Разделение элементов списка – это базовая, но часто необходимая операция в Python. В зависимости от задачи, элементы могут быть разделены по индексам, значениям или с применением условий. Например, чтобы разбить список на части фиксированной длины, можно использовать генераторы списков и срезы: [lst[i:i+n] for i in range(0, len(lst), n)]. Такой подход удобен, когда нужно обработать данные пакетами.
Если требуется разделить список по значению, например, на подсписки, разделённые определённым элементом, используется буфер и цикл. Пример: для списка [1, 2, 0, 3, 4, 0, 5] и разделителя 0 логика будет заключаться в накоплении элементов до появления разделителя и последующем сохранении накопленного в отдельный подсписок.
Списки можно также разделять по условию, используя функцию groupby из модуля itertools, особенно когда нужно сгруппировать элементы по какому-то признаку. Например, при фильтрации логов по типу события. Однако groupby работает только с предварительно отсортированными данными, и это нужно учитывать при применении.
Если нужно разделить список на несколько частей случайным образом или равномерно по количеству, можно использовать random.shuffle совместно с срезами или модуль numpy для работы с массивами. Для больших объёмов данных это позволит избежать лишних циклов и ускорить выполнение за счёт оптимизированных операций.
Как разделить строку внутри списка по разделителю
Если список содержит строки, которые нужно разбить по разделителю, используется метод split(). Например, список data = ['a,b,c', 'd,e,f'] можно преобразовать так:
result = [item.split(',') for item in data]
Результат: [['a', 'b', 'c'], ['d', 'e', 'f']]. Метод split(',') разбивает строку по запятой. Список на выходе – это список списков, где каждая строка разбита на элементы.
Если нужно объединить все полученные подсписки в один список, используют itertools.chain:
from itertools import chain
flattened = list(chain.from_iterable(item.split(',') for item in data))
Результат: ['a', 'b', 'c', 'd', 'e', 'f'].
Если строки содержат разные разделители, можно использовать re.split() из модуля re:
import re
data = ['a,b;c', 'd:e,f']
result = [re.split(r'[,:;]', item) for item in data]
Результат: [['a', 'b', 'c'], ['d', 'e', 'f']]. Регулярное выражение [,:;] указывает на любой из перечисленных символов-разделителей.
Для удаления пробелов после разделения применяют strip():
cleaned = [[x.strip() for x in re.split(r'[,:;]', item)] for item in data]
Это устраняет лишние пробелы в элементах, если они есть после разделителей.
Как разбить список на подсписки фиксированной длины
Для разбиения списка на подсписки одинаковой длины используют срезы или функции из стандартной библиотеки. Пусть задан список data = [1, 2, 3, 4, 5, 6, 7, 8, 9] и требуется разбить его на подсписки длиной 3 элемента.
Через генератор списков:
chunk_size = 3
chunks = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]
Если длина исходного списка не кратна размеру подсписка, последний будет короче. Для заполнения недостающих значений используют itertools.zip_longest:
from itertools import zip_longest
def split_fixed_length(iterable, size, fillvalue=None):
args = [iter(iterable)] * size
return list(zip_longest(*args, fillvalue=fillvalue))
chunks = split_fixed_length(data, 3)
Этот метод возвращает список кортежей, где все подсписки одинаковой длины. Пустые места заполняются значением по умолчанию, которое задаётся аргументом fillvalue.
Для получения списков вместо кортежей можно добавить преобразование:
[list(group) for group in zip_longest(*args, fillvalue=fillvalue)]
При работе с большими объёмами данных предпочтительнее использовать генераторы и итераторы, чтобы избежать избыточного потребления памяти.
Как разделить список по значению элемента

Если требуется разбить список на подсписки при встрече определённого значения, используют простой цикл с накоплением. Например, разделим список по элементу `’x’`:
data = [1, 2, 'x', 3, 4, 'x', 5]
result = []
chunk = []
for item in data:
if item == 'x':
result.append(chunk)
chunk = []
else:
chunk.append(item)
if chunk:
result.append(chunk)
print(result) # [[1, 2], [3, 4], [5]]Такой подход сохраняет порядок и исключает элементы-разделители из результата. Если необходимо сохранить разделители, их можно добавлять в подсписки отдельно.
Для числовых значений условие заменяется, например, на item == 0. При необходимости делить по нескольким значениям:
splitters = {'x', 'y'}
result = []
chunk = []
for item in data:
if item in splitters:
result.append(chunk)
chunk = []
else:
chunk.append(item)
if chunk:
result.append(chunk)Если данные приходят в виде строки, предварительно используют split() и затем обрабатывают список аналогичным способом. Разбиение по значению не входит в стандартные функции Python, поэтому предпочтительнее использовать явный цикл. Это обеспечивает контроль над обработкой краевых случаев: пустые подсписки, наличие разделителя в начале или конце.
Как разделить список по условию с использованием итераторов

Для разделения списка по условию в Python можно использовать модуль itertools. В частности, метод itertools.groupby() позволяет эффективно сгруппировать элементы, удовлетворяющие одинаковым условиям.
itertools.groupby() принимает два аргумента: сам список и функцию, которая будет возвращать ключ, по которому происходит разделение. Эта функция должна преобразовывать элементы в такие значения, по которым можно выполнить группировку.
Пример использования:
from itertools import groupby
# Пример списка
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
# Условие для группировки: четные и нечетные числа
def is_even(num):
return num % 2 == 0
# Разделяем список по условию
grouped = groupby(numbers, key=is_even)
for key, group in grouped:
print(f"Группа: {key}, элементы: {list(group)}")
Этот код разделяет числа на две группы: четные и нечетные. itertools.groupby() сначала сортирует элементы по ключу, а затем группирует их.
Важно: Метод groupby() работает только с уже отсортированным списком. Если список не отсортирован, сначала нужно его отсортировать.
Для эффективного разделения списка по сложным условиям можно комбинировать groupby() с другими функциями и итераторами из модуля itertools, такими как chain() и filter(), что позволяет гибко управлять разделением элементов на группы.
Как использовать регулярные выражения для разделения элементов списка

Регулярные выражения позволяют гибко разделять строки по различным шаблонам. Для работы с ними в Python используется модуль re. При помощи функции re.split() можно разделить строку на элементы списка, основываясь на заданном регулярном выражении.
Пример: если у нас есть строка, содержащая элементы, разделённые пробелами и запятыми, и нам нужно разделить её на список, то регулярное выражение будет выглядеть так:
import re
string = "яблоко, банан, апельсин, груша"
result = re.split(r'\s*,\s*', string)
print(result)В этом примере регулярное выражение \s*,\s* означает: «любой пробельный символ перед и после запятой». Это позволяет корректно разделить строку на элементы, игнорируя пробелы после запятой.
Если нужно разделить строку по нескольким разделителям, регулярные выражения становятся особенно полезными. Например, если элементы разделяются и пробелами, и точками с запятой, можно использовать выражение r'[\s;]+', которое охватывает оба типа разделителей.
string = "яблоко банан; апельсин, груша"
result = re.split(r'[\s,;]+', string)
print(result)Этот код разобьёт строку по пробелам, запятым и точкам с запятой, возвращая корректный список элементов.
Регулярные выражения также позволяют учитывать более сложные случаи. Например, если элементы списка имеют разную длину или содержат спецсимволы, регулярные выражения можно настроить на точное соответствие. Важно помнить, что при использовании re.split() результат будет списком строк, которые соответствуют найденным фрагментам.
Как разделить список на группы с сохранением порядка
Чтобы разделить список на группы в Python, можно использовать несколько подходов в зависимости от задачи. Ниже рассмотрены способы, которые помогут сохранить порядок элементов в исходном списке.
1. Использование генераторов и срезов
Один из самых простых способов – это воспользоваться генератором с использованием срезов. Это подходит, если нужно разделить список на равные части.
def split_list(lst, group_size):
return [lst[i:i + group_size] for i in range(0, len(lst), group_size)]
Пример:
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
result = split_list(my_list, 3)
print(result) # [[1, 2, 3], [4, 5, 6], [7, 8]]
Здесь список делится на группы по три элемента. Если размер группы не делит длину списка нацело, то последняя группа может содержать меньше элементов.
2. Использование библиотеки itertools
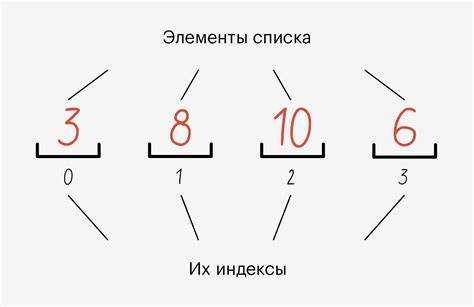
Для более гибкой работы с группировками полезно использовать модуль itertools. Метод islice позволяет удобно разделить список на части.
from itertools import islice
def split_list(lst, group_size):
return [list(islice(lst, i, i + group_size)) for i in range(0, len(lst), group_size)]
Этот метод также сохраняет порядок элементов и позволяет легко управлять размером групп.
3. Разбиение с использованием numpy
Если задача стоит в том, чтобы работать с числовыми данными и использовать возможности библиотеки numpy, можно применить метод array_split.
import numpy as np
def split_list(lst, group_size):
return np.array_split(lst, group_size)
Этот метод делит список на примерно равные части, но последняя группа может содержать меньше элементов, если длина списка не делится нацело на размер группы.
4. Использование стандартных циклов
Можно разделить список вручную, используя циклы. Этот способ подходит для гибкости, например, если нужно учитывать дополнительные условия для группировки.
def split_list(lst, group_size):
groups = []
for i in range(0, len(lst), group_size):
groups.append(lst[i:i + group_size])
return groups
Этот код выполняет разделение списка на группы с нужным размером, при этом порядок элементов остаётся неизменным.
5. Разделение списка на группы по условиям
Если элементы нужно разделить по какому-то условию (например, чётные и нечётные числа), можно использовать фильтрацию.
def split_by_condition(lst, condition):
true_group = [x for x in lst if condition(x)]
false_group = [x for x in lst if not condition(x)]
return true_group, false_group
Пример с разделением списка на чётные и нечётные числа:
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
even, odd = split_by_condition(my_list, lambda x: x % 2 == 0)
print(even) # [2, 4, 6, 8]
print(odd) # [1, 3, 5, 7]
Этот метод позволяет сохранять порядок, так как разделение выполняется с использованием последовательных проверок условий.
Вопрос-ответ:
Как разделить элементы списка в Python на несколько частей?
Для разделения списка на несколько частей можно использовать цикл или специальные методы, такие как `numpy.array_split()` или срезы. Например, если нужно разделить список на несколько равных частей, можно воспользоваться выражением `list[start:end]`. Если же количество частей заранее неизвестно, можно использовать метод `numpy.array_split()`, который автоматически распределяет элементы по частям.
Как разделить список на два подсписка в Python?
Чтобы разделить список на два подсписка, можно использовать срезы. Например, если нужно разделить список пополам, можно сделать это так: `list1 = my_list[:len(my_list)//2]` и `list2 = my_list[len(my_list)//2:]`. Это обеспечит, что элементы будут равномерно распределены между двумя новыми списками.