Массивы в Python представлены списками, и разбиение их на подмассивы – это распространённая операция при обработке данных, особенно при работе с батчами в машинном обучении, страницами в веб-приложениях и структурировании входных данных. Несмотря на кажущуюся простоту задачи, существует несколько способов реализации, и выбор зависит от конкретных требований: длина подмассивов, равномерность распределения, работа с остатками и оптимизация по скорости.
Если необходимо разделить список на подмассивы фиксированной длины, стандартным подходом считается использование срезов в генераторе: [original[i:i + size] for i in range(0, len(original), size)]. Этот способ прост и читаем, не требует подключения дополнительных модулей и подходит для большинства ситуаций. Однако он не обрабатывает случаи, когда список пуст или длина подмассивов некорректна, поэтому рекомендуется предусматривать проверки.
Для более гибкой работы, особенно при необходимости равномерного распределения элементов между подмассивами (например, деление на n групп), эффективным решением будет использование модуля numpy или itertools. numpy.array_split() позволяет разделить массив даже тогда, когда он не делится нацело, автоматически распределяя «остатки» по первым подмассивам. Это особенно важно при подготовке датасетов, где недопустим перекос в объёме данных между партиями.
Выбор способа разбиения напрямую влияет на производительность кода. При больших объёмах данных предпочтительно использовать генераторы или библиотечные функции, минимизирующие копирование и перераспределение памяти. Также важно учитывать неизменяемость объектов в списках: если подмассивы предполагается изменять, следует создавать их копии, чтобы избежать побочных эффектов.
Как разделить список на подсписки фиксированной длины

Чтобы разбить список на подсписки одинаковой длины, используйте срезы в сочетании с функцией range(). Это даёт полный контроль над размером групп и позволяет избежать лишних библиотек.
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
chunk_size = 3
chunks = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]
- Если длина списка не делится нацело, последний подсписок будет короче.
- Использование генератора списка обеспечивает высокую производительность.
- Нет необходимости проверять выход за пределы списка – срезы обрабатываются корректно.
Альтернативный способ – использовать itertools, если важна экономия памяти при работе с большими данными:
from itertools import islice
def split_chunks(iterable, size):
it = iter(iterable)
while chunk := list(islice(it, size)):
yield chunk
result = list(split_chunks(data, 3))
- Функция
islice()извлекает ровноsizeэлементов за итерацию. - Используется ленивое вычисление – подсписки формируются по мере запроса.
Избегайте ручного перебора с накоплением элементов в отдельный список – это увеличивает сложность кода и вероятность ошибок. Для задач с фиксированной длиной подсписков предпочтительнее использовать генераторы или срезы.
Разбиение списка на равные части с остатком
Когда длина списка не делится нацело на нужное количество частей, остаток можно распределить по-разному: равномерно, в начало, в конец или игнорировать. Один из эффективных подходов – добавлять по одному лишнему элементу в первые подмассивы.
Пример: список из 10 элементов нужно разбить на 3 части. Размер базовой части – 10 // 3 = 3, остаток – 10 % 3 = 1. Получим подмассивы с длинами: 4, 3, 3.
def split_with_remainder(lst, n):
k, m = divmod(len(lst), n)
return [lst[i * k + min(i, m):(i + 1) * k + min(i + 1, m)] for i in range(n)]
# Пример использования
data = list(range(10))
result = split_with_remainder(data, 3)
print(result) # [[0, 1, 2, 3], [4, 5, 6], [7, 8, 9]]
- divmod одновременно вычисляет частное и остаток.
- min(i, m) учитывает, сколько лишних элементов уже распределено.
- Функция возвращает список из
nподсписков с максимально равномерным распределением элементов.
Такой способ не требует сторонних библиотек, не нарушает порядок элементов и стабильно работает при любом размере исходного списка и количества частей.
Использование list comprehension для создания подмассивов
С помощью list comprehension можно легко и эффективно разбить массив на подмассивы. Этот метод позволяет создавать подмассивы заданного размера или по определённым критериям, избегая использования циклов и вспомогательных переменных.
Простейший пример – разбиение массива на подмассивы фиксированного размера. Допустим, есть массив, который нужно разделить на подмассивы по 4 элемента. Используя list comprehension, это можно сделать так:
«`python
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
size = 4
subarrays = [arr[i:i+size] for i in range(0, len(arr), size)]
В результате получится следующий список подмассивов:
pythonCopyEdit[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
Когда размер массива не делится нацело на размер подмассивов, последний подмассив может содержать меньше элементов, чем остальные. Это особенно важно учитывать при обработке данных, чтобы избежать потери информации.
List comprehension можно также использовать для создания подмассивов, удовлетворяющих определённым условиям. Например, если нужно получить подмассивы, содержащие только чётные числа:
pythonCopyEditarr = [1, 2]()
Разделение списка по условию элемента
Иногда требуется разделить список на подсписки, используя определенное условие для каждого элемента. Это может быть полезно, например, при группировке данных по категории или делении на элементы, удовлетворяющие определенным характеристикам.
Для реализации задачи можно воспользоваться встроенными возможностями Python, например, с помощью генераторов списков или функции itertools.groupby. Рассмотрим два способа решения задачи.
Способ 1: Использование генераторов списков
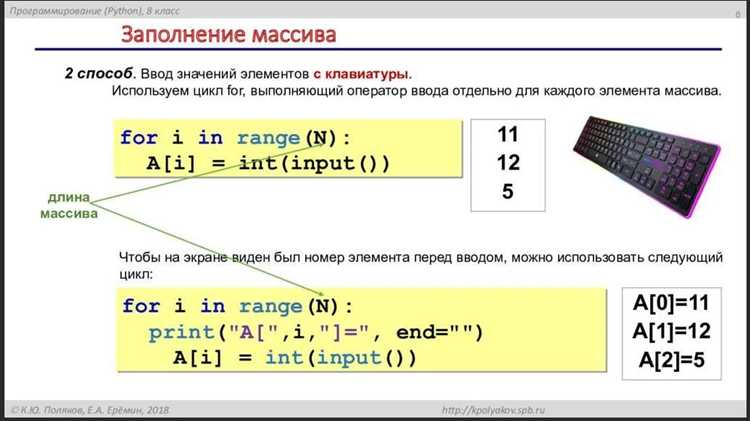
Допустим, нужно разделить список на подсписки, где каждый подсписок содержит элементы, удовлетворяющие одному и тому же условию. Например, разделим числа на четные и нечетные.
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
even_numbers = [n for n in numbers if n % 2 == 0]
odd_numbers = [n for n in numbers if n % 2 != 0]
В результате, переменная even_numbers будет содержать все четные числа из списка, а odd_numbers – все нечетные.
Способ 2: Использование itertools.groupby
![Способ 2: Использование undefineditertools.groupby</code>«></p>
<p>Для более сложных условий можно использовать функцию <code>groupby</code> из модуля <code>itertools</code>. Она позволяет группировать элементы списка по ключу, возвращаемому переданной функции. Важно отметить, что входной список должен быть отсортирован по ключу для корректной работы функции.</p>
<pre><code>
from itertools import groupby
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
grouped = groupby(numbers, key=lambda x: x % 2 == 0)
result = {key: list(group) for key, group in grouped}
</code></pre>
<p>В данном примере мы группируем числа по признаку четности. Результат будет словарем, где ключ <code>True</code> соответствует четным числам, а ключ <code>False</code> – нечетным.</p>
<h3>Рекомендации</h3>
<p>Для простых случаев, таких как разделение на четные и нечетные числа, удобнее использовать генераторы списков, так как этот подход проще и не требует предварительной сортировки списка.</p>
<p>В случае более сложных условий и необходимости группировки по нескольким признакам, лучше использовать <code>groupby</code>, особенно если элементы списка имеют несколько характеристик для разделения.</p>
<h2>Разбиение двумерного массива на блоки</h2>
<p>Для разбиения двумерного массива на блоки в Python часто используется срезы. Метод заключается в извлечении подмассивов из исходного массива по заданным индексам. Это позволяет эффективно работать с большими данными, разбивая их на более мелкие, что упрощает обработку и анализ.</p>
<p>Предположим, что у вас есть двумерный массив размером 8×8, и вы хотите разделить его на блоки размером 4×4. В Python для этого удобно использовать библиотеки, такие как NumPy, которые позволяют быстро манипулировать массивами.</p>
<p>Пример с использованием NumPy:</p>
<pre>
import numpy as np
# Исходный массив 8x8
array = np.arange(64).reshape(8, 8)
# Разбиение массива на блоки 4x4
blocks = [array[i:i+4, j:j+4] for i in range(0, array.shape[0], 4) for j in range(0, array.shape[1], 4)]
</pre>
<p>В данном примере используется вложенный цикл, который перебирает индексы массива с шагом 4. Это позволяет извлечь подмассивы размером 4×4, которые становятся блоками исходного массива. Такой подход применим и для других размеров блоков, достаточно изменить шаг цикла в зависимости от требуемого размера.</p>
<p>Важный момент: для корректного разбиения массив должен быть делим на размер блоков, иначе последний блок может быть неполным или привести к ошибкам в индексации. Если блоки могут быть переменной длины, дополнительно стоит обработать оставшиеся элементы.</p>
<p>Также можно использовать функцию <code>reshape</code> для изменения формы массива, чтобы блоки имели нужный размер, но при этом все элементы должны быть упорядочены так, чтобы не нарушить целостность данных.</p>
<p>Пример с использованием <code>reshape</code>:</p>
<pre>
array_reshaped = array.reshape(4, 2, 4, 2)
</pre>
<p>В этом случае массив будет разбит на блоки размером 4×2 и 4×2. Однако данный способ имеет ограничения на количество строк и столбцов в исходном массиве. Это может быть полезно при работе с заранее подготовленными данными или при необходимости поддержания точной структуры блока.</p>
<p>Разбиение массива на блоки может быть полезным в задачах, связанных с параллельными вычислениями, анализом данных в ограниченных пространствах или при оптимизации обработки больших массивов, что позволяет эффективно использовать память и ускорить вычисления.</p>
<h2>Применение itertools для разбиения последовательностей</h2>
<p>Функция <code>itertools.islice(iterable, start, stop, step)</code> позволяет избирательно извлекать элементы из последовательности, что идеально подходит для реализации разбиения на подмассивы. При помощи <code>islice()</code> можно взять срезы данных и организовать их в подмассивы, не создавая дополнительных структур данных.</p>
<p>Пример разбиения списка на части с помощью <code>islice</code>:</p>
<pre><code>from itertools import islice
def chunked(iterable, size):
it = iter(iterable)
return iter(lambda: list(islice(it, size)), [])
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9]
result = list(chunked(sequence, 3))
print(result)
</code></pre>
<p>Этот код разбивает последовательность <code>sequence</code> на подмассивы размером по 3 элемента. Функция <code>chunked()</code> использует итератор для извлечения элементов по очереди, пока не достигнут размер блока. Это позволяет избежать использования дополнительных циклов или сложных операций с индексами.</p>
<p>При необходимости можно использовать <code>itertools.cycle()</code>, чтобы разбивать последовательность в циклической манере, например, для создания цикличных подмассивов. Это полезно в случаях, когда нужно повторно использовать элементы последовательности.</p>
<p>Если необходимо разбить последовательность на подмассивы с разными размерами, можно комбинировать <code>itertools.islice()</code> с другими методами, такими как <code>enumerate()</code> и <code>filter()</code>, чтобы управлять размером каждого блока в процессе разбиения.</p>
<p>Использование <code>itertools</code> для разбиения данных упрощает код и улучшает производительность за счет эффективного использования итераторов, исключая создание временных коллекций. Это особенно важно при работе с большими объемами данных, где оптимизация памяти и времени имеет значение.</p>
<h2>Работа с NumPy: разбиение массивов на части</h2>
<p><img decoding=](/wp-content/images4/kak-razbit-massiv-na-podmassivi-python-a7l0drra.jpg)
Основной синтаксис функции numpy.split(ary, indices_or_sections, axis=0) позволяет указать массив для разбиения, количество частей или индексы, на которых должно происходить разбиение. Аргумент indices_or_sections может быть как числом, так и массивом индексов.
Пример использования:
import numpy as np
arr = np.arange(10)
np.split(arr, 5)
# Результат: [array([0, 1]), array([2, 3]), array([4, 5]), array([6, 7]), array([8, 9])] Если вы хотите разделить массив на части произвольной длины, используйте numpy.array_split(). В отличие от split(), эта функция не вызывает ошибку, если размер массива не делится на количество частей, а распределяет элементы наиболее равномерно.
Пример:
np.array_split(arr, 3)
# Результат: [array([0, 1, 2, 3]), array([4, 5, 6]), array([7, 8, 9])] Если необходимо работать с многомерными массивами, то можно указать ось, вдоль которой будет происходить разбиение, с помощью параметра axis. Например, для разбиения двумерного массива по строкам или столбцам:
arr_2d = np.arange(12).reshape(3, 4)
np.split(arr_2d, 2, axis=1)
# Результат: [array([[ 0, 1],
# [ 4, 5],
# [ 8, 9]]),
# array([[ 2, 3],
# [ 6, 7],
# [10, 11]])]При использовании функции numpy.split() важно помнить, что массив должен быть делим на части без остатка. В противном случае будет вызвана ошибка. Для более гибкого разбиения всегда используйте numpy.array_split().
Обработка ошибок при разбиении массивов произвольной длины

При разбиении массивов произвольной длины на подмассивы часто возникают ошибки, связанные с неверными индексами, типами данных и некорректными параметрами. Чтобы избежать таких ситуаций, следует учитывать несколько ключевых аспектов.
Первое, что необходимо проверить – корректность входных данных. Если в функцию передается массив с элементами разных типов, необходимо либо привести данные к одному типу, либо выбросить исключение. Например, для числовых массивов, если встречается строка или объект, можно использовать конструкцию try-except, чтобы перехватить ошибку приведения типов.
Также важным аспектом является проверка размера подмассива, который вы хотите создать. Если размер подмассива больше длины исходного массива, программа должна корректно обрабатывать этот случай, возвращая весь массив как один подмассив или выбрасывая ошибку с понятным сообщением. Если размер подмассива слишком мал, стоит предусмотреть проверку, чтобы избежать неполного разбиения данных.
Для работы с индексами следует внимательно следить за их границами. Использование отрицательных индексов или выход за пределы массива при разбиении на подмассивы может привести к ошибкам. Рекомендуется добавлять проверку на выход за пределы, чтобы исключить такие ошибки. Можно использовать встроенные методы Python, такие как len(), для определения допустимых индексов, или воспользоваться конструкциями с условиями, чтобы контролировать допустимые диапазоны.
Когда алгоритм делит массив на подмассивы с произвольным размером, важно учитывать, что последний подмассив может быть меньше остальных. Чтобы избежать создания пустых подмассивов, можно предварительно проверить, насколько делится длина исходного массива на выбранный размер подмассива. В случае, если остаток от деления не равен нулю, можно добавить последний неполный подмассив.
Необходимо предусмотреть обработку случаев, когда массив пуст. Попытка разделить пустой массив на подмассивы вызовет ошибку или пустой результат, в зависимости от реализации. Если задача требует наличия хотя бы одного подмассива, следует заранее проверять, что входной массив не пуст.
В случае, если функция возвращает множество подмассивов, можно использовать конструкции с генераторами и исключать ситуации с избыточными или пустыми подмассивами, создавая более эффективный и корректный код.