Работа с текстом в Python открывает множество возможностей, и одна из самых простых и полезных задач – это разделение строки на отдельные символы. Задача, на первый взгляд, может показаться тривиальной, но она имеет множество применений, от анализа данных до обработки пользовательских вводов. Разбивка строки на буквы – это фундаментальная операция, с которой сталкиваются разработчики в разных областях.
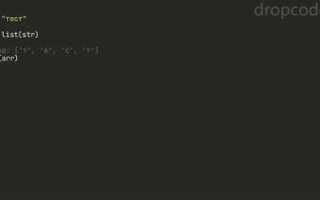
Чтобы разбить слово на буквы в Python, достаточно использовать стандартные возможности языка. Один из самых простых и эффективных способов – это использование метода list(), который преобразует строку в список символов. Такой подход позволяет не только получить доступ к каждому символу, но и эффективно работать с ними дальше. Например, если у вас есть слово «python», вызов list(«python») вернет [‘p’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’].
При этом стоит помнить, что строки в Python являются неизменяемыми объектами. Это значит, что операции, которые требуют изменения данных, такие как удаление или замена символов, могут потребовать дополнительных шагов. Однако для базовых задач разбивки строки на символы использование list() является наилучшим вариантом. В случае необходимости дальнейшей обработки отдельных символов можно использовать другие методы Python, такие как цикл for или списковые выражения.
Использование метода list() для разбиения строки

Чтобы разбить строку на буквы, достаточно передать строку в качестве аргумента метода list(). Например, строка "hello" будет преобразована в список ['h', 'e', 'l', 'l', 'o']. Это особенно полезно, когда необходимо работать с отдельными символами строки, например, при анализе текста или в задачах обработки данных.
word = "hello"
letters = list(word)
print(letters)
Рекомендации:
- Метод
list() делит строку по символам, включая пробелы, если они есть в строке. Например, строка "hello world" будет преобразована в список ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'].
- Этот метод работает только с объектами, поддерживающими итерируемость, поэтому он не применим, например, к числам без предварительного преобразования в строку.
- Для строк с пробелами и специальными символами, такими как знаки препинания,
list() будет учитывать их как отдельные элементы.
Использование list() – это быстрый и простой способ разбиения строки на символы, что делает его идеальным решением для задач, требующих такого рода манипуляций. В сочетании с другими методами обработки строк этот подход позволяет эффективно решать широкий круг задач в программировании.
Разбиение строки на символы через цикл for
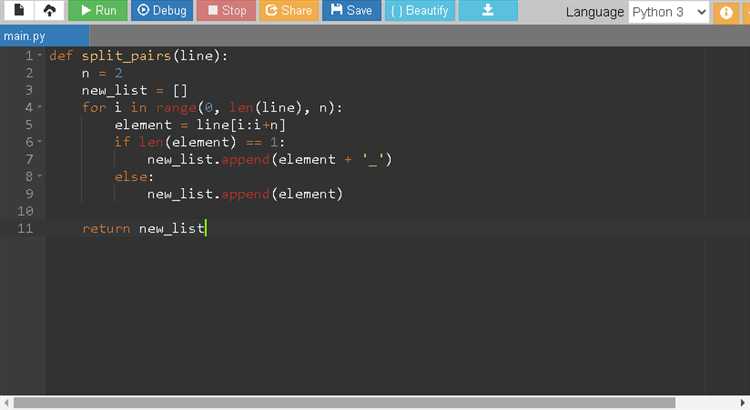
В Python для разбиения строки на отдельные символы можно использовать цикл for. Это один из самых простых и интуитивно понятных способов перебора каждого символа строки. Рассмотрим основные моменты, которые стоит учесть при использовании цикла for для данной задачи.
Когда мы перебираем строку с помощью цикла for, на каждой итерации цикла переменная, например, char, будет принимать значение одного символа строки. Это дает возможность манипулировать каждым символом отдельно, выполнять преобразования или фильтрацию.
# Пример разбиения строки на символы через цикл for
text = "Python"
for char in text:
print(char)
Этот код выведет:
P
y
t
h
o
n
При этом стоит помнить, что строка в Python является итерируемым объектом, поэтому цикл for будет перебирать все её символы без дополнительных преобразований.
Возможность использовать цикл для работы с символами строки позволяет легко применить дополнительные операции, такие как фильтрация или замена. Например, если нужно отфильтровать только гласные буквы из строки, можно сделать следующее:
text = "Python"
vowels = "aeiouAEIOU"
for char in text:
if char in vowels:
print(char)
Этот код выведет:
o
Такой подход позволяет эффективно работать с каждой буквой строки, выделяя или изменяя её в зависимости от поставленных задач.
Как применить метод split() для разделения по символам

Метод split() в Python предназначен для разделения строк на подстроки по определённому разделителю. Обычно его применяют для деления строки на слова или фрагменты, однако он не используется для разделения по символам. Несмотря на это, можно легко обойти это ограничение, если передать в метод разделитель, который не встречается в строке. В таком случае, строка будет разбита на отдельные символы.
Пример:
text = "Пример"
result = text.split("")
Как видно из примера, передача пустой строки "" в метод split() приводит к разделению исходной строки на отдельные символы. Это решение работает только с методами, поддерживающими разделение по символам, такими как split().
Однако важно учитывать, что при использовании этого метода результатом будет список, содержащий все символы строки как отдельные элементы. Такой подход можно использовать, если нужно быстро разделить строку на буквы для дальнейшей обработки каждого символа по отдельности.
Если задача состоит в том, чтобы избежать добавления пустых строк в список при обработке пустых символов или пробелов, следует дополнительно фильтровать результат:
text = "Пример текст"
result = [char for char in text if char != " "]
Этот способ помогает избежать пустых элементов в списке и эффективно работать с каждым символом.
Использование регулярных выражений для разбиения слова
Для разбиения слова на отдельные буквы с помощью Python можно эффективно использовать модуль re, который предоставляет функционал для работы с регулярными выражениями. Этот метод позволяет гибко настроить разделение, если требуется учитывать особенности символов или фильтровать определенные буквы.
Простой пример использования регулярного выражения для разбиения слова на отдельные символы выглядит так:
import re
word = "пример"
result = re.findall(r'.', word)
print(result)
Здесь re.findall() возвращает все символы строки, так как регулярное выражение r'.' соответствует любому символу, включая буквы, цифры и знаки препинания. Таким образом, слово "пример" будет разделено на список: ['п', 'р', 'и', 'м', 'е', 'р'].
Если нужно учесть только буквы и игнорировать другие символы, можно использовать регулярное выражение, которое ограничит выбор только буквами:
result = re.findall(r'[а-яА-Яa-zA-Z]', word)
print(result)
В этом случае регулярное выражение r'[а-яА-Яa-zA-Z]' гарантирует, что будут выбраны только символы кириллицы и латиницы. Это полезно, если в строке могут быть пробелы или другие символы, которые нужно игнорировать.
Для работы с более сложными случаями, например, с разбиением на буквы, учитывая только гласные или согласные, можно использовать дополнительную фильтрацию через регулярные выражения:
result = re.findall(r'[аеёиоуыэюяАЕЁИОУЫЭЮЯ]', word)
print(result)
Здесь регулярное выражение r'[аеёиоуыэюяАЕЁИОУЫЭЮЯ]' выберет только гласные буквы. Этот подход поможет фильтровать символы в зависимости от специфики задачи.
При использовании регулярных выражений для разбиения слова важно помнить о точности выражений, поскольку неудачно настроенное регулярное выражение может привести к ошибочному результату. Регулярные выражения – это мощный инструмент, который стоит использовать в случае, если разбиение требует более сложных условий, чем просто разделение по пробелам или символам.
Как избежать ошибок при разбиении на символы с помощью фильтрации

При разбиении строки на символы важно учитывать, что в тексте могут встречаться не только буквы, но и пробелы, цифры, знаки препинания или даже управляющие символы. Если не обработать эти случаи, можно получить неожиданные результаты. Фильтрация данных перед разбиением помогает избежать таких ошибок.
Для начала рассмотрим, как можно эффективно фильтровать символы перед разбиением строки:
- Использование регулярных выражений: Регулярные выражения позволяют точно выбирать нужные символы. Например, если нужно разделить строку только на буквы, можно использовать следующий фильтр:
re.findall(r'[a-zA-Z]', text). Это удалит все символы, не являющиеся буквами.
- Проверка на тип символов: При разбиении строки стоит убедиться, что каждый символ соответствует требуемому типу. Например, для выборки только букв можно воспользоваться функцией
isalpha(): [char for char in text if char.isalpha()].
- Удаление пробелов и других ненужных символов: Часто необходимо исключить пробелы и знаки препинания. Для этого достаточно использовать метод
replace() или регулярное выражение для удаления ненужных символов. Например: text.replace(" ", "").
Если строка содержит символы, которые могут вызывать ошибки при дальнейшей обработке (например, нелатинские буквы в строке, когда ожидается только латиница), стоит предварительно фильтровать такие символы и обрабатывать их отдельно.
Также важно не забывать про кодировку текста. Если строка содержит нестандартные символы (например, кириллицу в текстах на латинице), перед фильтрацией необходимо удостовериться в правильности кодировки текста, чтобы избежать ошибок преобразования символов.
Пример фильтрации строки, содержащей только латинские буквы:
import re
text = "Hello, World! 123"
filtered_text = ''.join(re.findall(r'[a-zA-Z]', text))
print(filtered_text)
Этот код удаляет все символы, кроме латинских букв, оставив в итоге "HelloWorld". Такой подход помогает избежать ненужных символов в результате разбиения строки.
Разбиение на буквы с учётом Unicode символов
При работе с текстами, содержащими символы за пределами стандартной латиницы, важно учитывать особенности кодировки Unicode. Проблема разбиения строк на буквы в таких случаях заключается в том, что многие символы могут состоять из нескольких байтов или представлять собой составные элементы, такие как эмодзи или диакритические знаки.
Для правильного разбиения строки на буквы в Python, можно использовать встроенные механизмы языка, которые поддерживают Unicode. Рассмотрим несколько подходов, чтобы обеспечить корректную обработку различных символов.
- Использование функции
list(): этот способ является простым и эффективным, поскольку Python 3 автоматически обрабатывает строки как последовательности символов Unicode.
text = "Привет, мир! 👋"
letters = list(text)
print(letters)
Этот код разбивает строку на отдельные символы, включая эмодзи и другие сложные символы, такие как кириллические буквы и знаки препинания.
- Использование модуля
unicodedata: для работы с символами Unicode, например, для получения нормализованных форм или разделения составных символов (диакритики) можно использовать модуль unicodedata.
import unicodedata
text = "ё"
normalized_text = unicodedata.normalize('NFKC', text)
letters = list(normalized_text)
print(letters)
В этом примере символ "ё" (с диакритическим знаком) будет разделён и нормализован, что позволяет работать с ним как с отдельной буквой "е" и диакритическим знаком.
- Использование регулярных выражений: для более сложных случаев, когда необходимо учитывать, например, объединённые символы или сочетания, можно использовать модуль
re.
import re
text = "на́пример"
letters = re.findall(r'\X', text)
print(letters)
Регулярное выражение \X позволяет находить Unicode символы, включая составные. Это особенно полезно, если строка содержит символы, состоящие из нескольких частей.
Таким образом, для корректного разбиения на буквы важно учитывать специфику работы с Unicode. В большинстве случаев использование list() является наилучшим выбором для строк на Python 3. Однако, если необходимо учитывать составные символы или работать с нормализацией, лучше прибегать к инструментам, таким как unicodedata или регулярные выражения.
Оптимизация разбиения строки для работы с большими объёмами данных
Для эффективного разбиения строк на буквы в Python при работе с большими объёмами данных следует учитывать несколько важных факторов, которые помогут ускорить процесс и снизить нагрузку на память.
Первое, что стоит помнить, это использование встроенных методов языка, таких как list() или str.split(). Они просты, но могут быть неэффективными при работе с большими данными. Преимущества list() очевидны: она быстро создает список символов. Однако, если строка очень велика, этот метод может создать значительную нагрузку на память из-за того, что Python хранит каждый символ в отдельной ячейке памяти.
В случае с большими объёмами данных эффективнее использовать генераторы. Они позволяют обходиться без создания полных списков, что снижает потребление памяти. Например, использование генератора для поочередного извлечения символов из строки позволяет обрабатывать её по частям, без необходимости хранить всю строку в памяти одновременно.
Пример использования генератора:
def split_string_large_data(string):
for char in string:
yield char
Этот подход не только снижает использование памяти, но и позволяет работать с потоками данных, что особенно важно для обработки файлов больших размеров или данных из сети.
Ещё одной оптимизацией является использование метода map(), который может быть быстрее при определенных условиях, особенно если вы заранее знаете, что операция разбиения будет однотипной и не потребует сложных проверок. Это позволяет использовать более эффективные механизмы работы с памятью и обработку каждого символа с минимальными затратами.
Для обработки строк в реальном времени, когда нужно быстро получать доступ к отдельным символам, полезно использовать структуру данных типа deque из модуля collections. Она оптимизирована для быстрых вставок и удалений элементов с обеих сторон, что может быть полезно в ситуациях, когда строка меняется динамически и требуется эффективный доступ к её частям.
Кроме того, стоит учитывать необходимость работы с кодировками. При разбиении строк на символы важно помнить о том, как строки представлены в памяти. Например, строки в кодировке UTF-8 могут занимать переменное количество байтов на символ, что делает важным правильное обращение с такими строками, чтобы избежать ошибок при их разбиении.
Таким образом, при работе с большими объёмами данных важно выбирать такие методы и структуры данных, которые оптимизируют использование памяти и времени выполнения. Это позволит эффективно обрабатывать большие строки, избегая переполнения памяти и излишних вычислительных затрат.
Вопрос-ответ:
Как разбить слово на буквы в Python?
Для того чтобы разбить строку на отдельные буквы в Python, можно использовать функцию `list()`. Например, если у вас есть строка "hello", вы можете применить `list('hello')`, и это вернет список: `['h', 'e', 'l', 'l', 'o'].
Как правильно использовать функцию list() для разбивки строки на буквы?
Функция `list()` в Python преобразует любой итерируемый объект в список. Для строк это означает, что каждый символ строки будет отдельным элементом в новом списке. Например, если у вас есть строка "привет", то `list("привет")` вернет список `['п', 'р', 'и', 'в', 'е', 'т']`. Это самый быстрый и простой способ разбить строку на отдельные символы.