Работа с матрицами в Python важна для анализа данных, особенно когда нужно эффективно управлять большими объемами числовых данных. В языке Python для этого идеально подходят библиотеки NumPy и pandas, которые предоставляют широкие возможности для манипуляции с матричными структурами и выполнения математических операций.
Основной инструмент для работы с матрицами в Python – это объект numpy.ndarray, который позволяет эффективно выполнять операции с многомерными массивами. Например, создание матрицы из списка данных можно выполнить с помощью функции numpy.array(), что сразу преобразует данные в форму, пригодную для числовых операций и анализа.
При анализе данных важно понимать, что матрицы в Python могут быть использованы не только для базовых вычислений, но и для более сложных операций, таких как свертка, линейная алгебра или решение систем линейных уравнений. NumPy предоставляет функции для трансформаций, таких как транспонирование (.T) и вычисление определителя (numpy.linalg.det()), что упрощает обработку и анализ данных.
Библиотека pandas дополнительно предлагает более высокоуровневые абстракции, такие как DataFrame, что делает удобным работу с матрицами, когда данные содержат метки для строк и столбцов. Это особенно полезно при работе с реальными наборами данных, где важно учитывать не только числовые значения, но и связанные с ними метки.
Создание и инициализация матриц с использованием NumPy

NumPy предоставляет несколько способов создания и инициализации матриц для анализа данных. Главное – выбрать подходящий метод в зависимости от задачи и требуемой структуры данных.
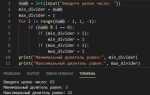
Использование np.array() – самый универсальный способ. Для создания матрицы достаточно передать в функцию список списков. Например:
import numpy as np
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matrix)Этот код создаёт 3×3 матрицу, где каждый вложенный список представляет строку.
Заполнение матрицы числами с фиксированными значениями – такие функции, как np.zeros(), np.ones() и np.full(), позволяют создать матрицу с заранее заданными значениями. Например:
zero_matrix = np.zeros((3, 3)) # 3x3 матрица, заполненная нулями
one_matrix = np.ones((2, 4)) # 2x4 матрица, заполненная единицами
full_matrix = np.full((2, 3), 7) # 2x3 матрица, заполненная семёркамиГенерация матрицы с случайными числами также возможна с помощью np.random.rand(), np.random.randint() и других функций из библиотеки random. Например:
random_matrix = np.random.rand(3, 3) # 3x3 матрица с числами от 0 до 1
int_random_matrix = np.random.randint(0, 10, (3, 3)) # 3x3 матрица с целыми числами от 0 до 10Инициализация матриц с линейными данными возможна с помощью np.arange(), которая создаёт массив чисел, а затем reshape преобразует его в матрицу. Пример:
range_matrix = np.arange(1, 10).reshape(3, 3) # Преобразует одномерный массив в 3x3 матрицуДиагональные матрицы создаются с помощью np.diag(), где можно задать элементы на главной диагонали:
diag_matrix = np.diag([1, 2, 3]) # 3x3 диагональная матрицаДля работы с большими наборами данных или при необходимости выполнить операцию многократного умножения значений, NumPy также предлагает функции np.eye() для создания единичной матрицы и np.diagflat() для преобразования одномерных массивов в диагональные матрицы.
Выбор метода зависит от задач. При создании больших данных с нужной структурой стоит учитывать оптимизацию по памяти и скорости выполнения.
Основные операции с матрицами: сложение, вычитание и умножение
Для работы с матрицами в Python часто используют библиотеку NumPy, которая предоставляет удобные функции для выполнения математических операций.
Сложение матриц возможно, если размеры матриц совпадают. При сложении элементы, расположенные на одинаковых позициях, складываются между собой. Пример:
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
C = A + B
print(C)
Результат:
[[ 6 8]
[10 12]]
Вычитание матриц работает по аналогии со сложением. Чтобы вычесть одну матрицу из другой, их размеры должны совпадать. Разность матриц получается путём вычитания соответствующих элементов:
import numpy as np
A = np.array([[9, 8], [7, 6]])
B = np.array([[5, 4], [3, 2]])
C = A - B
print(C)
Результат:
[[4 4]
[4 4]]
Умножение матриц выполняется по правилам линейной алгебры. Чтобы умножить две матрицы, количество столбцов первой матрицы должно быть равно количеству строк второй. В Python для этого используется функция np.dot() или оператор @:
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
C = np.dot(A, B) # или C = A @ B
print(C)
Результат:
[[19 22]
[43 50]]
Важно помнить, что при умножении матрицы на скаляр, каждый элемент матрицы умножается на этот скаляр:
import numpy as np
A = np.array([[1, 2], [3, 4]])
C = 3 * A
print(C)
Результат:
[[3 6]
[9 12]]
Основные операции с матрицами в Python при помощи NumPy позволяют быстро и эффективно решать задачи анализа данных.
Индексирование и срезы матриц для извлечения данных

В Python для работы с матрицами используется библиотека NumPy. Матрицы представляют собой двумерные массивы, и для извлечения данных из них применяется индексирование и срезы.
Индексирование в NumPy позволяет обратиться к отдельным элементам матрицы с использованием пары индексов. Например, для матрицы `A`, чтобы получить элемент, расположенный в третьей строке и втором столбце, используется следующая запись: `A[2, 1]`. Индексация начинается с нуля, что важно учитывать при работе с большими данными.
Срезы матриц полезны для извлечения подматриц. Срезы в NumPy применяются с использованием двоеточия в квадратных скобках. Например, чтобы получить все строки, начиная с третьей, и все столбцы до пятого, следует записать: `A[2:, :5]`. Важно понимать, что срез не включает элемент с конечным индексом, то есть в данном случае столбец с индексом 5 будет исключён.
Можно комбинировать индексирование и срезы для более точного извлечения данных. Например, чтобы получить подматрицу, состоящую из строк с индексами от 1 до 3 и столбцов с индексами от 0 до 2, следует использовать конструкцию: `A[1:4, 0:3]`.
Для извлечения всей строки или столбца, достаточно указать только один индекс. Например, `A[1, :]` вернёт всю вторую строку, а `A[:, 2]` – все элементы третьего столбца.
Особенность срезов в том, что они создают «вид» на исходные данные, а не копию. Это означает, что изменения, внесённые в срез, будут отражаться в оригинальной матрице. Чтобы создать копию данных, используется метод `.copy()`, например: `A[1:3, 2:4].copy()`.
Индексирование также поддерживает логические маски, что даёт возможность извлекать данные по условию. Например, чтобы получить все элементы, которые больше 10, можно использовать: `A[A > 10]`.
Понимание этих методов индексирования и срезов матриц в Python позволяет эффективно работать с большими массивами данных и легко извлекать нужную информацию для анализа.
Транспонирование и инвертирование матриц в Python
В Python работа с матрицами часто требует их преобразования. Транспонирование и инвертирование – два распространённых метода, которые используются для изменения структуры данных и решения задач линейной алгебры.
Транспонирование матрицы представляет собой изменение строк на столбцы. В Python для этого можно использовать библиотеку NumPy, которая предоставляет удобные функции для работы с многомерными массивами. Для транспонирования матрицы достаточно вызвать метод transpose() или использовать атрибут .T.
Пример транспонирования матрицы:
import numpy as np
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
transposed_matrix = matrix.T
print(transposed_matrix)На выходе получится новая матрица, где строки будут заменены на столбцы:
[[1 4 7]
[2 5 8]
[3 6 9]]Инвертирование матрицы возможно только для квадратных матриц, у которых определитель не равен нулю. Чтобы инвертировать матрицу, можно использовать функцию inv() из библиотеки NumPy. Эта функция вычисляет обратную матрицу, которая при умножении на исходную даёт единичную матрицу.
Пример инвертирования матрицы:
matrix = np.array([[1, 2], [3, 4]])
inverted_matrix = np.linalg.inv(matrix)
print(inverted_matrix)В случае, если матрица сингулярна (ее определитель равен нулю), функция inv() вызовет ошибку. Чтобы избежать этого, можно предварительно проверить определитель матрицы с помощью np.linalg.det(). Если определитель равен нулю, инвертировать такую матрицу не получится.
Пример проверки определителя:
det = np.linalg.det(matrix)
if det != 0:
inverted_matrix = np.linalg.inv(matrix)
else:
print("Матрица сингулярна и не может быть инвертирована.") Таким образом, транспонирование и инвертирование матриц в Python с использованием NumPy – эффективные инструменты для манипуляций с данными и решения математических задач. Важно помнить о существующих ограничениях при инвертировании матриц и следить за их свойствами.
Решение систем линейных уравнений с помощью матриц
Решение системы линейных уравнений можно выразить через матричное представление, что упрощает вычисления и позволяет эффективно работать с большими данными. Рассмотрим систему уравнений вида:
A * X = B,
где A – это матрица коэффициентов системы, X – вектор неизвестных, а B – вектор правых частей уравнений.
Для нахождения вектора X можно использовать следующую формулу:
X = A-1 * B,
где A-1 – это обратная матрица к матрице A, если она существует. Обратная матрица существует только в случае, если определитель матрицы A не равен нулю.
В Python для решения таких систем часто используется библиотека NumPy, которая предоставляет функцию numpy.linalg.solve для эффективного решения линейных систем. Рассмотрим пример:
import numpy as np
# Коэффициенты системы
A = np.array([[2, 1], [5, 7]])
# Правая часть системы
B = np.array([11, 13])
# Решение системы
X = np.linalg.solve(A, B)
print(X)Этот код решит систему двух уравнений с двумя неизвестными. Функция solve вычисляет вектор X, который является решением системы. Она использует эффективные численные методы для нахождения решения.
Если матрица A не обратима (например, если её определитель равен нулю), то решение может не существовать или быть неединственным. В таких случаях можно использовать псевдообратную матрицу, которая вычисляется с помощью функции numpy.linalg.pinv:
pseudo_inverse = np.linalg.pinv(A)
X = pseudo_inverse.dot(B)
print(X)Этот метод подходит для решений в случаях, когда система имеет бесконечно много решений или её решение не существует в обычном смысле.
Важно помнить, что использование матричных методов предполагает, что система уравнений имеет решение, а также что она не является вырожденной, что может требовать проверки условий на определитель матрицы или её ранк.
Агрегация данных в матрицах: суммирование, усреднение и другие методы
При анализе данных часто необходимо сводить информацию из больших матриц в более компактную форму для последующего анализа. Для этого используют различные методы агрегации данных, такие как суммирование, усреднение, нахождение максимума и минимума. В Python для работы с матрицами идеально подходит библиотека NumPy, которая предоставляет инструменты для быстрого выполнения таких операций.
Суммирование данных
Суммирование элементов матрицы может быть выполнено как по строкам, так и по столбцам. Для этого используется функция np.sum().
- Для суммирования всех элементов матрицы:
np.sum(matrix). - Для суммирования по строкам:
np.sum(matrix, axis=1). - Для суммирования по столбцам:
np.sum(matrix, axis=0).
Например, если нужно найти сумму всех значений в матрице с размерами 3×3, можно использовать:
import numpy as np
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
total_sum = np.sum(matrix)Усреднение данных

Среднее значение по строкам или столбцам также вычисляется с помощью np.mean().
- Для вычисления среднего значения всех элементов:
np.mean(matrix). - Для усреднения по строкам:
np.mean(matrix, axis=1). - Для усреднения по столбцам:
np.mean(matrix, axis=0).
Пример:
average_value = np.mean(matrix)Поиск максимума и минимума
Для нахождения максимума и минимума можно использовать функции np.max() и np.min().
- Для нахождения максимума:
np.max(matrix). - Для нахождения минимума:
np.min(matrix). - Для поиска максимума по строкам:
np.max(matrix, axis=1). - Для поиска минимума по столбцам:
np.min(matrix, axis=0).
Другие методы агрегации
- Медиана: Для вычисления медианы используется
np.median(). Это полезно, когда нужно исключить влияние выбросов в данных. - Стандартное отклонение: Для оценки разброса данных можно вычислить стандартное отклонение с помощью
np.std(). - Медианный абсолютный отклонение:
np.median(np.abs(matrix - np.median(matrix))).
Пример комплексной агрегации
Предположим, у нас есть матрица с данными о продажах за несколько месяцев в разных регионах. Мы можем вычислить сумму, среднее, максимум и минимум по столбцам, чтобы проанализировать тенденции продаж по регионам.
sales_data = np.array([[100, 200, 150], [120, 210, 170], [130, 220, 160]])
column_sums = np.sum(sales_data, axis=0)
column_mean = np.mean(sales_data, axis=0)
column_max = np.max(sales_data, axis=0)
column_min = np.min(sales_data, axis=0)Использование матриц для выполнения сингулярного разложения (SVD)
Сингулярное разложение (SVD) используется для анализа и обработки матриц, особенно в контексте снижения размерности, обработки данных и машинного обучения. Этот метод разлагает любую матрицу \( A \) размером \( m \times n \) на три компоненты:
- Матрица \( U \) размером \( m \times m \) – ортогональная матрица, содержащая левые сингулярные векторы.
- Диагональная матрица \( \Sigma \) размером \( m \times n \), на диагонали которой находятся сингулярные числа.
- Матрица \( V^T \) размером \( n \times n \) – ортогональная матрица, содержащая правые сингулярные векторы (транспонированную матрицу \( V \)).
Таким образом, исходная матрица \( A \) раскладывается как:
\( A = U \Sigma V^T \)
Для выполнения SVD в Python можно использовать библиотеку NumPy. Рассмотрим пример:
import numpy as np
# Пример матрицы A
A = np.array([[1, 2, 3], [4, 5, 6]])
# Выполнение сингулярного разложения
U, S, VT = np.linalg.svd(A)
# Преобразование S в диагональную матрицу
Sigma = np.zeros_like(A, dtype=float)
Sigma[:len(S), :len(S)] = np.diag(S)
print("U:", U)
print("Sigma:", Sigma)
print("V^T:", VT)После выполнения кода, вы получите три матрицы: \( U \), \( \Sigma \), и \( V^T \). Если требуется восстановить исходную матрицу, можно использовать:
A_reconstructed = np.dot(U, np.dot(Sigma, VT))
print(A_reconstructed)Практическое применение SVD включает:
- Снижение размерности данных: SVD помогает выделить главные компоненты и исключить менее важные признаки.
- Рекомендательные системы: SVD используется для анализа матриц предпочтений и построения персонализированных рекомендаций.
- Обработка изображений: SVD помогает сжать изображения, удаляя незначительные компоненты и уменьшая размерность.
Важный момент при работе с SVD: численные ошибки могут возникать при вычислениях для больших матриц. Это особенно важно, когда требуется точность в высоких измерениях. В таких случаях стоит обратить внимание на методы регуляризации и использование более устойчивых алгоритмов.
Оптимизация вычислений с большими матрицами в Python

Использование памяти играет ключевую роль при работе с большими данными. Важно понимать, как управлять памятью при манипуляциях с матрицами. Одним из методов оптимизации является использование типизированных массивов. В отличие от стандартных списков Python, массивы NumPy занимаются выделением памяти для всех элементов заранее, что позволяет ускорить операции с матрицами. Также можно использовать параметр dtype для задания более компактных типов данных (например, float32 вместо float64), если точность позволяет.
Для оптимизации многозадачности в Python можно использовать многопроцессорность или параллельные вычисления. Библиотека joblib позволяет эффективно распределять задачи по нескольким процессам, а concurrent.futures – запускать вычисления параллельно, что значительно ускоряет выполнение операций над большими матрицами.
Применение методов сжатия данных также позволяет эффективно работать с большими массивами. Например, можно использовать sparse-матрицы, которые хранят только ненулевые элементы, что значительно снижает потребление памяти и ускоряет операции. Библиотека scipy.sparse предоставляет удобные способы работы с разреженными матрицами, такими как csr_matrix или csc_matrix.
Если задача требует многократного выполнения одних и тех же операций над матрицами, стоит рассмотреть возможность использования предварительных вычислений или кеширования. Модуль functools.lru_cache позволяет кэшировать результаты функции, что ускоряет последующие вызовы с теми же аргументами.
Для задач линейной алгебры следует использовать специально оптимизированные функции, такие как numpy.dot() для произведения матриц или numpy.linalg.inv() для вычисления обратных матриц. Эти функции используют алгоритмы с более высокой производительностью по сравнению с их реализациями в чистом Python.
При работе с очень большими матрицами, которые не помещаются в оперативную память, можно использовать технологии, такие как Dask, которая позволяет работать с массивами, распределёнными на нескольких машинах, или CuPy, использующую GPU для ускорения вычислений.
Вопрос-ответ:
Как начать работать с матрицами в Python для анализа данных?
Для начала работы с матрицами в Python необходимо использовать библиотеку NumPy, которая предоставляет удобные инструменты для работы с многомерными массивами. Матрицы в Python представляются как двумерные массивы. Чтобы начать, нужно импортировать библиотеку NumPy, используя команду `import numpy as np`, а затем создать матрицу с помощью функции `np.array()`. Например, чтобы создать матрицу 2×3, можно написать `A = np.array([[1, 2, 3], [4, 5, 6]])`. Это позволит вам эффективно выполнять различные операции, такие как сложение, умножение и транспонирование матриц.
Какие операции можно выполнять с матрицами в Python для анализа данных?
С помощью библиотеки NumPy можно выполнять различные операции с матрицами. Например, можно складывать и вычитать матрицы, если их размеры совпадают, или умножать матрицы с помощью функции `np.dot()`. Также можно умножать матрицу на скаляр, транспонировать матрицу с помощью `np.transpose()` или `A.T`, вычислять определитель с помощью `np.linalg.det()`, находить обратную матрицу через `np.linalg.inv()`. В дополнение к этим базовым операциям, NumPy поддерживает операции элемент-wise, когда математическая операция применяется к каждому элементу матрицы по отдельности.
Что такое линейная алгебра и как она используется в анализе данных с помощью матриц в Python?
Линейная алгебра — это раздел математики, который изучает операции над векторами и матрицами. В контексте анализа данных линейная алгебра используется для работы с большими объемами данных, например, для решения систем линейных уравнений, выполнения свертки в нейронных сетях, а также для выполнения операций с признаками в методах машинного обучения. В Python для этих целей чаще всего используют библиотеку NumPy, которая оптимизирована для таких вычислений. Например, можно решать системы линейных уравнений с помощью `np.linalg.solve()`, а для вычисления собственных значений матрицы применяется `np.linalg.eig()`.
Как работать с матрицами разного размера в Python?
Когда работаешь с матрицами разного размера, важно учитывать их совместимость для выполнения математических операций. В NumPy это контролируется правилами размерности массивов. Например, если вы хотите перемножить матрицы, их размеры должны соответствовать: количество столбцов первой матрицы должно быть равно количеству строк второй. Для проверки размера матрицы можно использовать атрибут `shape`, который возвращает кортеж с числами, обозначающими количество строк и столбцов в матрице. Чтобы решить проблему несовпадения размеров, можно использовать методы, такие как транспонирование (`A.T`) или изменение формы матрицы с помощью `np.reshape()`.
Что такое матричное умножение и как его правильно использовать в Python?
Матричное умножение — это операция, в которой каждый элемент строки первой матрицы умножается на каждый элемент столбца второй матрицы, а результат складывается. Для правильного умножения матриц их размеры должны соответствовать: количество столбцов первой матрицы должно равняться количеству строк второй. В Python для матричного умножения используется функция `np.dot()` или оператор `@`. Например, если у нас есть две матрицы A и B, то их произведение можно вычислить как `C = np.dot(A, B)` или `C = A @ B`. Это важная операция в линейной алгебре, широко используемая в статистике и машинном обучении для работы с данными.