в котором каждый слот может содержать кортеж (ключ, значение) или None.
Добавление элемента выполняется по следующему алгоритму: вычисляется хеш ключа, берётся остаток от деления на длину таблицы. Если слот свободен, пара записывается. При коллизии используется линейное пробирование – переход к следующему слоту. Добавление завершается либо успешной вставкой, либо выбрасыванием исключения при заполненной таблице.
def put(self, key, value):
idx = hash(key) % self.size
start_idx = idx
while self.table[idx] is not None and self.table[idx][0] != key:
idx = (idx + 1) % self.size
if idx == start_idx:
raise Exception("Хеш-таблица переполнена")
self.table[idx] = (key, value)Поиск работает аналогично: по хешу определяется индекс, затем линейно просматриваются слоты до нахождения соответствующего ключа или до возврата None при полном цикле.
def get(self, key):
idx = hash(key) % self.size
start_idx = idx
while self.table[idx] is not None:
if self.table[idx][0] == key:
return self.table[idx][1]
idx = (idx + 1) % self.size
if idx == start_idx:
break
return NoneУдаление требует аккуратности. Удалённый слот нельзя просто обнулить, иначе нарушится поиск других элементов, попавших сюда из-за коллизии. Вместо None записывается специальная метка DELETED, которую пропускают при вставке и поиске, но учитывают при пробировании.
DELETED = object()
def remove(self, key):
idx = hash(key) % self.size
start_idx = idx
while self.table[idx] is not None:
if self.table[idx][0] == key:
self.table[idx] = DELETED
return True
idx = (idx + 1) % self.size
if idx == start_idx:
break
return FalseОперации вставки и поиска должны обрабатывать ячейки с DELETED как занятые, но не соответствующие ключу. Это поддерживает корректность алгоритмов при высокой загрузке таблицы.
Как протестировать и отладить пользовательскую хеш таблицу
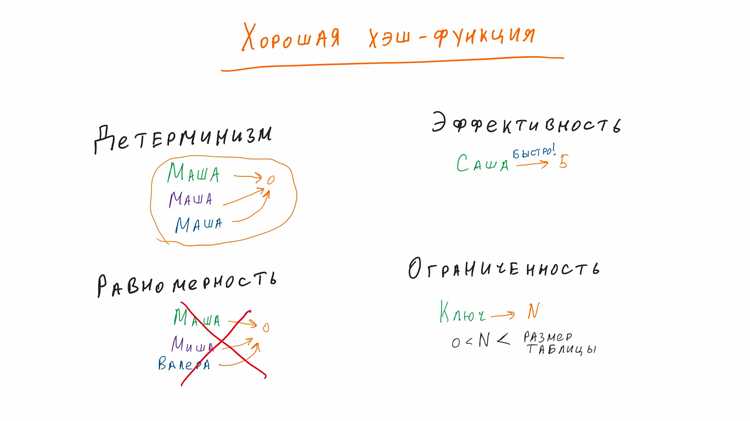
Протестировать и отладить хеш таблицу на Python можно с помощью нескольких методов, которые позволяют выявить ошибки и убедиться в правильности работы структуры данных.
1. Проверка на коллизии
Основная проблема хеш таблицы – коллизии. Чтобы протестировать их обработку, создайте несколько записей, которые должны попадать в одну и ту же корзину. Для этого можно использовать простые функции хеширования и тестировать поведение таблицы при добавлении одинаковых хешей. Например, для ключей с одинаковыми хешами добавляйте элементы с использованием разных стратегий (цепочек или открытой адресации) и проверяйте корректность их сохранения.
2. Проверка на производительность
Важно протестировать, как ваша таблица справляется с большим количеством данных. Сгенерируйте большой набор случайных данных и измерьте время вставки, поиска и удаления элементов. Это поможет убедиться, что хеш таблица не теряет в производительности при увеличении размера.
3. Тестирование на дублирование ключей
Если ваша таблица не должна позволять дублирование ключей, тестируйте эту логику. Попробуйте вставить один и тот же ключ несколько раз и проверьте, что значения не дублируются, а обновляются. Если таблица поддерживает уникальность ключей, результатом каждой вставки должен быть тот же элемент с обновленными значениями.
4. Тестирование на корректность удаления
Для проверки правильности удаления элементов добавьте в таблицу несколько элементов, затем удалите их и убедитесь, что они больше не могут быть найдены. Обратите внимание на возможное влияние на структуру таблицы, если элемент был удален, но его место не было корректно освобождено (например, при использовании открытой адресации).
5. Проверка на работу с пустыми и краевыми случаями
Проверьте работу хеш таблицы при добавлении, удалении и поиске элементов в пустой таблице. Также стоит проверить, как она ведет себя при экстремальных значениях (например, при использовании максимальных или минимальных возможных значений ключей).
6. Логирование и отладка
Для удобства отладки полезно добавить логирование на ключевых этапах: при вставке, удалении и поиске элементов. Это поможет отслеживать внутреннее состояние таблицы, а также выявить возможные ошибки в алгоритмах хеширования или обработке коллизий.
7. Юнит-тесты
Напишите юнит-тесты для каждой операции: вставки, удаления и поиска. Каждый тест должен проверять различные сценарии, включая те, что касаются коллизий, пустой таблицы и обновлений значений. Используйте фреймворки для тестирования, такие как unittest или pytest, для автоматической проверки корректности работы таблицы на каждом этапе разработки.
8. Проверка хеш-функции
Проверьте, что выбранная хеш-функция равномерно распределяет элементы по корзинам. Для этого используйте статистику для измерения распределения ключей и убедитесь, что некоторые корзины не перегружены, а другие – пусты.
Вопрос-ответ:
Что такое хеш таблица и как она работает?
Хеш таблица — это структура данных, которая используется для быстрого поиска, вставки и удаления элементов. Она работает на основе хеш-функции, которая преобразует ключ в индекс массива, по которому можно найти значение. Хеш таблица обеспечивает быстрый доступ к данным, так как операции поиска выполняются за время O(1) в большинстве случаев, если хорошо подобрана хеш-функция.
Что такое коллизии в хеш таблицах и как их можно решить?
Коллизия возникает, когда два разных ключа в хеш таблице дают одинаковый индекс. Чтобы решить эту проблему, применяются различные методы. Одним из них является метод цепочек, когда каждый элемент таблицы становится началом списка, в который добавляются все элементы с одинаковым хешом. Другим методом является метод открытой адресации, при котором ищется следующий свободный индекс для хранения данных.
Как выбрать хеш-функцию для хеш таблицы?
Хеш-функция должна быть достаточно простой и быстрой для вычисления, а также равномерно распределять ключи по всей таблице, чтобы минимизировать количество коллизий. Например, для строк можно использовать встроенную функцию `hash()`, но при необходимости можно разработать свою функцию, которая будет учитывать особенности данных. Важно, чтобы хеш-функция была детерминированной (для одинаковых входных данных всегда должен быть один и тот же хеш) и эффективно распределяла данные по таблице.
Что такое хеш таблица и как она работает в Python?
Хеш таблица — это структура данных, которая позволяет эффективно хранить и извлекать элементы по ключу. В Python для этого можно использовать встроенный тип данных `dict`. Хеш таблица работает с помощью хеш-функции, которая преобразует ключ в индекс массива, по которому можно получить соответствующее значение. Важным моментом является то, что хеш-функция должна равномерно распределять ключи, чтобы избежать коллизий — ситуации, когда два разных ключа имеют одинаковый хеш. Если коллизия все же возникает, обычно применяется метод цепочек или открытой адресации.