

Работа с алфавитом в Python – это одна из самых простых, но в то же время важных задач при программировании. Независимо от того, создаете ли вы генераторы паролей, обрабатываете текстовые данные или пишете код для криптографических приложений, понимание того, как правильно работать с буквами алфавита, может существенно упростить задачу. В Python это можно сделать несколькими способами, используя встроенные функции и методы, которые помогут вам эффективно обходить буквы по порядку.
Первым шагом будет использование стандартных функций для работы с символами. В Python буквы можно представлять как символы в строках или числа с помощью функции ord(), которая преобразует символ в его числовое представление по кодировке ASCII. Также для обратного преобразования существует функция chr(), которая позволяет превратить числовое значение обратно в символ. Этот подход используется во многих алгоритмах, таких как сортировка букв или нахождение их позиций в строках.
Для обхода алфавита по порядку удобно использовать range() и chr() вместе. Например, чтобы получить список всех букв английского алфавита от ‘a’ до ‘z’, достаточно пройтись по диапазону чисел, преобразуя их в символы. В Python этот процесс занимает несколько строк кода и позволяет эффективно работать с буквами в любом проекте.
Кроме того, Python предоставляет удобные структуры данных, такие как списки и кортежи, которые позволяют хранить и манипулировать алфавитом. Используя списки, можно легко осуществлять любые операции, такие как поиск, замена или сортировка букв, без дополнительных усилий. На практике это особенно полезно, если нужно работать не только с простыми буквами, но и с их комбинациями или фразами.
Как создать строку алфавита с помощью Python
Для создания строки, содержащей все буквы алфавита, в Python можно использовать несколько методов. Один из самых простых способов – воспользоваться встроенными функциями и модулями языка.
Первый способ – использование встроенной строки с символами. Например, для английского алфавита можно напрямую задать строку:
'abcdefghijklmnopqrstuvwxyz'
Однако такой подход не подходит, если необходимо динамично генерировать алфавит или работать с другими языками. В этом случае лучше использовать модуль string.
Модуль string предоставляет строку с буквами английского алфавита, как в нижнем, так и в верхнем регистре. Для получения строки с маленькими буквами достаточно воспользоваться атрибутом string.ascii_lowercase:
import string alphabet = string.ascii_lowercase print(alphabet)
Результат будет следующим: abcdefghijklmnopqrstuvwxyz.
Для создания строки с большими буквами можно использовать string.ascii_uppercase:
alphabet_upper = string.ascii_uppercase print(alphabet_upper)
Это вернет строку ABCDEFGHIJKLMNOPQRSTUVWXYZ.
Если требуется получить алфавит для других языков, например, для кириллицы, то для этого можно использовать цикл с функцией chr(), которая генерирует символ по его Unicode-коду. Например, для создания строки русского алфавита:
alphabet_russian = ''.join(chr(i) for i in range(ord('а'), ord('я') + 1))
print(alphabet_russian)
Этот код создаст строку с маленькими буквами русского алфавита: абвгдеёжзийклмнопрстуфхцчшщыэюя.
Для создания строки с большими буквами русского алфавита, аналогично можно использовать другой диапазон Unicode:
alphabet_russian_upper = ''.join(chr(i) for i in range(ord('А'), ord('Я') + 1))
print(alphabet_russian_upper)
Результатом будет строка: АБВГҐДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЫЭЮЯ.
Таким образом, использование модуля string и функций работы с символами Unicode позволяет гибко создавать строки с алфавитами, адаптированными под нужды конкретного проекта.
Использование функции range() для итерации по символам
Чтобы пройтись по алфавиту с помощью range(), можно использовать коды символов в диапазоне от 97 (код для ‘a’) до 122 (код для ‘z’). Например, следующий код позволяет напечатать все строчные буквы латинского алфавита:
for i in range(97, 123):
print(chr(i), end=" ")
Здесь функция range(97, 123) генерирует последовательность чисел от 97 до 122, которые затем преобразуются в символы через chr(i). Таким образом, можно итерировать по алфавиту шаг за шагом.
Важно помнить, что range() работает только с числами, поэтому для символов требуется использование ord() для получения кода символа и chr() для его преобразования обратно в символ.
Кроме того, если требуется пройтись по алфавиту в обратном порядке, можно изменить шаг в функции range(), установив его в -1:
for i in range(122, 96, -1):
print(chr(i), end=" ")
Этот код пройдет по буквам алфавита от ‘z’ до ‘a’. Использование range() в сочетании с chr() и ord() позволяет гибко управлять итерацией по символам, а также легко адаптировать решение для различных типов символов, например, для прописных или специальных символов.
Перебор букв с помощью цикла for в Python

Для перебора букв строки можно использовать следующий код:
text = "Привет"
for letter in text:
print(letter)
Этот код пройдет по каждой букве строки «Привет» и выведет ее на экран. Переменная letter будет принимать значение каждого символа строки на каждом шаге цикла.
Если нужно пройти по диапазону символов, например, от ‘a’ до ‘z’, можно использовать функцию chr() для получения символов по их ASCII-кодам:
for i in range(97, 123): # от 'a' до 'z'
print(chr(i))
Здесь range(97, 123) генерирует числа от 97 (код символа ‘a’) до 122 (код символа ‘z’). Функция chr(i) преобразует эти числа обратно в символы.
Для перебора букв в строках с учетом регистра или в определенном диапазоне можно использовать встроенные методы строк. Например, чтобы пройтись только по буквам верхнего регистра, можно фильтровать строку с помощью isupper():
text = "ПрИвет"
for letter in text:
if letter.isupper():
print(letter)
Такой код выведет только заглавные буквы из строки.
Цикл for идеально подходит для работы с буквами в строках, что делает код читаемым и понятным. Важно помнить, что перебор символов не ограничен только строками, вы можете комбинировать его с любыми другими итерабельными объектами в Python, например, списками или множествами.
Как получить символ по его индексу в алфавите
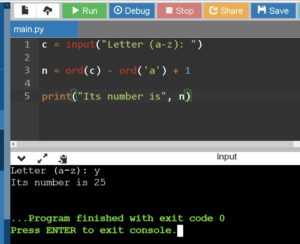
Чтобы получить символ по его индексу в алфавите, можно использовать встроенные функции Python для работы с символами и строками. Алфавит на языке Python можно представить как строку, где буквы идут подряд: «abcdefghijklmnopqrstuvwxyz». Индексы в строках начинаются с 0, поэтому буква ‘a’ будет иметь индекс 0, ‘b’ – индекс 1, и так далее.
Для получения символа по индексу достаточно использовать оператор индексации. Например, чтобы получить 5-й символ (букву ‘f’), нужно выполнить:
alphabet = "abcdefghijklmnopqrstuvwxyz" char = alphabet[5] # 'f'
Если вам нужно учесть большие буквы, можно просто использовать строку, содержащую все буквы в верхнем регистре:
alphabet_upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" char_upper = alphabet_upper[5] # 'F'
Если необходимо обработать индексы, выходящие за пределы алфавита, можно воспользоваться проверкой условий, чтобы избежать ошибок IndexError:
index = 30 if 0 <= index < len(alphabet): char = alphabet[index] else: char = None # Индекс вне диапазона
Также можно написать функцию для получения символа по индексу, которая будет работать как для обычных, так и для заглавных букв:
def get_char_by_index(index, uppercase=False): alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if uppercase else "abcdefghijklmnopqrstuvwxyz" if 0 <= index < len(alphabet): return alphabet[index] return None
В этой функции можно настроить выбор регистра букв, что позволит гибко работать с алфавитом в зависимости от нужд программы.
Итерация по алфавиту с использованием list comprehension

В Python строка, состоящая из символов, является итерируемым объектом. Мы можем пройтись по всем буквам алфавита и, используя list comprehension, создать список, содержащий все буквы или их вариации. Например, можно создать список с маленькими буквами от 'a' до 'z'.
alphabet = [chr(i) for i in range(ord('a'), ord('z') + 1)]
print(alphabet)
В этом примере функция ord() возвращает ASCII код символа, а chr() преобразует число обратно в символ. Использование range() позволяет задать диапазон, от которого мы и будем генерировать буквы.
ord('a')возвращает 97,ord('z')– 122.- Параметры
range()от 97 до 123 (включая 97, но не включая 123) создают диапазон, который охватывает все буквы от 'a' до 'z'.
Можно также изменить регистр букв или применить к ним дополнительные преобразования. Например, чтобы получить список заглавных букв:
uppercase_alphabet = [chr(i).upper() for i in range(ord('a'), ord('z') + 1)]
print(uppercase_alphabet)
В данном случае метод upper() применяется к каждому символу перед добавлением в список.
Еще один вариант – создать список, содержащий только те буквы, которые находятся на четных позициях:
even_position_letters = [chr(i) for i in range(ord('a'), ord('z') + 1) if (i - ord('a')) % 2 == 0]
print(even_position_letters)
- В условии
if (i - ord('a')) % 2 == 0проверяется, является ли индекс буквы четным.
Используя list comprehension, можно также легко создать списки с буквами в обратном порядке:
reverse_alphabet = [chr(i) for i in range(ord('z'), ord('a') - 1, -1)]
print(reverse_alphabet)
- Диапазон
range(ord('z'), ord('a') - 1, -1)указывает на последовательность от 'z' до 'a' с шагом -1.
Таким образом, list comprehension является удобным и эффективным способом работы с алфавитом, позволяя гибко управлять созданием и преобразованием списков.
Как работать с регистром букв при обходе алфавита
При работе с алфавитом в Python важно учитывать регистр букв, так как символы в верхнем и нижнем регистре могут интерпретироваться как разные. Чтобы избежать ошибок, нужно четко понимать, как манипулировать регистром и какие методы предоставляет Python для этого.
Для начала стоит понимать, что строковые методы Python, такие как lower() и upper(), позволяют легко преобразовывать регистр символов.
str.lower()– преобразует все символы строки в нижний регистр.str.upper()– преобразует все символы строки в верхний регистр.str.swapcase()– меняет регистр на противоположный (верхний на нижний и наоборот).
Пример преобразования всех букв в алфавите в нижний и верхний регистры:
import string
# Алфавит в нижнем регистре
lowercase = string.ascii_lowercase
print(lowercase)
# Алфавит в верхнем регистре
uppercase = string.ascii_uppercase
print(uppercase)
Если необходимо пройтись по алфавиту и выполнить операции с буквами разного регистра, можно использовать цикл. Например, чтобы получить все буквы алфавита в обоих регистрах:
for letter in string.ascii_lowercase + string.ascii_uppercase:
print(letter)
Важное замечание: Python учитывает регистр при сравнении строк и символов. Например, 'a' == 'A' вернет False. Чтобы сделать сравнение независимым от регистра, применяйте метод lower() или upper() к обоим строкам перед сравнением:
if letter1.lower() == letter2.lower():
print("Буквы одинаковы, не зависимо от регистра.")
При необходимости выполнять операции только с буквами определенного регистра, полезно будет фильтровать буквы до выполнения операций. Например:
# Вывести только заглавные буквы
for letter in string.ascii_letters:
if letter.isupper():
print(letter)
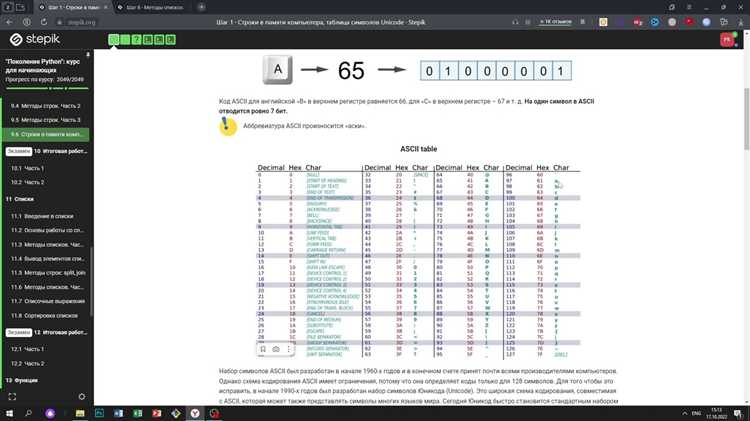
Также важно учитывать, что некоторые функции, такие как ord() и chr(), возвращают числовые значения символов. При работе с такими функциями регистр влияет на результат. Например:
# Преобразуем символ в его числовой код
print(ord('a')) # 97
print(ord('A')) # 65
Таким образом, при обходе алфавита важно осознавать, когда регистр имеет значение, а когда можно проигнорировать различия. Методы Python позволяют гибко работать с регистрами, что делает работу с текстовыми данными более эффективной и удобной.
Как реализовать перебор букв с учётом дополнительных символов
В Python перебор символов в алфавите можно расширить, добавив в него дополнительные символы, такие как цифры, знаки препинания или другие специальные символы. Для этого можно воспользоваться несколькими подходами, в зависимости от задачи.
Один из простых способов – это использовать строку, которая включает в себя все необходимые символы. Например, можно создать строку, состоящую из букв алфавита и дополнительных символов:
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()"
Теперь для перебора этих символов можно использовать стандартный цикл for:
for char in alphabet: print(char)
Если нужно перебирать символы по их порядку, можно воспользоваться функцией ord(), которая возвращает числовое представление символа. Например, для перебора символов ASCII, включая буквы и дополнительные знаки:
for code in range(ord('a'), ord('z')+1):
print(chr(code))
Этот код выведет буквы от 'a' до 'z'. Для добавления дополнительных символов можно использовать объединение строк или числовых диапазонов, например:
for code in range(ord('a'), ord('z')+1):
print(chr(code))
for code in range(33, 48): # Специальные символы от '!' до '/'
print(chr(code))
При необходимости добавить символы с другими кодировками, можно использовать строки Unicode, например, для добавления символов из разных языков или специальных символов:
special_chars = "АБВГДЕЖЗ" for char in special_chars: print(char)
Если перебор требует динамического изменения символов, можно создать генератор или использовать функцию itertools.chain(), чтобы комбинировать различные последовательности:
import itertools alphabet = "abc" digits = "123" symbols = "!@#" for char in itertools.chain(alphabet, digits, symbols): print(char)
Таким образом, перебор букв с учётом дополнительных символов в Python можно легко адаптировать под конкретные задачи, комбинируя строки, диапазоны и специальные модули, такие как itertools, для более сложных случаев.
Использование библиотеки string для генерации алфавита
В Python библиотека string предоставляет удобные инструменты для работы с текстовыми данными. Она включает несколько предопределённых строковых констант, среди которых есть и алфавитные символы. Это позволяет легко и быстро генерировать алфавит, не прибегая к ручному написанию кода для каждого символа.
Для получения алфавита можно использовать строку string.ascii_lowercase, которая содержит все строчные буквы латинского алфавита от 'a' до 'z'. Если вам нужен алфавит в верхнем регистре, можно обратиться к строке string.ascii_uppercase.
Пример использования для генерации алфавита:
import string
Строчные буквы
lowercase_alphabet = string.ascii_lowercase
print(lowercase_alphabet)
Заглавные буквы
uppercase_alphabet = string.ascii_uppercase
print(uppercase_alphabet)Кроме того, библиотека string позволяет получить и другие полезные строки, например, string.ascii_letters для всех букв, как строчных, так и заглавных. Эти строки можно использовать в различных задачах, например, для генерации случайных строк или проверки символов.
Если требуется только набор букв без цифр или символов, использование string.ascii_lowercase или string.ascii_uppercase является наиболее простым и быстрым решением. Однако если нужно работать с различными наборами символов, например, с алфавитом с учётом дополнительных символов или модификаций, то библиотека string обеспечит все необходимые ресурсы.





